1. 项目概述(约 300 字)
在 UGC 平台、社交媒体、评论区、直播弹幕等场景里,违规内容往往不是“纯文本”或“纯图片”单独出现,而是多模态混合:图片里包含敏感元素,配文刻意用谐音/拆字绕过关键词;或者文字看似正常,但配图引导违规;甚至图文组合后的语义才构成攻击或诈骗。只做单模态审核会出现两类常见问题:漏检(只看文字看不出图片违规)与 误伤(只看图片难以判断语境)。
多模态内容审核系统的目标,是在 低延迟、高并发、可解释、可复核 的工程约束下,对文本、图像分别打分,再做融合判断,最终输出:是否拦截/放行、违规类型、置信度、命中的规则/证据,并把“疑似但不确定”的样本流转到人工复核,从而形成“数据—标注—训练—上线—监控—迭代”的闭环。
2. 技术架构(含 Mermaid 架构图)
下面的架构把审核拆成三条线:文本审核、图像审核、多模态融合,并在决策层加入 规则引擎 与 人工复核。在线服务采用 FastAPI 作为 API 层,Celery + Redis 做异步批处理与队列削峰。
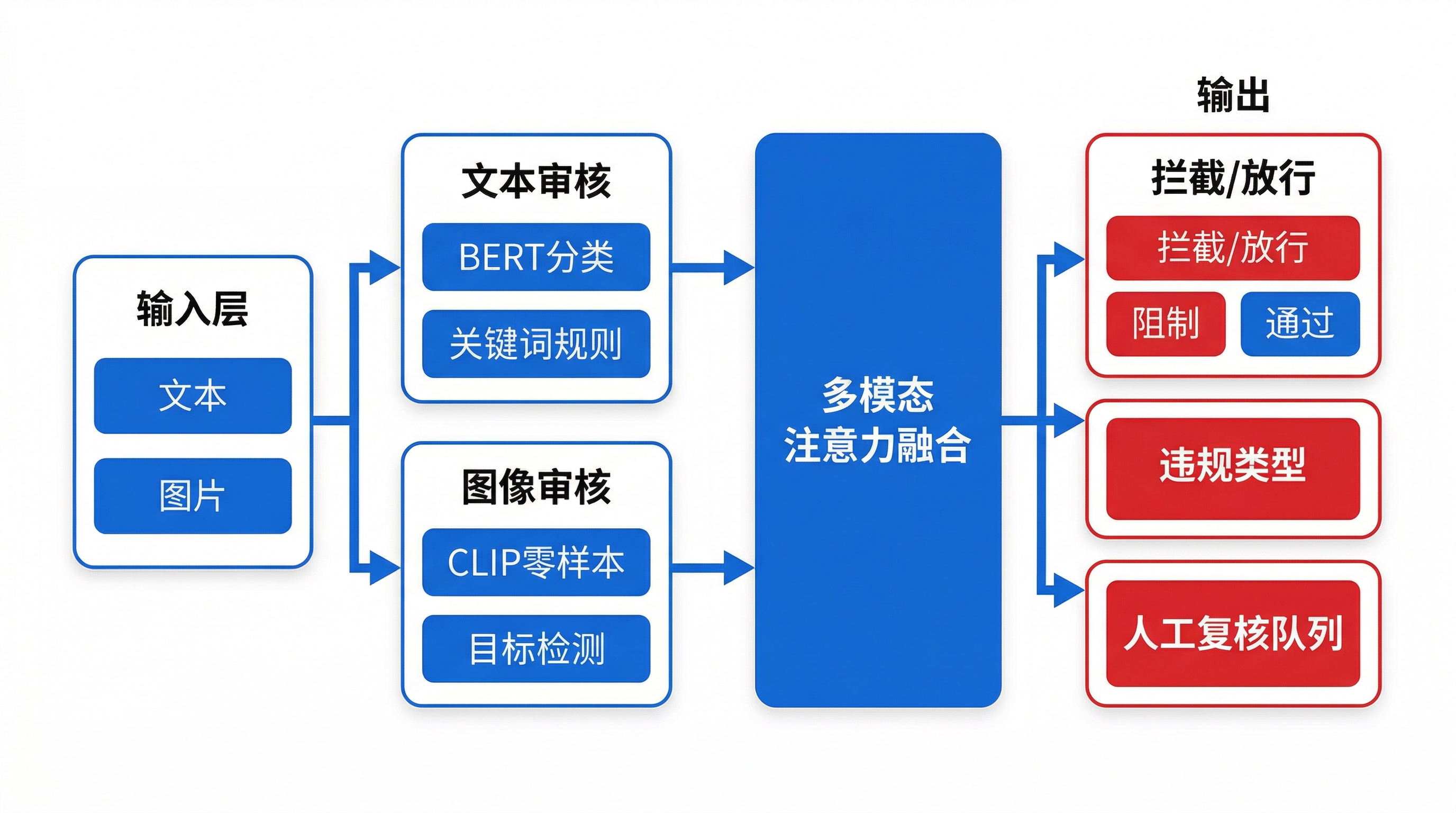
Mermaid 架构图
flowchart TB
subgraph Client[业务调用方]
A[UGC 发布/评论/私信/动态] -->|HTTP| API[FastAPI 审核网关]
end
subgraph Online[在线审核服务]
API --> PRE[预处理
- 文本清洗
- 图片解码
- 采样/缩放]
PRE --> TR[文本模型推理
Transformers 中文分类]
PRE --> IR[图像模型推理
CLIP 零样本分类]
TR --> FUSE[多模态融合
Attention Fusion]
IR --> FUSE
PRE --> RULE[规则引擎
关键词/正则/黑白名单]
RULE --> DEC[决策器
多层阈值 + 解释]
FUSE --> DEC
DEC --> OUT[输出
- 放行/拦截/复核
- 违规类型
- 置信度
- 证据]
end
subgraph Async[异步与复核]
DEC -->|疑似| Q[(Redis 队列)]
Q --> C[Celery 批处理任务
重推理/聚合]
C --> RUI[人工复核台
(简化示例)]
RUI --> FB[标注/申诉反馈]
FB --> DS[(训练数据集)]
DS --> TRAIN[离线训练/迭代]
TRAIN --> TR
end
3. 详细步骤(每步 400–600 字 + 完整代码)
步骤 1:文本内容审核(基于 transformers 微调中文文本分类模型)
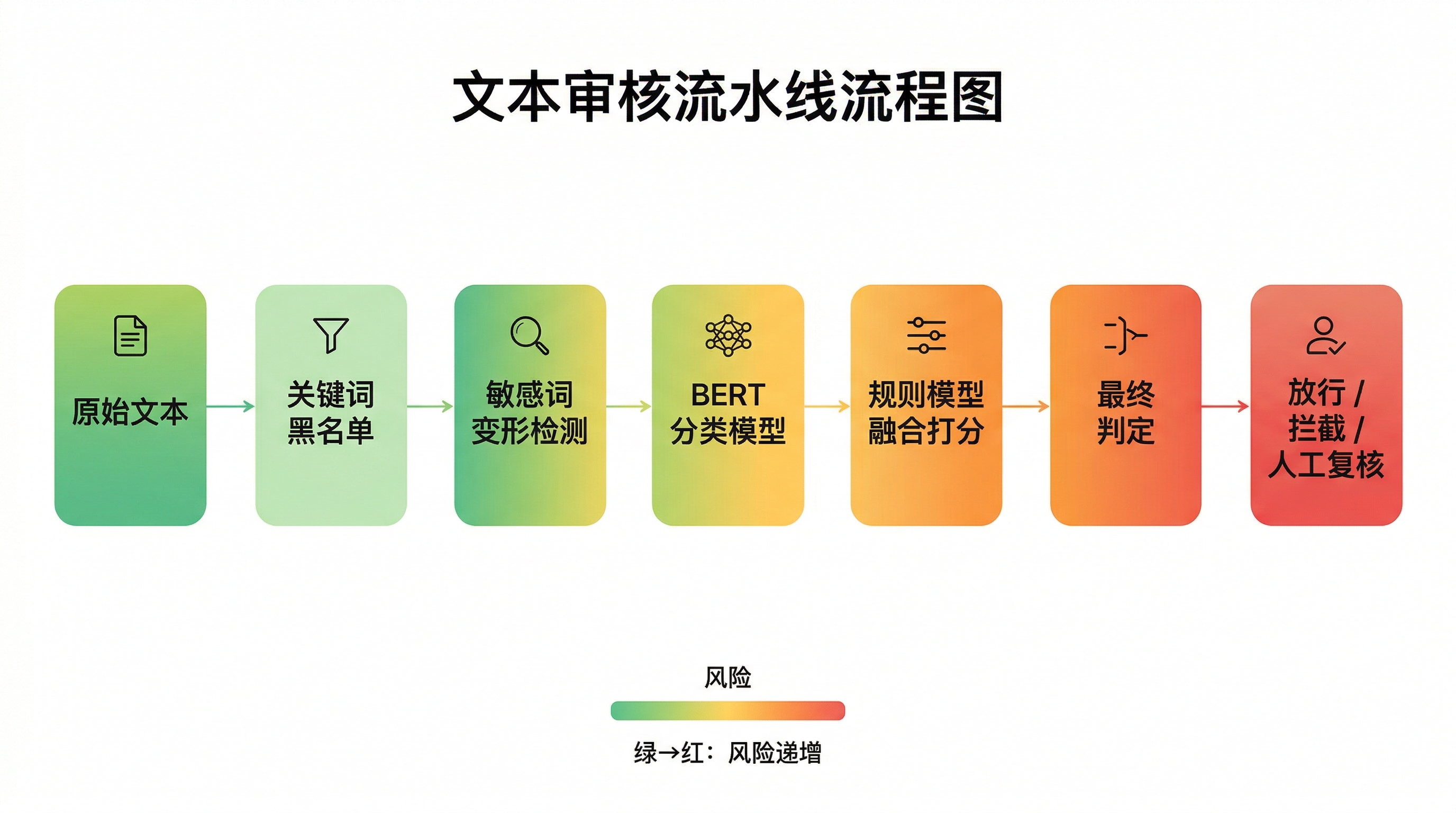
文本审核的核心任务是把输入文本映射到一组业务违规标签(如:辱骂、色情引导、诈骗、涉政、广告引流等),并给出置信度。实际业务里,文本会充满噪声:表情、@、URL、拆字、谐音、空格插入、同形字。工程上建议分三层:清洗归一化(统一空白、常见变体映射、URL/手机号脱敏)、轻规则快速拦截(强命中直接拦截,减少模型负载)、模型分类(对“难例”与“语境相关”内容给出概率)。
模型层通常选择中文预训练模型(如 bert-base-chinese 或 RoBERTa 变体)并微调成多分类器。训练时用 Trainer/自定义循环均可;在线推理时要注意:1)固定 tokenizer 与 label 映射;2)使用 torch.inference_mode();3)将阈值与策略配置化(不同业务线阈值不同);4)输出可解释信息:top-k 类别、概率、触发的关键片段(简化可用高亮/规则证据;更高级可用 attention/梯度方法)。
代码:训练(可运行最小示例)
说明:真实业务需要更大数据与更严谨评估。这里用“示例 CSV”演示完整训练流程与导出推理所需产物。
from __future__ import annotations
import os
from dataclasses import dataclass
from typing import Dict, List, Tuple
import torch
from torch import nn
from torch.utils.data import Dataset
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
)
LABEL2ID: Dict[str, int] = {
"normal": 0,
"abuse": 1,
"spam": 2,
"fraud": 3,
}
ID2LABEL: Dict[int, str] = {v: k for k, v in LABEL2ID.items()}
@dataclass
class TextSample:
text: str
label: int
class CSVDemoDataset(Dataset):
"""一个最小可运行 Dataset。
期望输入数据格式(示例):
- demo_text_train.csv: text,label
- label 为字符串,如 normal/abuse/spam/fraud
"""
def __init__(self, csv_path: str, tokenizer: AutoTokenizer, max_length: int = 128) -> None:
self.samples: List[TextSample] = []
self.tokenizer = tokenizer
self.max_length = max_length
with open(csv_path, "r", encoding="utf-8") as f:
header = f.readline()
if "text" not in header or "label" not in header:
raise ValueError("CSV header 必须包含 text,label")
for line in f:
line = line.strip()
if not line:
continue
# 简化解析:假设 text 中不包含逗号。真实项目建议用 csv 标准库。
text, label_str = line.split(",", 1)
label_str = label_str.strip()
if label_str not in LABEL2ID:
raise ValueError(f"未知 label: {label_str}")
self.samples.append(TextSample(text=text, label=LABEL2ID[label_str]))
def __len__(self) -> int:
return len(self.samples)
def __getitem__(self, idx: int) -> Dict[str, torch.Tensor]:
s = self.samples[idx]
encoded = self.tokenizer(
s.text,
truncation=True,
max_length=self.max_length,
padding="max_length",
return_tensors="pt",
)
item = {k: v.squeeze(0) for k, v in encoded.items()}
item["labels"] = torch.tensor(s.label, dtype=torch.long)
return item
def train_text_classifier(
train_csv: str,
eval_csv: str,
out_dir: str = "./text_model",
base_model: str = "bert-base-chinese",
num_epochs: int = 1,
) -> None:
os.makedirs(out_dir, exist_ok=True)
tokenizer = AutoTokenizer.from_pretrained(base_model)
train_ds = CSVDemoDataset(train_csv, tokenizer)
eval_ds = CSVDemoDataset(eval_csv, tokenizer)
model = AutoModelForSequenceClassification.from_pretrained(
base_model,
num_labels=len(LABEL2ID),
id2label=ID2LABEL,
label2id=LABEL2ID,
)
args = TrainingArguments(
output_dir=out_dir,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
learning_rate=2e-5,
num_train_epochs=num_epochs,
evaluation_strategy="steps",
eval_steps=50,
save_steps=50,
logging_steps=10,
fp16=torch.cuda.is_available(),
report_to=[], # 关闭 wandb 等
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_ds,
eval_dataset=eval_ds,
)
trainer.train()
# 保存 tokenizer + 模型(线上推理直接加载该目录)
trainer.save_model(out_dir)
tokenizer.save_pretrained(out_dir)
if __name__ == "__main__":
# 你需要准备 demo_text_train.csv / demo_text_eval.csv 才能运行
# 示例:
# text,label
# 你好呀,normal
# 你是傻子,abuse
train_text_classifier(
train_csv="./demo_text_train.csv",
eval_csv="./demo_text_eval.csv",
out_dir="./text_model",
num_epochs=1,
)
代码:在线推理(含类型标注与中文注释)
from __future__ import annotations
from dataclasses import dataclass
from typing import Dict, List, Tuple
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
@dataclass(frozen=True)
class TextModerationResult:
label: str
score: float
topk: List[Tuple[str, float]]
class TextModerator:
def __init__(self, model_dir: str, device: str | None = None) -> None:
self.tokenizer = AutoTokenizer.from_pretrained(model_dir)
self.model = AutoModelForSequenceClassification.from_pretrained(model_dir)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = device
self.model.to(self.device)
self.model.eval()
def predict(self, text: str, top_k: int = 3) -> TextModerationResult:
encoded = self.tokenizer(
text,
truncation=True,
max_length=128,
padding=True,
return_tensors="pt",
)
encoded = {k: v.to(self.device) for k, v in encoded.items()}
with torch.inference_mode():
logits = self.model(**encoded).logits
probs = torch.softmax(logits, dim=-1).squeeze(0)
# 取 top-k
topk = torch.topk(probs, k=min(top_k, probs.numel()))
id2label: Dict[int, str] = self.model.config.id2label
topk_list: List[Tuple[str, float]] = [
(id2label[int(i)], float(p)) for i, p in zip(topk.indices, topk.values)
]
best_label, best_score = topk_list[0]
return TextModerationResult(label=best_label, score=best_score, topk=topk_list)
步骤 2:图像内容审核(使用 CLIP 做零样本分类,识别违规图片类型)
图像审核在内容平台中非常关键:违规图片可能包含色情、暴力血腥、仇恨符号、涉政敏感、诈骗二维码、未成年人风险等。传统做法是训练一个多分类 CNN/ViT,但会面临两个现实问题:标签体系变化快(今天需要“擦边”,明天需要“低俗穿着”)、数据冷启动难(新违规类型缺少样本)。
CLIP 的“图文对齐”能力提供了零样本分类的捷径:我们把业务标签写成自然语言提示词(prompt),例如“这是一张暴力血腥图片”“这是一张色情图片”“这是一张正常的生活照”,让模型在图像特征与文本特征空间里做相似度匹配。这样做的优点是上线快、扩展快;缺点是需要精心设计 prompt,并通过少量已标注样本校准阈值,避免因风格、动漫、艺术作品导致误伤。
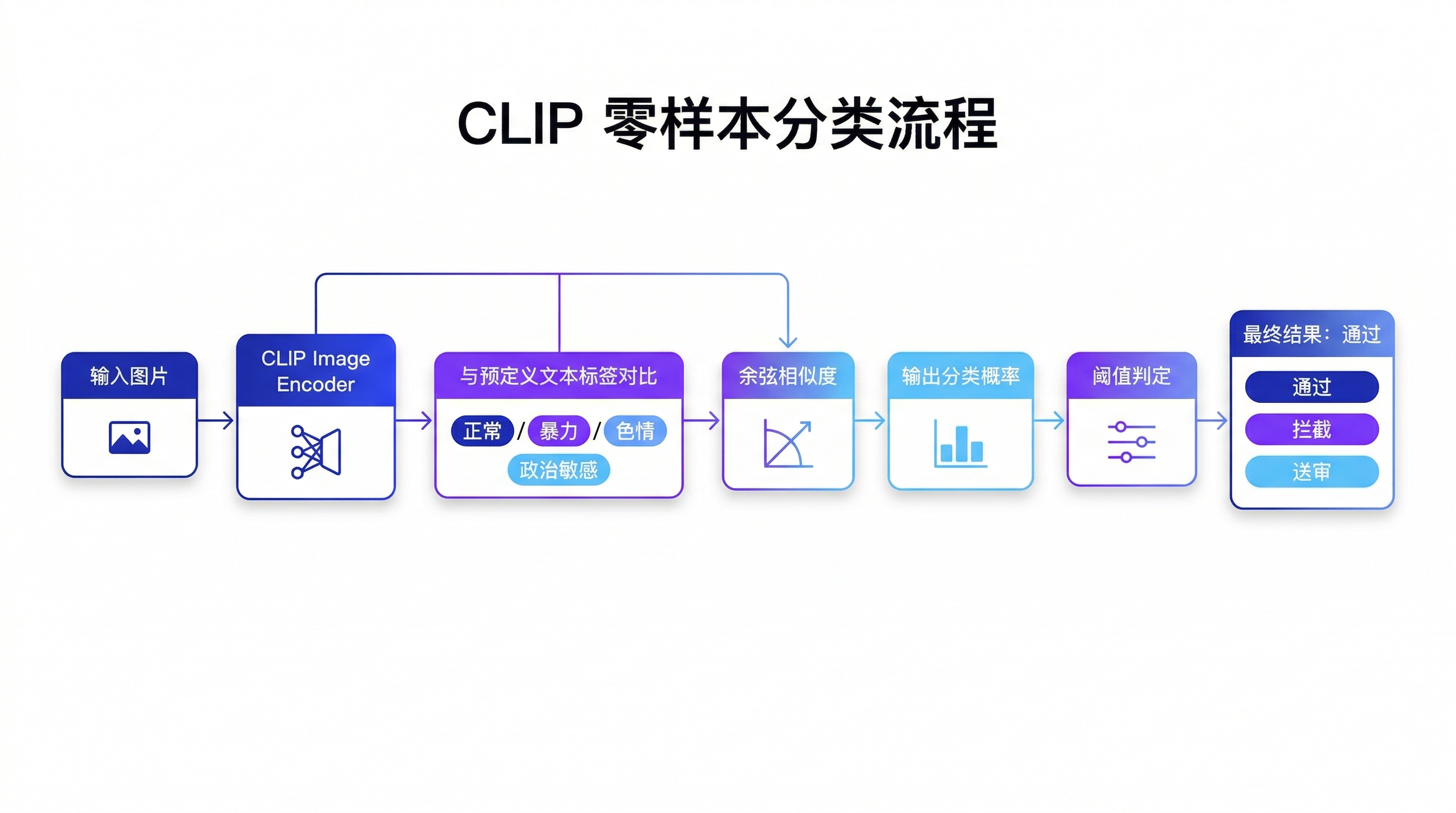
下面用 transformers 的 CLIPModel 演示完整推理:读取图片(PIL)、构造标签 prompts、计算相似度并输出 top-k。你可以把“违规类型集合”做成可配置文件,实时热更新。
代码:CLIP 零样本分类(可运行)
from __future__ import annotations
from dataclasses import dataclass
from typing import List, Tuple
import torch
from PIL import Image
from transformers import CLIPModel, CLIPProcessor
@dataclass(frozen=True)
class ImageModerationResult:
label: str
score: float
topk: List[Tuple[str, float]]
class CLIPZeroShotModerator:
"""用 CLIP 做零样本图像审核。
说明:
- 这里使用 openai/clip-vit-base-patch32(可替换更强模型)
- label_prompts 用自然语言描述,实践中要做 A/B 与阈值校准
"""
def __init__(
self,
device: str | None = None,
model_name: str = "openai/clip-vit-base-patch32",
) -> None:
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = device
self.model = CLIPModel.from_pretrained(model_name).to(self.device)
self.processor = CLIPProcessor.from_pretrained(model_name)
self.model.eval()
def predict(
self,
image: Image.Image,
label_prompts: List[str],
top_k: int = 3,
) -> ImageModerationResult:
inputs = self.processor(
text=label_prompts,
images=image,
return_tensors="pt",
padding=True,
)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.inference_mode():
outputs = self.model(**inputs)
# logits_per_image: [1, num_labels]
logits = outputs.logits_per_image.squeeze(0)
probs = torch.softmax(logits, dim=-1)
topk = torch.topk(probs, k=min(top_k, probs.numel()))
topk_list = [(label_prompts[int(i)], float(p)) for i, p in zip(topk.indices, topk.values)]
best_label, best_score = topk_list[0]
return ImageModerationResult(label=best_label, score=best_score, topk=topk_list)
if __name__ == "__main__":
moderator = CLIPZeroShotModerator()
img = Image.open("./demo.jpg").convert("RGB")
prompts = [
"这是一张正常的生活照片",
"这是一张色情低俗图片",
"这是一张暴力血腥图片",
"这是一张包含仇恨符号的图片",
"这是一张诈骗引流海报",
]
result = moderator.predict(img, prompts)
print(result)
步骤 3:多模态特征融合(文本特征 + 图像特征的注意力融合机制)
当文本模型与图像模型都给出各自判断后,最关键的问题变成:如何融合。简单做法是规则式“取最大风险”或加权平均;但在多模态协同的违规中,“文本提供语境、图像提供证据”,两者互相补充,融合策略直接影响漏检与误伤。
一种可解释且工程友好的方式是 注意力融合(Attention Fusion):把文本向量 与图像向量 视作两种 token,让模型学习在不同任务下对它们分配权重。一个最小形式:
[ \alpha = \mathrm{softmax}(\mathbf{W}[\mathbf{t};\mathbf{v}] + \mathbf{b}) \in \mathbb{R}^{2} ]
其中 表示“文本贡献权重”, 表示“图像贡献权重”。融合向量:
[ \mathbf{h} = \alpha_0\mathbf{t} + \alpha_1\mathbf{v} ]
再接一个分类器输出风险概率:
[ \hat{\mathbf{y}}=\mathrm{softmax}(\mathbf{W}_o\mathbf{h}+\mathbf{b}_o) ]
在真实项目里,你会用更复杂的 cross-attention/多层 Transformer,但对于学习案例,下面这段代码足以体现“注意力权重可解释、可训练、易部署”。
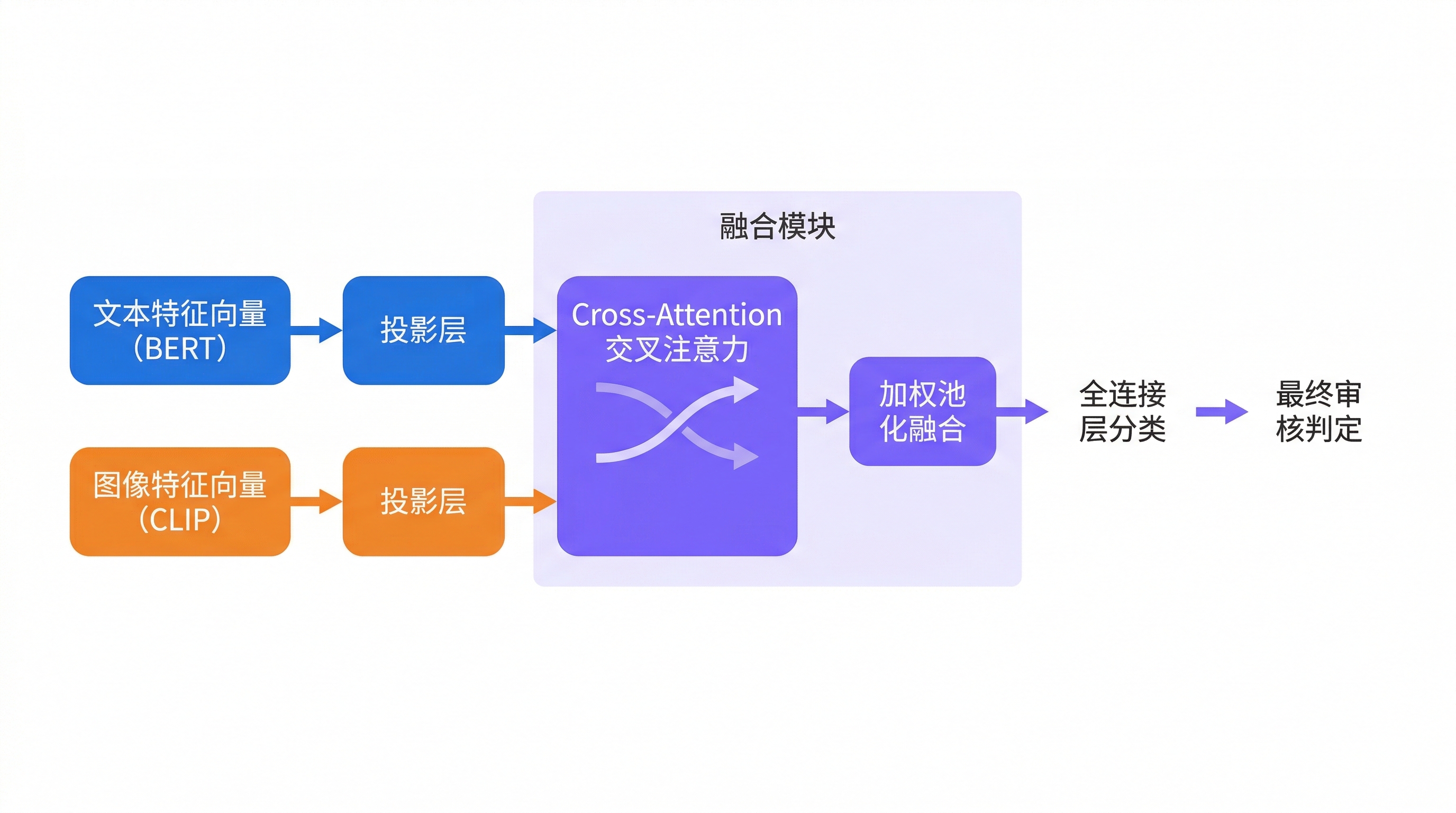
代码:注意力融合模块(可运行、可训练)
from __future__ import annotations
from dataclasses import dataclass
from typing import Tuple
import torch
from torch import nn
@dataclass(frozen=True)
class FusionOutput:
logits: torch.Tensor
attn_weights: torch.Tensor # shape: [batch, 2]
class AttentionFusion(nn.Module):
"""最小注意力融合:对文本与图像两个向量分配权重。
输入:
- text_emb: [B, D]
- image_emb: [B, D]
输出:
- logits: [B, C]
- attn_weights: [B, 2] (分别对应 text/image)
"""
def __init__(self, dim: int, num_classes: int) -> None:
super().__init__()
self.gate = nn.Linear(dim * 2, 2)
self.classifier = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes),
)
def forward(self, text_emb: torch.Tensor, image_emb: torch.Tensor) -> FusionOutput:
if text_emb.shape != image_emb.shape:
raise ValueError("text_emb 与 image_emb 的 shape 必须一致")
x = torch.cat([text_emb, image_emb], dim=-1) # [B, 2D]
attn_logits = self.gate(x) # [B, 2]
attn = torch.softmax(attn_logits, dim=-1) # [B, 2]
# 将两个向量按权重加权求和
h = attn[:, 0:1] * text_emb + attn[:, 1:2] * image_emb
logits = self.classifier(h)
return FusionOutput(logits=logits, attn_weights=attn)
if __name__ == "__main__":
torch.manual_seed(7)
B, D, C = 4, 512, 4
model = AttentionFusion(dim=D, num_classes=C)
text_emb = torch.randn(B, D)
image_emb = torch.randn(B, D)
out = model(text_emb, image_emb)
print("logits shape:", out.logits.shape)
print("attn:", out.attn_weights)
学习提示:
attn_weights可以直接用于解释:某条样本更依赖文本还是图像。如果发现某类误判经常“图像权重过高”,你就可以回到 prompt、图像预处理或阈值校准去调整。
步骤 4:规则引擎与模型协同(关键词 + 正则 + 模型打分的多层过滤)
仅靠模型往往不够:一方面,模型对“强规则”问题(如明确的违禁词、特定诈骗模板)不如规则稳定;另一方面,模型会有概率波动、对新型绕过不敏感。工程上最常见的方案是 规则先行 + 模型兜底 或 规则与模型并联,统一决策器融合。
在学习案例里,我们用一个轻量规则引擎:
- 关键词:命中直接加分或直接拦截(强命中);
- 正则:识别手机号/群号/引流话术/网址变体;
- 黑白名单:可信账号/敏感账号的差异化阈值;
- 模型分数:文本模型/图像模型/融合模型输出概率;
- 多层过滤:先快速拦截明显违规,再把剩余样本交给模型细分,最后对灰度样本进入人工复核。
最终风险分可用简单可解释的形式:
[ \text{Risk}=\lambda_r\cdot\text{RuleScore}+\lambda_t\cdot p_t+\lambda_i\cdot p_i+\lambda_f\cdot p_f ]
其中 分别代表文本、图像、融合模型对“违规”类的置信度(可按业务定义为某一类或多类加总)。
代码:规则引擎(可运行、带类型标注)
from __future__ import annotations
import re
from dataclasses import dataclass
from typing import Dict, List, Pattern, Tuple
@dataclass(frozen=True)
class RuleHit:
name: str
weight: float
evidence: str
@dataclass(frozen=True)
class RuleEngineResult:
score: float
hits: List[RuleHit]
class RuleEngine:
"""轻量规则引擎:关键词 + 正则。
说明:
- 强命中可设置 weight 很高,或在决策层直接拦截
- 此处示例仅用于学习,生产环境请做更严谨的配置管理与热更新
"""
def __init__(self) -> None:
self.keyword_rules: Dict[str, float] = {
"加我微信": 2.0,
"代开发票": 1.5,
"博彩": 2.5,
"裸聊": 3.0,
}
self.regex_rules: List[Tuple[str, Pattern[str], float]] = [
("phone", re.compile(r"1[3-9]\\d{9}"), 1.2),
("wechat_id", re.compile(r"微信[::]?[a-zA-Z][-_a-zA-Z0-9]{5,19}"), 1.5),
("url", re.compile(r"https?://\\S+|www\\.\\S+"), 0.8),
]
def run(self, text: str) -> RuleEngineResult:
hits: List[RuleHit] = []
score = 0.0
# 关键词命中
for kw, w in self.keyword_rules.items():
if kw in text:
hits.append(RuleHit(name=f"kw:{kw}", weight=w, evidence=kw))
score += w
# 正则命中
for name, pattern, w in self.regex_rules:
m = pattern.search(text)
if m:
hits.append(RuleHit(name=f"re:{name}", weight=w, evidence=m.group(0)))
score += w
return RuleEngineResult(score=score, hits=hits)
步骤 5:审核结果可视化与人工复核流程
内容审核的落地关键不是“模型跑出来一个概率”,而是让运营/安全同学能看得懂、复得了、追得回。因此需要把审核结果组织成可视化字段:
- 最终动作:
allow / block / review; - 违规类型:多标签 top-k(文本、图像、融合各自的 top-k);
- 置信度:概率或校准后的分数;
- 证据链:规则命中(关键词/正则)、模型解释(权重、prompt 命中)、图片缩略图、原文片段;
- 审计信息:请求 id、时间戳、用户/内容 id、模型版本、阈值版本。
人工复核通常采用“灰度区间”策略:当风险分落在 之间,系统不直接拦截,而是进入复核队列;人工的“通过/拦截/打标签/备注”会被写入训练集,形成下一轮迭代数据。为了减少复核压力,可以用 分层阈值(不同业务线不同阈值)、可信用户白名单、聚类去重(相似内容只复核一次)等手段。
下面给出一个“最小可运行”的复核 UI:用 FastAPI 返回一个简单 HTML 页面(不依赖额外前端库),展示审核结果与 evidence。
代码:复核页面(FastAPI 最小示例)
from __future__ import annotations
from dataclasses import asdict, dataclass
from typing import Any, Dict, List, Optional
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
@dataclass(frozen=True)
class ReviewItem:
request_id: str
text: str
image_path: Optional[str]
action: str
risk: float
evidence: List[Dict[str, Any]]
app = FastAPI(title="Multimodal Moderation Demo")
# 演示用内存队列;生产环境应来自数据库/Redis/消息队列
IN_MEMORY_REVIEW_QUEUE: List[ReviewItem] = []
@app.get("/review/queue", response_class=JSONResponse)
def list_review_queue() -> List[Dict[str, Any]]:
return [asdict(x) for x in IN_MEMORY_REVIEW_QUEUE]
@app.get("/review/ui", response_class=HTMLResponse)
def review_ui() -> str:
rows = []
for item in IN_MEMORY_REVIEW_QUEUE[-50:][::-1]:
img_html = ""
if item.image_path:
# 注意:此处仅演示。真实项目需要静态文件托管与权限控制。
img_html = f"<div><b>Image:</b> {item.image_path}</div>"
evidence_html = "<ul>" + "".join(
[f"<li>{e.get('name')}: {e.get('evidence')} (w={e.get('weight')})</li>" for e in item.evidence]
) + "</ul>"
rows.append(
f"""
<div style='border:1px solid #ddd;padding:12px;margin:10px 0'>
<div><b>request_id</b>: {item.request_id}</div>
<div><b>action</b>: {item.action} | <b>risk</b>: {item.risk:.3f}</div>
<div><b>text</b>: {item.text}</div>
{img_html}
<div><b>evidence</b>:</div>
{evidence_html}
</div>
"""
)
html = """
<html>
<head><meta charset='utf-8'><title>Review UI</title></head>
<body style='font-family:Arial, sans-serif; max-width: 900px; margin: 20px auto'>
<h1>人工复核队列(演示)</h1>
<p>用于学习:展示 action/risk/evidence。生产环境需鉴权、分页、检索、操作按钮等。</p>
{content}
</body>
</html>
""".format(content="".join(rows) if rows else "<p>当前队列为空</p>")
return html
步骤 6:高并发审核服务(异步批处理 + 队列架构)
审核服务经常处于高并发、突发流量环境:热点事件、直播带货、营销活动都会造成峰值。若所有请求都同步跑模型,延迟会飙升、CPU/GPU 被打满,引发级联超时。工程上通常用“在线轻推理 + 异步重处理”的两段式:
- 在线路径:对明显违规用规则快速拦截;对较轻的内容做快速推理(必要时只跑文本或只跑图像),并返回 action;
- 异步路径:把需要更重计算的任务(如更大模型、更多 prompt、多模态融合复核、相似聚合)放入队列,用 Celery worker 批处理;
- 队列削峰:Redis 作为 broker,按业务 key 分队列;
- 批处理:将多个请求合并成 batch 推理,提高吞吐;
- 可观测性:记录每层耗时、队列堆积、模型版本与阈值版本。
下面示例给出一个最小可运行架构:FastAPI 接收请求后,把任务丢进 Celery;Celery worker 拉取任务并执行“模拟推理/聚合”,再写入复核队列。
代码:Celery + Redis(可运行最小示例)
运行前准备: 1)启动 Redis:
redis-server
2)启动 worker:celery -A celery_app worker -l info
3)启动 API:uvicorn api_app:app --reload
# celery_app.py
from __future__ import annotations
from dataclasses import asdict
from typing import Any, Dict, Optional
from celery import Celery
# Redis 既做 broker,也可做结果后端(学习示例)
celery_app = Celery(
"moderation_tasks",
broker="redis://localhost:6379/0",
backend="redis://localhost:6379/1",
)
@celery_app.task(name="moderation.async_review")
def async_review(payload: Dict[str, Any]) -> Dict[str, Any]:
"""异步重处理任务(示例)。
真实场景可做:
- 更复杂的多模态融合
- 更强 prompt 集合
- 相似样本聚合
- 写入数据库与监控
"""
# 这里仅返回原样 + 标记,用于演示链路
payload["async_processed"] = True
return payload
# api_app.py
from __future__ import annotations
import uuid
from dataclasses import asdict
from typing import Any, Dict, List, Optional
from fastapi import FastAPI
from pydantic import BaseModel, Field
from celery_app import celery_app
class ModerationRequest(BaseModel):
text: str = Field(default="")
image_path: Optional[str] = Field(default=None, description="学习示例:传本地路径")
app = FastAPI(title="Multimodal Moderation API")
@app.post("/moderate")
def moderate(req: ModerationRequest) -> Dict[str, Any]:
request_id = str(uuid.uuid4())
# 在线路径:这里仅演示把任务丢给 Celery
task = celery_app.send_task(
"moderation.async_review",
kwargs={
"payload": {
"request_id": request_id,
"text": req.text,
"image_path": req.image_path,
}
},
)
return {
"request_id": request_id,
"action": "review", # 学习示例:全部进入复核
"celery_task_id": task.id,
}
@app.get("/task/{task_id}")
def get_task(task_id: str) -> Dict[str, Any]:
async_result = celery_app.AsyncResult(task_id)
return {
"task_id": task_id,
"status": async_result.status,
"result": async_result.result if async_result.successful() else None,
}
4. 进阶优化
4.1 对抗样本防御策略
对抗与绕过在审核场景非常常见:文本侧有谐音、拆字、空格插入、同形字、emoji 夹杂;图像侧有马赛克、遮挡、旋转、缩放、对比度/饱和度扰动、加噪声、动漫化风格迁移等。防御思路可分三类:
1)输入增强:文本侧做归一化(同形字映射、空白折叠、数字/拼音变体),图像侧做多视角预处理(多尺度、中心/随机裁剪、轻量去噪)并对结果取一致性;
2)鲁棒训练/蒸馏:在训练集中加入对抗增强样本,或用对抗训练(FGSM/PGD)提升鲁棒性;
3)一致性检测:同一内容在多种变换下的预测分布差异过大时,直接进入人工复核(把“不确定性”显式化)。
4.2 多语言审核能力扩展
全球化平台会同时出现中文、英文、混合语种甚至低资源语种。扩展路线:
- 文本侧:用多语言模型(如 XLM-R)统一建模,或者“语言识别→路由到对应语言模型”;
- 规则侧:关键词与正则按语种分桶管理;
- 图像侧:CLIP prompts 同步多语言化(同一个标签,用多语言 prompt 集合取最大相似度)以减少语种偏差。
4.3 误判申诉与模型迭代闭环
审核系统的生命线是闭环:误判申诉会快速暴露规则过严、阈值不合理、prompt 偏差或训练数据偏斜。闭环最重要的不是“收集所有样本”,而是高价值样本优先:
- 复核台记录“人工最终标签 + 备注原因”;
- 把“模型高置信错样本”与“申诉集中爆发样本”优先进入下一轮训练;
- 每次上线记录模型版本、阈值版本、规则版本,便于回滚与责任追溯。
4.4 审核延迟与准确率的权衡
常见矛盾:更强模型更准但更慢;更多 prompt 更全面但延迟更高。一个实用的折中策略是 分层推理:
- 第 1 层:规则 + 轻量模型(低延迟,覆盖大部分样本);
- 第 2 层:只对“灰度区间”调用更强模型或多模态融合;
- 第 3 层:仍不确定的进入人工复核。
这相当于把系统目标从“每条都最准”转为“整体吞吐与风险最优”。
5. 完整可运行代码(把每步串起来)
下面给出一个“单机可运行”的最小工程骨架,把:
- 文本推理(加载步骤 1 导出的模型目录)
- 图像推理(CLIP 零样本)
- 规则引擎
- 简化融合(用注意力融合的权重解释;示例中用概率做融合输入)
- 决策器(allow/block/review)
- FastAPI 服务接口
整合到一个文件中,便于你复制后快速跑通。真实项目建议拆分为模块并加入配置管理、监控、鉴权与持久化。
依赖:
transformers, torch, PIL, fastapi(以及你需要的celery, redis等)
from __future__ import annotations
import math
import uuid
from dataclasses import asdict, dataclass
from typing import Any, Dict, List, Optional, Tuple
import torch
from fastapi import FastAPI
from pydantic import BaseModel, Field
from PIL import Image
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
CLIPModel,
CLIPProcessor,
)
# =========================
# 1) 规则引擎
# =========================
import re
from typing import Pattern
@dataclass(frozen=True)
class RuleHit:
name: str
weight: float
evidence: str
@dataclass(frozen=True)
class RuleEngineResult:
score: float
hits: List[RuleHit]
class RuleEngine:
def __init__(self) -> None:
self.keyword_rules: Dict[str, float] = {
"加我微信": 2.0,
"博彩": 2.5,
"裸聊": 3.0,
}
self.regex_rules: List[Tuple[str, Pattern[str], float]] = [
("phone", re.compile(r"1[3-9]\\d{9}"), 1.2),
("url", re.compile(r"https?://\\S+|www\\.\\S+"), 0.8),
]
def run(self, text: str) -> RuleEngineResult:
hits: List[RuleHit] = []
score = 0.0
for kw, w in self.keyword_rules.items():
if kw in text:
hits.append(RuleHit(name=f"kw:{kw}", weight=w, evidence=kw))
score += w
for name, pattern, w in self.regex_rules:
m = pattern.search(text)
if m:
hits.append(RuleHit(name=f"re:{name}", weight=w, evidence=m.group(0)))
score += w
return RuleEngineResult(score=score, hits=hits)
# =========================
# 2) 文本审核器(加载微调模型)
# =========================
@dataclass(frozen=True)
class TextModerationResult:
label: str
score: float
topk: List[Tuple[str, float]]
class TextModerator:
def __init__(self, model_dir: str, device: Optional[str] = None) -> None:
self.tokenizer = AutoTokenizer.from_pretrained(model_dir)
self.model = AutoModelForSequenceClassification.from_pretrained(model_dir)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = device
self.model.to(self.device)
self.model.eval()
def predict(self, text: str, top_k: int = 3) -> TextModerationResult:
encoded = self.tokenizer(
text,
truncation=True,
max_length=128,
padding=True,
return_tensors="pt",
)
encoded = {k: v.to(self.device) for k, v in encoded.items()}
with torch.inference_mode():
logits = self.model(**encoded).logits
probs = torch.softmax(logits, dim=-1).squeeze(0)
topk = torch.topk(probs, k=min(top_k, probs.numel()))
id2label: Dict[int, str] = self.model.config.id2label
topk_list = [(id2label[int(i)], float(p)) for i, p in zip(topk.indices, topk.values)]
return TextModerationResult(label=topk_list[0][0], score=topk_list[0][1], topk=topk_list)
# =========================
# 3) 图像审核器(CLIP 零样本)
# =========================
@dataclass(frozen=True)
class ImageModerationResult:
label: str
score: float
topk: List[Tuple[str, float]]
class CLIPZeroShotModerator:
def __init__(
self,
device: Optional[str] = None,
model_name: str = "openai/clip-vit-base-patch32",
) -> None:
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = device
self.model = CLIPModel.from_pretrained(model_name).to(self.device)
self.processor = CLIPProcessor.from_pretrained(model_name)
self.model.eval()
def predict(self, image: Image.Image, prompts: List[str], top_k: int = 3) -> ImageModerationResult:
inputs = self.processor(text=prompts, images=image, return_tensors="pt", padding=True)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.inference_mode():
logits = self.model(**inputs).logits_per_image.squeeze(0)
probs = torch.softmax(logits, dim=-1)
topk = torch.topk(probs, k=min(top_k, probs.numel()))
topk_list = [(prompts[int(i)], float(p)) for i, p in zip(topk.indices, topk.values)]
return ImageModerationResult(label=topk_list[0][0], score=topk_list[0][1], topk=topk_list)
# =========================
# 4) 多模态融合(工程化简化版)
# =========================
@dataclass(frozen=True)
class FusionDecision:
action: str # allow/block/review
risk: float
reason: str
def sigmoid(x: float) -> float:
return 1.0 / (1.0 + math.exp(-x))
class SimpleDecisionMaker:
"""一个可解释的决策器:规则分 + 模型分 的加权。
注意:
- 学习示例里我们把“违规置信度”简化为:
- 文本:非 normal 的概率之和(可按你业务定义)
- 图像:非 normal prompt 的最大概率(可按你业务定义)
- 实战需要校准(Platt/温度缩放等)与分业务线阈值
"""
def __init__(self) -> None:
self.lambda_rule = 0.6
self.lambda_text = 0.8
self.lambda_image = 0.8
self.block_threshold = 0.85
self.review_threshold = 0.55
def decide(
self,
rule_score: float,
text_risk: float,
image_risk: float,
) -> FusionDecision:
# 将 rule_score 映射到 (0,1),避免不同规则数量导致尺度飙升
rule_risk = sigmoid(rule_score)
risk = (
self.lambda_rule * rule_risk
+ self.lambda_text * text_risk
+ self.lambda_image * image_risk
) / (self.lambda_rule + self.lambda_text + self.lambda_image)
if risk >= self.block_threshold:
return FusionDecision(action="block", risk=risk, reason="risk>=block_threshold")
if risk >= self.review_threshold:
return FusionDecision(action="review", risk=risk, reason="risk>=review_threshold")
return FusionDecision(action="allow", risk=risk, reason="risk<review_threshold")
# =========================
# 5) FastAPI 入口
# =========================
class ModerationRequest(BaseModel):
text: str = Field(default="")
image_path: Optional[str] = Field(default=None)
class ModerationResponse(BaseModel):
request_id: str
action: str
risk: float
reason: str
evidence: List[Dict[str, Any]]
text_topk: List[Tuple[str, float]]
image_topk: List[Tuple[str, float]]
app = FastAPI(title="Multimodal Moderation (All-in-one Demo)")
# 你需要先训练并导出 text_model 目录,或换成可用模型目录
TEXT_MODEL_DIR = "./text_model"
# 初始化组件(生产环境注意:模型加载要放在进程启动阶段,避免请求中重复加载)
rule_engine = RuleEngine()
# 如果你没有训练文本模型,可以暂时注释 TextModerator,并把 text_risk 固定为 0
text_moderator: Optional[TextModerator] = None
try:
text_moderator = TextModerator(TEXT_MODEL_DIR)
except Exception:
text_moderator = None
image_moderator = CLIPZeroShotModerator()
decider = SimpleDecisionMaker()
IMAGE_PROMPTS: List[str] = [
"这是一张正常的生活照片",
"这是一张色情低俗图片",
"这是一张暴力血腥图片",
"这是一张包含仇恨符号的图片",
"这是一张诈骗引流海报",
]
@app.post("/moderate", response_model=ModerationResponse)
def moderate(req: ModerationRequest) -> ModerationResponse:
request_id = str(uuid.uuid4())
# 1) 规则
rule_res = rule_engine.run(req.text)
# 2) 文本模型
text_topk: List[Tuple[str, float]] = []
text_risk = 0.0
if text_moderator is not None and req.text.strip():
t = text_moderator.predict(req.text)
text_topk = t.topk
# 示例:把非 normal 的概率求和作为“风险”
text_risk = float(sum(p for label, p in t.topk if label != "normal"))
# 3) 图像模型
image_topk: List[Tuple[str, float]] = []
image_risk = 0.0
if req.image_path:
img = Image.open(req.image_path).convert("RGB")
ir = image_moderator.predict(img, IMAGE_PROMPTS)
image_topk = ir.topk
# 示例:把非 normal prompt 的最大概率作为“风险”
image_risk = float(max((p for label, p in ir.topk if "正常" not in label), default=0.0))
# 4) 融合决策
decision = decider.decide(rule_res.score, text_risk, image_risk)
evidence: List[Dict[str, Any]] = [asdict(h) for h in rule_res.hits]
return ModerationResponse(
request_id=request_id,
action=decision.action,
risk=decision.risk,
reason=decision.reason,
evidence=evidence,
text_topk=text_topk,
image_topk=image_topk,
)
# 运行:uvicorn this_file:app --reload
6. 学习要点总结(5–8 条)
- 多模态审核的本质是“语境 + 证据”联合判断:文本与图像单独看都可能不违规,但组合后可能构成违规或引流。
- 文本审核工程化要把清洗归一化与阈值策略配置化:模型只是中间件,业务策略决定最终动作。
- CLIP 零样本分类适合冷启动与快速扩展标签体系:关键在 prompt 设计、阈值校准与误伤控制。
- 注意力融合提供了“可解释的权重”:不仅能提升效果,也能帮助定位误判来源(更依赖文本还是图像)。
- 规则与模型不是替代关系,而是分工协同:规则处理强确定性模式,模型处理语境与泛化,决策器统一融合。
- 高并发场景要把重推理异步化:在线轻推理保证体验,队列 + 批处理保证吞吐,灰度样本进入复核。
- 人工复核与申诉是数据闭环入口:把高价值错样本优先回流训练,版本可追溯才能稳定迭代。
你可以在这个案例基础上继续扩展:
- 将“图片路径”改成上传文件(FastAPI
UploadFile)- 引入更强的多模态模型或 cross-attention
- 加入温度缩放/Platt 校准,提升概率可用性
- 把规则与阈值放到 Redis/配置中心实现热更新