概述
数学是人工智能的底层语言。从神经网络的梯度下降到注意力机制的矩阵乘法,从概率生成模型到贝叶斯推断,AI 的每个核心组件都建立在坚实的数学基础之上。然而,对于工程实践者而言,我们不需要像数学家那样追求严格的证明体系,而是需要建立起"直觉理解"——能够看懂损失函数的数学表达、理解梯度下降的几何意义、读懂论文中的公式推导。
本模块聚焦四个核心数学领域(线性代数、微积分、概率统计、优化方法)以及基础数据结构与算法,按照"从概念到实践"的路径组织内容。每个知识点都配有直观的解释和在 AI 中的具体应用场景,确保你能够将抽象的数学符号与实际的代码实现对应起来。
线性代数是人工智能的数学基础,它为数据的表示、变换和分析提供了强大的工具。在机器学习领域,从数据预处理到模型训练,从神经网络的前向传播到反向传播,线性代数无处不在。本章将从实用角度出发,介绍理解AI算法所必需的线性代数知识,避免过度复杂的理论推导,注重几何直觉和代码实现。
3.1 向量与向量空间
3.1.1 向量的定义与表示
向量是线性代数中最基本的概念,它可以被理解为具有大小和方向的量。在AI中,向量是表示数据的基本方式:一张图片可以表示为像素值的向量,一段文本可以表示为词嵌入向量,一个用户的行为可以表示为特征向量。
从数学角度看,一个维向量是一个有序的元组:
在Python中,我们通常使用NumPy数组来表示向量:
import numpy as np
# 创建向量
v = np.array([3, 1, 4, 1, 5])
print(f"向量: {v}")
print(f"维度: {v.shape}")
print(f"L2范数: {np.linalg.norm(v):.4f}")
向量的范数(Norm)表示向量的"长度"。最常用的L2范数(欧几里得范数)定义为:
在机器学习中,范数有重要应用:L2正则化通过惩罚大权重的L2范数来防止过拟合;余弦相似度通过向量的内积和范数来衡量两个向量的相似程度。
3.1.2 向量运算与几何意义
向量的基本运算包括加法、数乘和点积,每种运算都有直观的几何解释。
向量加法遵循平行四边形法则。两个向量和的和,几何上表示以这两个向量为邻边的平行四边形的对角线。
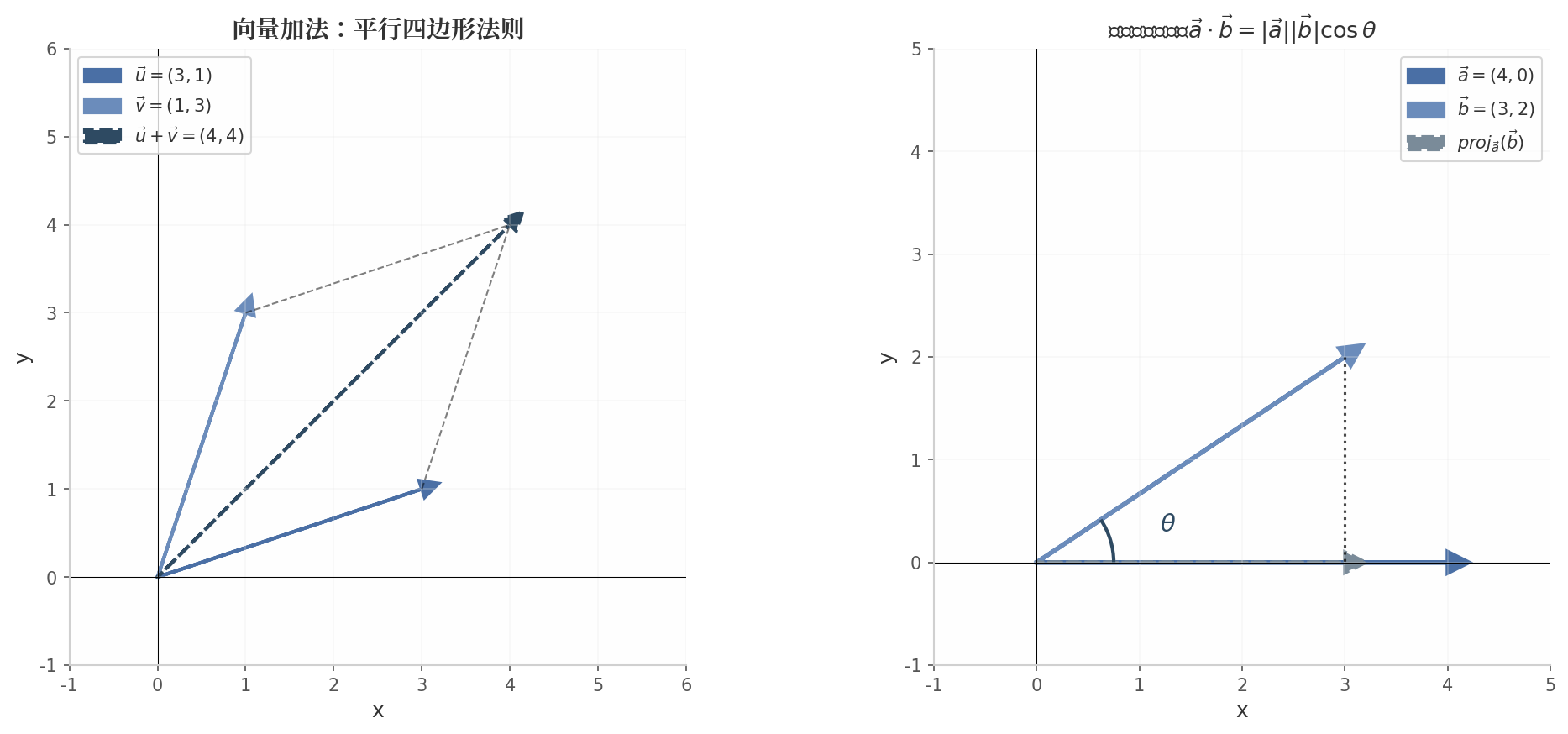
点积(内积)是机器学习中最重要的向量运算之一。两个向量的点积定义为:
点积的几何意义尤为深刻:
其中是两个向量之间的夹角。这个公式揭示了点积的本质:它衡量了两个向量的"同向程度"。当两个向量方向相同时,点积最大;当方向垂直时,点积为零;当方向相反时,点积为负。
import numpy as np
# 向量运算示例
u = np.array([3, 1])
v = np.array([1, 3])
# 向量加法
w = u + v
print(f"u + v = {w}")
# 点积
dot_product = np.dot(u, v)
print(f"u · v = {dot_product}")
# 计算夹角
cos_theta = dot_product / (np.linalg.norm(u) * np.linalg.norm(v))
theta = np.arccos(cos_theta)
print(f"夹角: {np.degrees(theta):.2f}°")
# 投影
projection = dot_product / np.linalg.norm(v)
print(f"u在v上的投影长度: {projection:.4f}")
点积在AI中的应用:
- 余弦相似度:衡量两个文档、用户或物品的相似程度,是推荐系统和信息检索的核心算法
- 注意力机制:Transformer中的自注意力通过点积计算查询与键的相似度
- 线性回归:预测值是特征向量与权重向量的点积
叉积(仅适用于三维向量)产生一个垂直于原向量所在平面的新向量,其模等于两向量张成的平行四边形的面积。叉积在计算机图形学和物理模拟中有广泛应用。
import numpy as np
# 叉积示例
u = np.array([1, 0, 0])
v = np.array([0, 1, 0])
cross_product = np.cross(u, v)
print(f"u × v = {cross_product}") # 结果应该是[0, 0, 1]
# 叉积的模等于平行四边形面积
area = np.linalg.norm(cross_product)
print(f"平行四边形面积: {area}")
外积将两个向量相乘产生一个矩阵,在机器学习中用于构造秩1矩阵:
# 外积示例
u = np.array([1, 2, 3])
v = np.array([4, 5])
outer_product = np.outer(u, v)
print(f"外积结果:\n{outer_product}")
3.1.3 向量空间与子空间
向量空间(Vector Space)是一组向量的集合,满足特定的公理(加法封闭性、数乘封闭性等)。直观上,向量空间可以看作是一个"空间",其中的向量可以通过加法和数乘进行"移动"和"伸缩"。
基(Basis)是向量空间中的一组特殊向量,它们线性无关且可以表示空间中的任何向量。维空间的标准基是:
子空间是向量空间的子集,本身也构成向量空间。在机器学习中,降维的本质就是寻找数据所在的低维子空间。例如,主成分分析(PCA)找到的是数据方差最大的子空间。
线性无关与秩:一组向量线性无关意味着没有一个向量可以被其他向量的线性组合表示。向量组的秩(Rank)是其中线性无关向量的最大个数,它表示这组向量张成的子空间的维度。
import numpy as np
# 判断向量组的线性相关性
vectors = np.array([
[1, 2, 3],
[2, 4, 6], # 这是第一个向量的2倍,线性相关
[1, 0, 1]
])
# 计算秩
rank = np.linalg.matrix_rank(vectors)
print(f"向量组的秩: {rank}") # 输出2,说明只有2个线性无关的向量
# 寻找一组基(通过SVD)
U, S, Vt = np.linalg.svd(vectors)
print(f"奇异值: {S}") # 非零奇异值的个数等于秩
张成空间(Span)是一组向量所有线性组合的集合。如果一组向量张成的空间是整个,则称这组向量是完备的(Complete)。在机器学习中,特征空间的维度决定了模型的表达能力。
维数定理(Rank-Nullity Theorem)指出:对于矩阵,
其中是的零空间维度。这个定理揭示了线性变换的"信息损失":输入空间的维度等于像空间维度加上被"压缩"到零的维度。
# 零空间示例
A = np.array([[1, 2, 3], [2, 4, 6]]) # 秩为1
print(f"矩阵A的秩: {np.linalg.matrix_rank(A)}")
# 通过SVD找到零空间
U, S, Vt = np.linalg.svd(A)
# 零空间由Vt中对应于零奇异值的行向量张成
null_space = Vt[1:, :] # 假设只有一个非零奇异值
print(f"零空间的基向量:\n{null_space}")
# 验证:A @ null_space.T 应该接近零
print(f"验证 A @ null_space.T:\n{A @ null_space.T}")
3.2 矩阵与矩阵运算
3.2.1 矩阵的基本概念
矩阵是线性代数的核心工具,它是一个由数字排列成的矩形阵列。一个的矩阵有行列:
在机器学习中,矩阵是表示数据的自然方式:
- 一个数据集通常表示为的矩阵,是样本数,是特征数
- 神经网络的权重是矩阵
- 图像可以看作像素值的矩阵
import numpy as np
# 创建矩阵
A = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
print(f"矩阵A:\n{A}")
print(f"形状: {A.shape}")
print(f"转置:\n{A.T}")
# 访问元素
print(f"A[1,2] = {A[1, 2]}") # 第2行第3列(从0开始计数)
print(f"第2行: {A[1, :]}")
print(f"第3列: {A[:, 2]}")
3.2.2 矩阵乘法与转置
矩阵乘法是线性代数中最重要的运算。对于矩阵和,它们的乘积的元素定义为:
矩阵乘法的几何意义是线性变换的组合。当我们用矩阵乘以向量时,实际上是对进行了一次线性变换。
import numpy as np
# 矩阵乘法示例
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 矩阵乘法
C = np.dot(A, B)
# 或使用 @ 运算符(Python 3.5+)
C_alt = A @ B
print(f"A @ B =\n{C}")
# 验证: C[0,0] = 1*5 + 2*7 = 19
print(f"手动计算C[0,0]: {A[0,0]*B[0,0] + A[0,1]*B[1,0]}")
# 矩阵-向量乘法
v = np.array([1, 2])
result = A @ v
print(f"A @ v = {result}")
矩阵乘法的性质:
- 不满足交换律:一般情况下
- 满足结合律:
- 满足分配律:
转置操作将矩阵的行和列互换。矩阵的转置记为:
转置的重要性质:
- 对称矩阵满足
广播机制是NumPy中处理不同形状数组运算的重要特性。当两个数组的形状不同时,NumPy会自动扩展较小的数组以匹配较大数组的形状。这在机器学习中非常常见,例如给每个样本加上相同的偏置向量:
import numpy as np
# 广播示例
X = np.array([[1, 2, 3], [4, 5, 6]]) # 2x3矩阵
b = np.array([10, 20, 30]) # 1x3向量
# 广播:b被扩展为[[10,20,30], [10,20,30]]
result = X + b
print(f"广播结果:\n{result}")
# 矩阵乘法中的广播
W = np.random.randn(3, 2)
b = np.array([1, 2])
X = np.random.randn(5, 3)
output = X @ W + b # b被广播到(5, 2)
print(f"输出形状: {output.shape}")
批量矩阵乘法在深度学习中非常常见。当处理一个batch的数据时,输入是一个三维张量,权重是,输出是:
# 批量矩阵乘法
batch_size = 32
seq_len = 10
d_model = 64
d_ff = 256
# 输入: (batch, seq, d_model)
X = np.random.randn(batch_size, seq_len, d_model)
# 权重: (d_model, d_ff)
W = np.random.randn(d_model, d_ff)
# 批量矩阵乘法
output = X @ W # 结果: (batch, seq, d_ff)
print(f"输入形状: {X.shape}")
print(f"权重形状: {W.shape}")
print(f"输出形状: {output.shape}")
3.2.3 特殊矩阵类型
在AI中,有几种特殊类型的矩阵特别重要:
| 矩阵类型 | 定义 | 应用场景 |
|---|---|---|
| 单位矩阵 | 对角线为1,其余为0 | 矩阵乘法的"1" |
| 对角矩阵 | 非对角线元素全为0 | 缩放变换、特征分解 |
| 对称矩阵 | 协方差矩阵、核矩阵 | |
| 正交矩阵 | 旋转变换、PCA | |
| 正定矩阵 | 优化问题的Hessian矩阵 |
import numpy as np
# 单位矩阵
I = np.eye(3)
print(f"3x3单位矩阵:\n{I}")
# 对角矩阵
D = np.diag([2, 3, 5])
print(f"对角矩阵:\n{D}")
# 验证正交矩阵
Q = np.array([[0, -1], [1, 0]]) # 90度旋转矩阵
print(f"Q^T @ Q =\n{Q.T @ Q}") # 应该接近单位矩阵
# 对称矩阵
S = np.array([[2, 1], [1, 3]])
print(f"S是否对称: {np.allclose(S, S.T)}")
# 验证正定性(通过特征值)
eigenvalues = np.linalg.eigvals(S)
print(f"特征值: {eigenvalues}")
print(f"是否正定: {np.all(eigenvalues > 0)}")
3.2.4 矩阵分解初步
矩阵分解是将矩阵表示为更简单矩阵乘积的技术,在AI中有广泛应用。
LU分解:将矩阵分解为下三角矩阵和上三角矩阵的乘积,用于高效求解线性方程组。
特征分解:对于方阵,如果存在非零向量和标量使得:
则称为特征值,称为特征向量。特征分解将矩阵表示为:
其中是对角矩阵,对角线元素是特征值;的列是对应的特征向量。
奇异值分解(SVD):对于任意矩阵,都可以分解为:
其中和是正交矩阵,是对角矩阵(对角线元素称为奇异值,非负且按降序排列)。
SVD的应用:
- 降维:通过保留前个最大的奇异值,可以实现数据的有效压缩
- 去噪:小奇异值通常对应噪声,去除它们可以净化信号
- 推荐系统:矩阵分解是协同过滤的基础
- 图像压缩:保留主要奇异值可以大幅减小图像存储空间
import numpy as np
import matplotlib.pyplot as plt
# SVD在图像压缩中的应用示例
# 创建一个模拟的"图像"矩阵
image = np.zeros((100, 100))
for i in range(100):
for j in range(100):
image[i, j] = np.sin(i/10) * np.cos(j/10) + 0.1 * np.random.randn()
# SVD分解
U, S, Vt = np.linalg.svd(image, full_matrices=False)
# 使用不同数量的奇异值进行重构
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes = axes.flatten()
k_values = [5, 10, 20, 50, 100]
for idx, k in enumerate(k_values):
# 低秩近似
image_approx = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]
compression_ratio = (100*100) / (k * (100 + 100 + 1))
ax = axes[idx]
ax.imshow(image_approx, cmap='gray')
ax.set_title(f'k={k}, Compression={compression_ratio:.1f}x')
ax.axis('off')
# 原始图像
axes[-1].imshow(image, cmap='gray')
axes[-1].set_title('Original')
axes[-1].axis('off')
plt.tight_layout()
plt.savefig('/mnt/okcomputer/output/fig_svd_compression.png', dpi=100, bbox_inches='tight')
plt.show()
print(f"原始图像大小: {image.size} 个元素")
print(f"前10个奇异值: {S[:10].round(2)}")
print(f"奇异值总和: {S.sum():.2f}")
print(f"前10个奇异值占比: {S[:10].sum() / S.sum():.2%}")
import numpy as np
# 奇异值分解
A = np.array([[1, 2, 3], [4, 5, 6]])
U, S, Vt = np.linalg.svd(A, full_matrices=False)
print(f"U shape: {U.shape}")
print(f"奇异值: {S}")
print(f"Vt shape: {Vt.shape}")
# 重构矩阵
A_reconstructed = U @ np.diag(S) @ Vt
print(f"重构误差: {np.linalg.norm(A - A_reconstructed):.10f}")
# 低秩近似(保留前k个奇异值)
k = 1
A_approx = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]
print(f"秩1近似误差: {np.linalg.norm(A - A_approx):.4f}")
3.3 线性变换与特征分析
3.3.1 线性变换的矩阵表示
线性变换是保持向量加法和数乘的映射。任何线性变换都可以用矩阵乘法来表示。对于变换和向量、,以及标量:
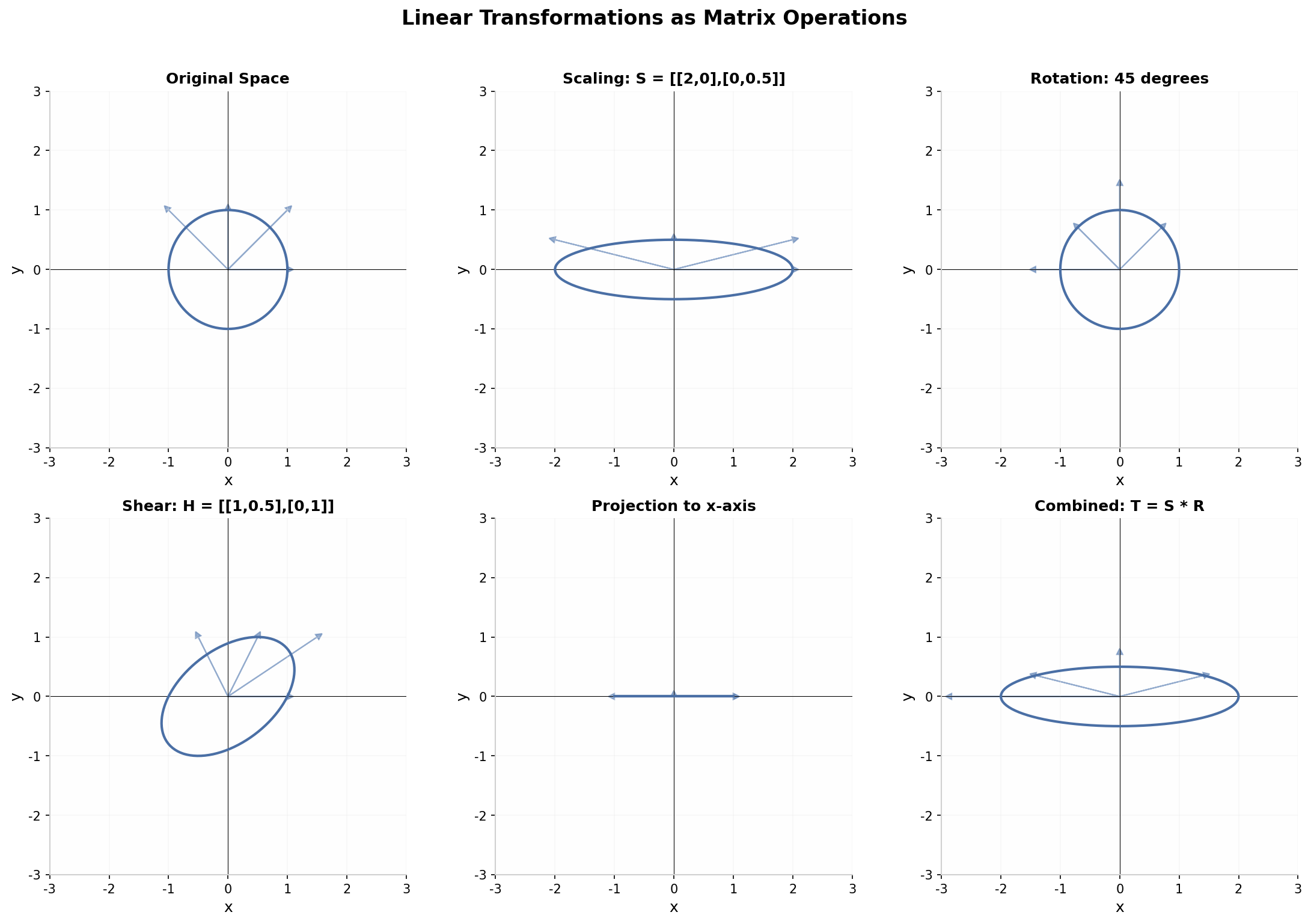
上图展示了常见的线性变换及其矩阵表示:
- 缩放变换:
- 旋转变换:
- 剪切变换:
- 投影变换:将向量投影到某个子空间
import numpy as np
import matplotlib.pyplot as plt
# 线性变换示例:图像旋转
def rotate_image_points(points, angle_deg):
"""旋转点集"""
angle_rad = np.radians(angle_deg)
R = np.array([
[np.cos(angle_rad), -np.sin(angle_rad)],
[np.sin(angle_rad), np.cos(angle_rad)]
])
return points @ R.T
# 创建一个简单的"图像"(正方形的点)
x = np.linspace(-1, 1, 20)
y = np.linspace(-1, 1, 20)
X, Y = np.meshgrid(x, y)
points = np.column_stack([X.ravel(), Y.ravel()])
# 应用旋转变换
rotated_points = rotate_image_points(points, 45)
print(f"原始点形状: {points.shape}")
print(f"变换后点形状: {rotated_points.shape}")
print(f"旋转矩阵:\n{np.array([[np.cos(np.pi/4), -np.sin(np.pi/4)], [np.sin(np.pi/4), np.cos(np.pi/4)]])}")
3.3.2 特征值与特征向量
特征值和特征向量是理解线性变换本质的关键。对于矩阵,如果:
则是的特征向量,是对应的特征值。
几何解释:特征向量是在变换后方向不变的向量(或反向),特征值表示该方向上伸缩的倍数。
import numpy as np
# 计算特征值和特征向量
A = np.array([[4, 2], [1, 3]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print(f"特征值: {eigenvalues}")
print(f"特征向量:\n{eigenvectors}")
# 验证 Av = λv
for i in range(len(eigenvalues)):
v = eigenvectors[:, i]
lambda_v = eigenvalues[i]
Av = A @ v
lambda_v_v = lambda_v * v
print(f"\n特征向量 {i+1}: {v}")
print(f"A @ v = {Av}")
print(f"λ * v = {lambda_v_v}")
print(f"验证结果: {np.allclose(Av, lambda_v_v)}")
特征值的重要性质:
- 矩阵的迹(对角线元素之和)等于特征值之和
- 矩阵的行列式等于特征值之积
- 对称矩阵的特征值都是实数,特征向量两两正交
特征值分解与矩阵幂运算:对角化使得矩阵的幂运算变得简单。对于可对角化的矩阵:
这在计算状态转移、PageRank等迭代算法中非常有用。
import numpy as np
# 矩阵幂运算示例
A = np.array([[0.9, 0.1], [0.2, 0.8]])
# 方法1: 直接计算
A_power_10_direct = np.linalg.matrix_power(A, 10)
# 方法2: 通过特征值分解
eigenvalues, eigenvectors = np.linalg.eig(A)
V = eigenvectors
Lambda = np.diag(eigenvalues)
V_inv = np.linalg.inv(V)
A_power_10_eig = V @ np.diag(eigenvalues**10) @ V_inv
print("直接计算 A^10:")
print(A_power_10_direct.round(4))
print("\n特征值分解计算 A^10:")
print(A_power_10_eig.round(4))
print(f"\n两种方法结果一致: {np.allclose(A_power_10_direct, A_power_10_eig)}")
# 稳态分布(当n->无穷时)
# 稳态分布对应于特征值1的特征向量
steady_state = eigenvectors[:, np.isclose(eigenvalues, 1)]
steady_state = steady_state / steady_state.sum() # 归一化
print(f"\n稳态分布: {steady_state.flatten().real.round(4)}")
协方差矩阵的特征分析:在统计学中,数据的协方差矩阵的特征值和特征向量揭示了数据的主要变异方向。最大的特征值对应的特征向量指向数据方差最大的方向,这正是PCA的基础。
# 协方差矩阵的特征分析
np.random.seed(42)
# 生成相关数据
n_samples = 500
x = np.random.randn(n_samples)
y = 0.8 * x + 0.6 * np.random.randn(n_samples)
data = np.column_stack([x, y])
# 计算协方差矩阵
cov_matrix = np.cov(data.T)
print(f"协方差矩阵:\n{cov_matrix.round(4)}")
# 特征值分解
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
print(f"\n特征值: {eigenvalues.round(4)}")
print(f"特征向量:\n{eigenvectors.round(4)}")
# 特征值表示各方向的方差
print(f"\n总方差: {eigenvalues.sum():.4f}")
print(f"第一主成分解释方差比例: {eigenvalues[1]/eigenvalues.sum():.2%}")
3.3.3 对角化与谱分解
对角化是将方阵表示为:
其中是对角矩阵。对角化的好处是简化矩阵运算:
谱分解是对称矩阵的特殊对角化形式:
这表示对称矩阵可以分解为秩1矩阵的加权和。
import numpy as np
# 对称矩阵的谱分解
A = np.array([[2, 1], [1, 2]])
eigenvalues, eigenvectors = np.linalg.eigh(A) # eigh用于对称矩阵
print(f"特征值: {eigenvalues}")
print(f"特征向量:\n{eigenvectors}")
# 谱分解重构
A_reconstructed = np.zeros_like(A, dtype=float)
for i in range(len(eigenvalues)):
lambda_i = eigenvalues[i]
v_i = eigenvectors[:, i:i+1] # 保持列向量形状
A_reconstructed += lambda_i * (v_i @ v_i.T)
print(f"\n原始矩阵:\n{A}")
print(f"谱分解重构:\n{A_reconstructed}")
print(f"重构误差: {np.linalg.norm(A - A_reconstructed):.10f}")
# 验证特征向量正交性
print(f"\n特征向量正交性验证:")
print(f"v1·v2 = {np.dot(eigenvectors[:, 0], eigenvectors[:, 1]):.10f}")
3.4 线性代数在AI中的应用
3.4.1 数据表示与嵌入空间
在AI中,数据通常被表示为向量或矩阵,这种表示使得数学运算和机器学习算法可以高效地处理数据。
词嵌入是自然语言处理中的核心技术。每个词被表示为一个高维向量(如300维),语义相近的词在向量空间中距离较近。词嵌入的神奇之处在于向量运算可以捕捉语义关系:
import numpy as np
# 简化的词嵌入示例
# 假设我们有以下词向量(实际中通过Word2Vec或GloVe训练得到)
word_vectors = {
'king': np.array([0.8, 0.6, 0.3]),
'queen': np.array([0.7, 0.8, 0.4]),
'man': np.array([0.5, 0.2, 0.1]),
'woman': np.array([0.4, 0.7, 0.3]),
'apple': np.array([0.1, 0.2, 0.9])
}
def cosine_similarity(v1, v2):
"""计算余弦相似度"""
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
def find_most_similar(query_vector, word_vectors, exclude=None):
"""找到最相似的词"""
best_word = None
best_sim = -1
for word, vec in word_vectors.items():
if exclude and word in exclude:
continue
sim = cosine_similarity(query_vector, vec)
if sim > best_sim:
best_sim = sim
best_word = word
return best_word, best_sim
# 词类比: king - man + woman ≈ ?
query = word_vectors['king'] - word_vectors['man'] + word_vectors['woman']
result, similarity = find_most_similar(query, word_vectors, exclude=['king', 'man', 'woman'])
print(f"king - man + woman ≈ {result} (相似度: {similarity:.4f})")
# 查看所有词对的相似度
print("\n词向量余弦相似度矩阵:")
words = list(word_vectors.keys())
sim_matrix = np.zeros((len(words), len(words)))
for i, w1 in enumerate(words):
for j, w2 in enumerate(words):
sim_matrix[i, j] = cosine_similarity(word_vectors[w1], word_vectors[w2])
for i, w in enumerate(words):
print(f"{w}: {sim_matrix[i]}")
3.4.2 神经网络的前向传播
神经网络的核心运算是矩阵乘法和激活函数的组合。一个全连接层可以表示为:
其中是权重矩阵,是偏置向量,是激活函数。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-np.clip(x, -500, 500)))
def relu(x):
return np.maximum(0, x)
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
# 定义一个简单的神经网络
class SimpleNN:
def __init__(self, input_size, hidden_size, output_size):
# 初始化权重和偏置
self.W1 = np.random.randn(input_size, hidden_size) * 0.1
self.b1 = np.zeros(hidden_size)
self.W2 = np.random.randn(hidden_size, output_size) * 0.1
self.b2 = np.zeros(output_size)
def forward(self, X):
"""前向传播"""
# 第一层: 线性变换 + ReLU激活
self.z1 = X @ self.W1 + self.b1 # 矩阵乘法
self.a1 = relu(self.z1) # 激活函数
# 第二层: 线性变换 + Softmax
self.z2 = self.a1 @ self.W2 + self.b2
self.a2 = softmax(self.z2)
return self.a2
# 创建网络并进行前向传播
np.random.seed(42)
model = SimpleNN(input_size=784, hidden_size=128, output_size=10)
# 模拟一个batch的输入(例如MNIST图像)
batch_size = 32
X_batch = np.random.randn(batch_size, 784)
# 前向传播
output = model.forward(X_batch)
print(f"输入形状: {X_batch.shape}")
print(f"第一层权重形状: {model.W1.shape}")
print(f"第二层权重形状: {model.W2.shape}")
print(f"输出形状: {output.shape}")
print(f"输出概率和: {output[0].sum():.4f}") # 应该接近1
反向传播的矩阵视角:反向传播算法通过链式法则高效地计算梯度。对于线性层,损失函数对参数的梯度为:
# 简化的反向传播示例
class LinearLayer:
"""带反向传播的线性层"""
def __init__(self, in_features, out_features):
self.W = np.random.randn(in_features, out_features) * 0.01
self.b = np.zeros(out_features)
self.x = None # 保存前向传播输入
self.grad_W = None
self.grad_b = None
def forward(self, x):
self.x = x
return x @ self.W + self.b
def backward(self, grad_output):
"""
grad_output: dL/dz, shape (batch, out_features)
"""
# dL/dW = x^T @ dL/dz
self.grad_W = self.x.T @ grad_output / self.x.shape[0]
# dL/db = mean(dL/dz, axis=0)
self.grad_b = grad_output.mean(axis=0)
# dL/dx = dL/dz @ W^T
grad_input = grad_output @ self.W.T
return grad_input
# 测试反向传播
np.random.seed(42)
layer = LinearLayer(10, 5)
x = np.random.randn(32, 10)
# 前向传播
output = layer.forward(x)
print(f"输入形状: {x.shape}")
print(f"输出形状: {output.shape}")
# 模拟梯度回传
grad_output = np.random.randn(32, 5)
grad_input = layer.backward(grad_output)
print(f"梯度输入形状: {grad_input.shape}")
print(f"权重梯度形状: {layer.grad_W.shape}")
print(f"偏置梯度形状: {layer.grad_b.shape}")
3.4.3 主成分分析与降维
**主成分分析(PCA)**是最常用的降维技术,它通过线性变换将高维数据投影到低维空间,同时保留数据的主要变异信息。
PCA的核心思想是找到数据方差最大的方向(主成分),这些方向彼此正交。
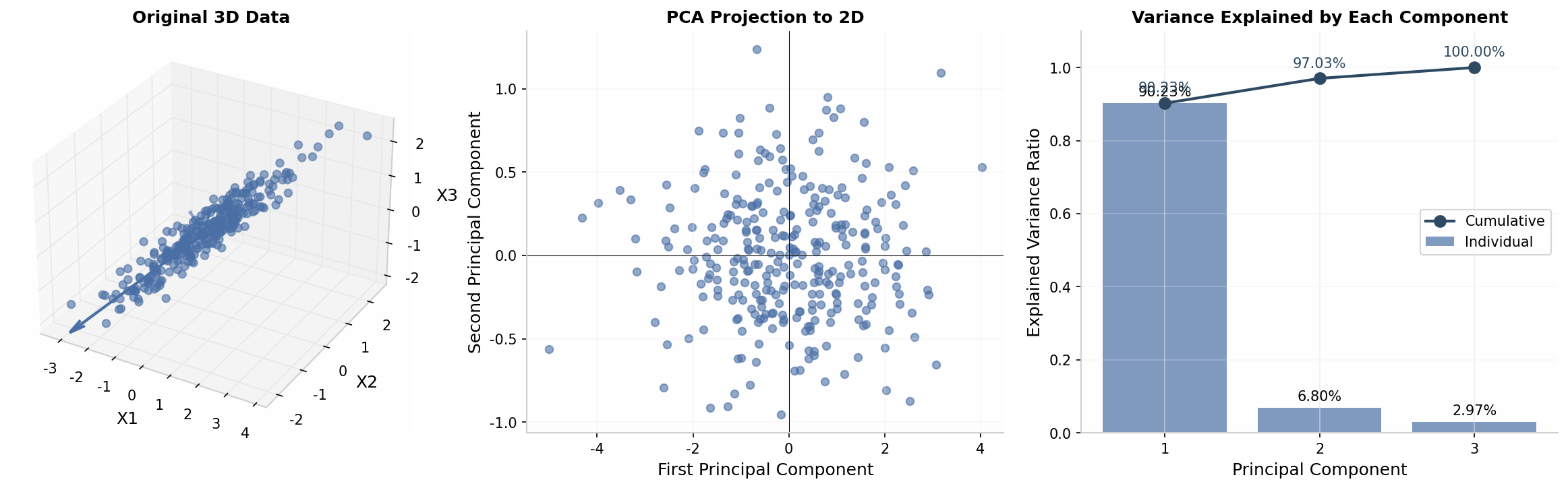
上图展示了PCA的工作流程:
- 原始3D数据:数据分布在一个近似平面上
- PCA投影到2D:数据被投影到前两个主成分张成的平面
- 方差解释:第一个主成分解释了90%以上的方差
import numpy as np
class PCA:
"""PCA实现"""
def __init__(self, n_components):
self.n_components = n_components
self.components_ = None
self.explained_variance_ = None
self.explained_variance_ratio_ = None
self.mean_ = None
def fit(self, X):
"""拟合PCA模型"""
# 数据中心化
self.mean_ = np.mean(X, axis=0)
X_centered = X - self.mean_
# 计算协方差矩阵
cov_matrix = np.cov(X_centered.T)
# 特征值分解
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
# 按特征值降序排序
idx = eigenvalues.argsort()[::-1]
eigenvalues = eigenvalues[idx]
eigenvectors = eigenvectors[:, idx]
# 保存结果
self.components_ = eigenvectors[:, :self.n_components].T
self.explained_variance_ = eigenvalues[:self.n_components]
self.explained_variance_ratio_ = eigenvalues / np.sum(eigenvalues)
return self
def transform(self, X):
"""将数据投影到主成分空间"""
X_centered = X - self.mean_
return X_centered @ self.components_.T
def fit_transform(self, X):
"""拟合并转换"""
self.fit(X)
return self.transform(X)
def inverse_transform(self, X_transformed):
"""将降维后的数据重构回原始空间"""
return X_transformed @ self.components_ + self.mean_
# 使用示例
np.random.seed(42)
# 生成高维数据(100个样本,50个特征)
n_samples, n_features = 100, 50
X = np.random.randn(n_samples, n_features)
# 添加一些结构(让数据具有低维内在结构)
true_dim = 5
basis = np.random.randn(n_features, true_dim)
X = X[:, :true_dim] @ basis.T + 0.1 * np.random.randn(n_samples, n_features)
# 应用PCA
pca = PCA(n_components=10)
X_pca = pca.fit_transform(X)
print(f"原始数据形状: {X.shape}")
print(f"降维后形状: {X_pca.shape}")
print(f"\n前10个主成分的方差解释比例:")
for i, ratio in enumerate(pca.explained_variance_ratio_[:10]):
cumsum = np.sum(pca.explained_variance_ratio_[:i+1])
print(f" PC{i+1}: {ratio:.4f} (累计: {cumsum:.4f})")
# 数据重构
X_reconstructed = pca.inverse_transform(X_pca)
reconstruction_error = np.mean((X - X_reconstructed) ** 2)
print(f"\n重构误差 (MSE): {reconstruction_error:.6f}")
PCA的数学原理:PCA的目标是找到一组正交基,使得数据在这些基上的投影方差最大化。这等价于对协方差矩阵进行特征值分解,特征向量就是主成分方向,特征值表示该方向上的方差。
PCA与SVD的关系:对数据中心化后的矩阵进行SVD分解:
其中的列向量就是主成分方向,的对角线元素就是特征值。实际应用中,SVD方法比直接计算协方差矩阵更数值稳定。
# PCA的SVD实现
class PCA_SVD:
"""基于SVD的PCA实现"""
def __init__(self, n_components):
self.n_components = n_components
self.components_ = None
self.singular_values_ = None
self.mean_ = None
def fit(self, X):
self.mean_ = np.mean(X, axis=0)
X_centered = X - self.mean_
# SVD分解
U, S, Vt = np.linalg.svd(X_centered, full_matrices=False)
self.components_ = Vt[:self.n_components]
self.singular_values_ = S
return self
def transform(self, X):
X_centered = X - self.mean_
return X_centered @ self.components_.T
def explained_variance_ratio_(self):
"""计算方差解释比例"""
return (self.singular_values_ ** 2) / np.sum(self.singular_values_ ** 2)
# 比较两种PCA实现
np.random.seed(42)
X = np.random.randn(200, 20)
pca_eig = PCA(n_components=5)
pca_svd = PCA_SVD(n_components=5)
X_eig = pca_eig.fit_transform(X)
X_svd = pca_svd.fit_transform(X)
print("特征值分解PCA的方差解释比例:")
print(pca_eig.explained_variance_ratio_[:5].round(4))
print("\nSVD PCA的方差解释比例:")
print(pca_svd.explained_variance_ratio_()[:5].round(4))
# 两种方法结果应该非常接近
print(f"\n两种方法结果差异: {np.linalg.norm(X_eig - X_svd):.6f}")
PCA的应用场景:
- 数据可视化:将高维数据降至2D或3D以便可视化
- 特征提取:去除冗余特征,保留主要信息
- 噪声去除:小方差成分通常对应噪声
- 数据压缩:减少存储和计算成本
# PCA用于数据可视化
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 应用PCA降至2D
pca_viz = PCA(n_components=2)
X_2d = pca_viz.fit_transform(X)
print(f"原始数据形状: {X.shape}")
print(f"降维后形状: {X_2d.shape}")
print(f"保留方差比例: {pca_viz.explained_variance_ratio_.sum():.2%}")
# 各主成分解释的方差
for i, ratio in enumerate(pca_viz.explained_variance_ratio_):
print(f" PC{i+1}: {ratio:.2%}")
3.4.4 注意力机制的矩阵视角
注意力机制是Transformer架构的核心,它通过计算查询(Query)、键(Key)和值(Value)之间的关系来动态地聚焦于输入的不同部分。
缩放点积注意力的公式为:
import numpy as np
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
缩放点积注意力
参数:
Q: Query矩阵, shape (batch_size, seq_len_q, d_k)
K: Key矩阵, shape (batch_size, seq_len_k, d_k)
V: Value矩阵, shape (batch_size, seq_len_v, d_v)
mask: 可选的掩码矩阵
返回:
output: 注意力输出
attention_weights: 注意力权重
"""
d_k = Q.shape[-1]
# 1. 计算Q和K的点积
scores = Q @ K.transpose(-2, -1) # (batch, seq_len_q, seq_len_k)
# 2. 缩放
scores = scores / np.sqrt(d_k)
# 3. 应用掩码(可选)
if mask is not None:
scores = scores + (mask * -1e9)
# 4. Softmax得到注意力权重
attention_weights = softmax(scores)
# 5. 与V相乘得到输出
output = attention_weights @ V
return output, attention_weights
def softmax(x):
"""数值稳定的softmax"""
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
# 注意力机制示例
np.random.seed(42)
# 模拟参数
batch_size = 2
seq_len = 4
d_k = 8
d_v = 8
# 创建Q, K, V矩阵
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
# 计算注意力
output, attention_weights = scaled_dot_product_attention(Q, K, V)
print(f"Query形状: {Q.shape}")
print(f"Key形状: {K.shape}")
print(f"Value形状: {V.shape}")
print(f"注意力权重形状: {attention_weights.shape}")
print(f"输出形状: {output.shape}")
# 验证注意力权重的性质
print(f"\n注意力权重每行和: {attention_weights[0].sum(axis=-1)}") # 应该接近1
# 可视化注意力权重
print(f"\n第一个batch的注意力权重矩阵:")
print(attention_weights[0].round(3))
# 多头注意力的概念
class MultiHeadAttention:
"""简化的多头注意力实现"""
def __init__(self, d_model, num_heads):
self.num_heads = num_heads
self.d_model = d_model
self.d_k = d_model // num_heads
# 初始化投影矩阵
self.W_q = np.random.randn(d_model, d_model) * 0.1
self.W_k = np.random.randn(d_model, d_model) * 0.1
self.W_v = np.random.randn(d_model, d_model) * 0.1
self.W_o = np.random.randn(d_model, d_model) * 0.1
def forward(self, Q, K, V):
batch_size = Q.shape[0]
# 线性投影
Q_proj = Q @ self.W_q # (batch, seq, d_model)
K_proj = K @ self.W_k
V_proj = V @ self.W_v
# 分割成多个头
Q_heads = Q_proj.reshape(batch_size, -1, self.num_heads, self.d_k).transpose(0, 2, 1, 3)
K_heads = K_proj.reshape(batch_size, -1, self.num_heads, self.d_k).transpose(0, 2, 1, 3)
V_heads = V_proj.reshape(batch_size, -1, self.num_heads, self.d_v).transpose(0, 2, 1, 3)
# 对每个头计算注意力
output, _ = scaled_dot_product_attention(
Q_heads, K_heads, V_heads
)
# 合并头并输出投影
output = output.transpose(0, 2, 1, 3).reshape(batch_size, -1, self.d_model)
output = output @ self.W_o
return output
# 测试多头注意力
mha = MultiHeadAttention(d_model=64, num_heads=8)
X = np.random.randn(2, 10, 64) # (batch, seq_len, d_model)
output = mha.forward(X, X, X)
print(f"\n多头注意力输出形状: {output.shape}")
位置编码:由于注意力机制本身不具有位置感知能力,Transformer使用位置编码来注入序列位置信息。最常见的是正弦位置编码:
def positional_encoding(seq_len, d_model):
"""生成正弦位置编码"""
position = np.arange(seq_len)[:, np.newaxis] # (seq_len, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe = np.zeros((seq_len, d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
# 生成位置编码
seq_len, d_model = 50, 64
pe = positional_encoding(seq_len, d_model)
print(f"位置编码形状: {pe.shape}")
print(f"位置编码示例 (前5个位置, 前8个维度):\n{pe[:5, :8].round(4)}")
# 验证位置编码的性质
# 不同位置的编码点积应该反映位置差异
pos_0 = pe[0]
pos_10 = pe[10]
pos_20 = pe[20]
print(f"\n位置0与位置10的点积: {np.dot(pos_0, pos_10):.4f}")
print(f"位置0与位置20的点积: {np.dot(pos_0, pos_20):.4f}")
注意力机制的直观理解:
- 查询(Query):当前需要关注什么信息
- 键(Key):每个输入位置提供的信息标识
- 值(Value):每个输入位置实际包含的信息内容
- 注意力权重:Query与Key的相似度,决定从每个Value中取多少信息
这种机制使得模型能够动态地关注输入的不同部分,是Transformer在NLP、视觉等领域取得成功的关键。
线性代数是理解现代AI算法的必备工具。本章介绍的向量、矩阵、线性变换、特征分析等概念,以及它们在数据表示、神经网络、降维和注意力机制中的应用,为后续学习深度学习奠定了数学基础。掌握这些概念的几何直觉和NumPy实现,将帮助你更好地理解和调试AI模型。
概率统计是人工智能的数学基石。从贝叶斯分类器到深度学习中的 dropout,从强化学习的探索策略到生成对抗网络,概率思维贯穿 AI 的各个分支。本章以"够用"为原则,聚焦于 AI 实践中最核心的概率统计知识,帮助读者建立概率化思考问题的能力。
4.1 概率论基础
4.1.1 随机事件与概率
随机事件是在一定条件下可能发生也可能不发生的事件。概率则是对随机事件发生可能性的度量,取值范围在 0 到 1 之间。
概率论建立在三条基本公理之上:
- 非负性:对于任意事件 ,有
- 规范性:必然事件的概率为 1,即
- 可列可加性:对于互斥事件 ,有
基于这些公理,可以推导出概率的重要性质:
- 加法公式:
- 对立事件:
- 单调性:若 ,则
在 AI 中,随机事件的概念无处不在。例如,垃圾邮件过滤器将"一封邮件是垃圾邮件"建模为随机事件,通过计算该事件的概率来决定是否拦截。
4.1.2 条件概率与贝叶斯定理
条件概率描述在已知某事件发生的条件下,另一事件发生的概率:
乘法公式是条件概率的直接推论:
全概率公式提供了计算复杂事件概率的方法。若 构成样本空间的一个划分,则:
贝叶斯定理是概率论中最具实践价值的工具之一,它建立了先验概率与后验概率之间的关系:
其中:
- 是先验概率(Prior):在观察到证据前的假设概率
- 是似然(Likelihood):假设成立时观察到证据的概率
- 是证据(Evidence):观察到证据的总概率
- 是后验概率(Posterior):观察到证据后的假设概率
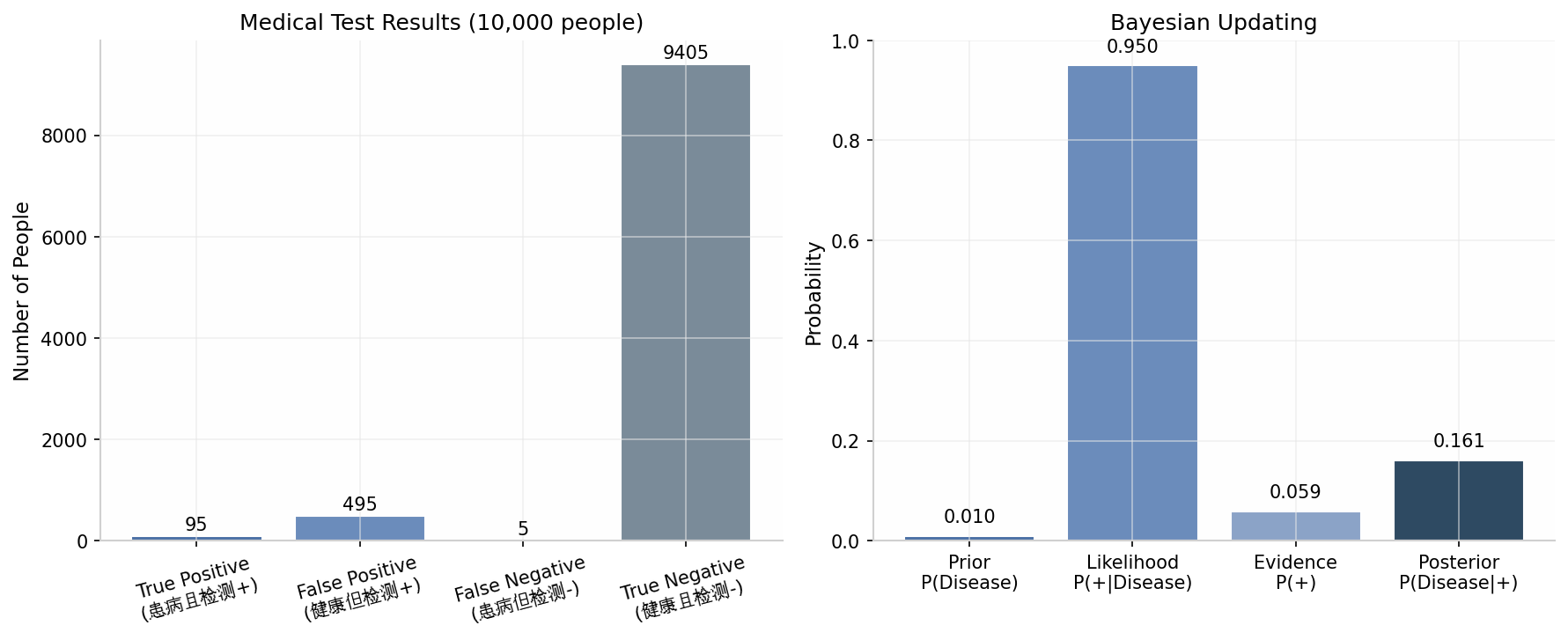
上图展示了一个经典的医学检测场景。假设某种疾病的患病率为 1%,检测的灵敏度(真阳性率)为 95%,特异度(真阴性率)为 95%。当一个人检测呈阳性时,实际患病的概率是多少?
通过贝叶斯定理计算:
这个结果令人惊讶:即使检测准确率很高,由于疾病本身罕见,阳性结果中真正患病的比例只有约 16%。这一原理在 AI 的医疗诊断系统中至关重要。
4.1.3 随机变量与分布
随机变量是将随机事件映射到实数的函数,分为离散型和连续型两类。
离散型随机变量取有限或可数无限个值,其概率分布用概率质量函数(PMF)描述:
连续型随机变量取不可数无限个值,其概率分布用概率密度函数(PDF)描述:
累积分布函数(CDF)统一描述两类随机变量:
随机变量的数字特征是概率建模的核心:
期望(均值)表示随机变量的"中心位置":
方差度量随机变量偏离均值的程度:
标准差是方差的平方根,与原始数据同量纲。
4.2 常用概率分布
4.2.1 离散型分布
| 分布 | PMF | 期望 | 方差 | 典型应用场景 |
|---|---|---|---|---|
| 伯努利 | 单次二元试验(如点击/不点击) | |||
| 二项 | 次独立二元试验的成功次数 | |||
| 泊松 | 单位时间/空间内随机事件发生次数 | |||
| 几何 | 首次成功所需的试验次数 | |||
| 类别 | - | - | 多类分类问题 |
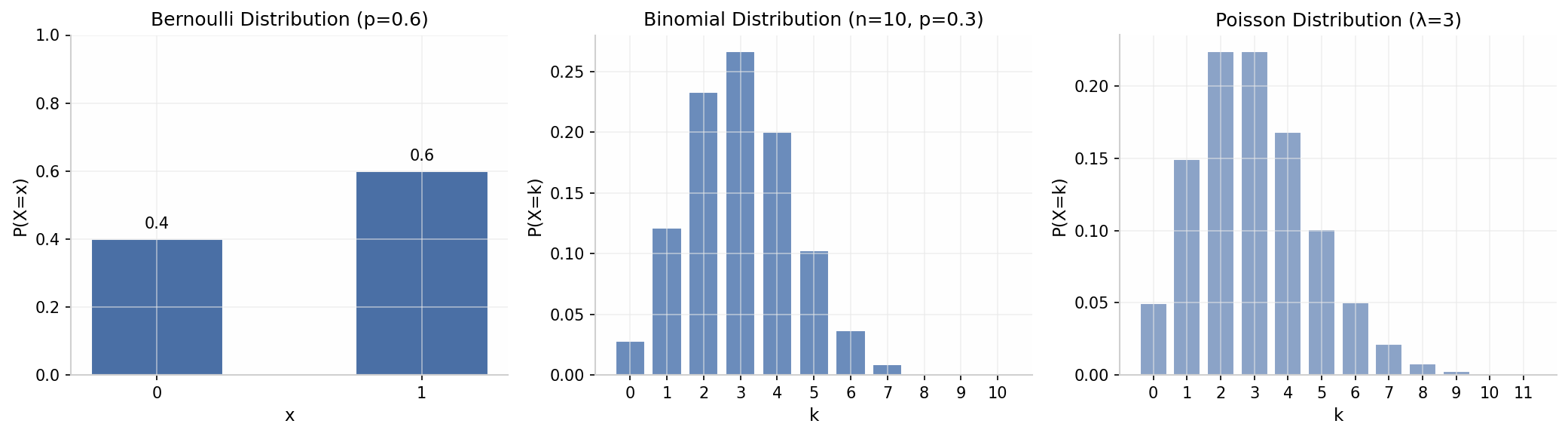
伯努利分布是最简单的离散分布,描述单次二元试验。在机器学习中,逻辑回归的输出可以看作伯努利分布的参数 。
二项分布是 次独立伯努利试验的成功次数。A/B 测试中,若每个用户的转化是伯努利试验,则总转化数服从二项分布。
泊松分布描述单位时间或空间内随机事件发生次数。网站访问量、客服中心接到的电话数、放射性衰变计数等都可以用泊松分布建模。泊松分布的一个重要性质是:当 很大、 很小时,。
4.2.2 连续型分布
| 分布 | 期望 | 方差 | 典型应用场景 | |
|---|---|---|---|---|
| 均匀 | 随机初始化、随机采样 | |||
| 正态 | 噪声建模、参数先验 | |||
| 指数 | 等待时间、设备寿命 | |||
| 拉普拉斯 | $\frac{1}{2b}e^{-\frac{ | x-\mu | }{b}}$ | |
| Beta | 概率的概率(共轭先验) |
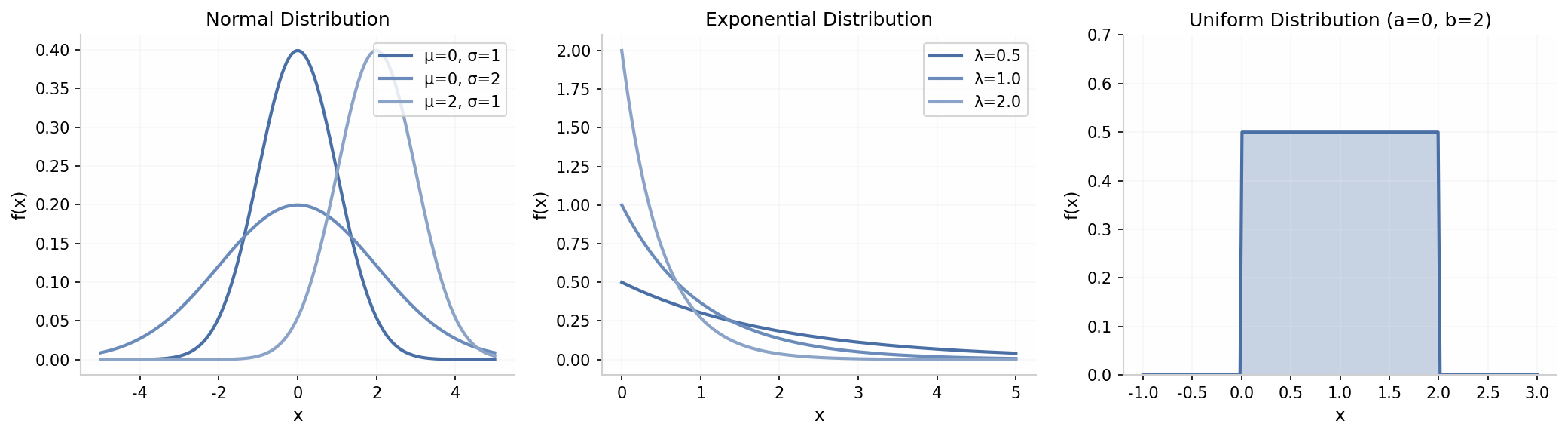
正态分布(高斯分布)是概率论中最重要的分布,原因有三:
- 中心极限定理:独立同分布随机变量之和趋于正态分布
- 最大熵原理:给定均值和方差,正态分布是熵最大的分布
- 数学便利性:正态分布具有良好的闭式性质,便于推导
在深度学习中,权重初始化常采用正态分布,批量归一化(Batch Normalization)利用正态分布稳定训练。
指数分布具有无记忆性:。这意味着已等待的时间不影响剩余等待时间的分布。在强化学习中,指数分布用于建模动作选择的时间间隔。
4.2.3 多元分布与协方差
多元正态分布是单变量正态分布的高维推广:
其中 是均值向量, 是协方差矩阵。
协方差度量两个随机变量的线性相关程度:
相关系数将协方差标准化到 区间:
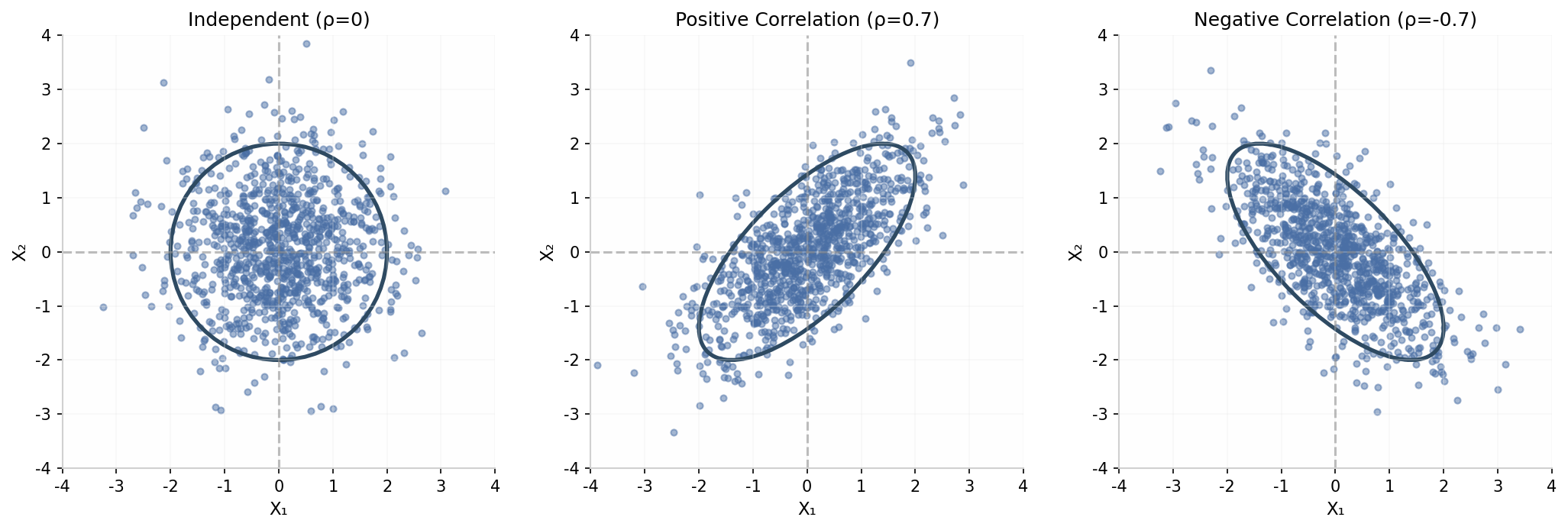
协方差矩阵 的结构决定了多元正态分布的形状:
- 对角元素 是各变量的方差
- 非对角元素 是变量 和 的协方差
- 当 为对角矩阵时,各变量独立
在机器学习中,协方差矩阵用于:
- 主成分分析(PCA):通过特征分解协方差矩阵实现降维
- 高斯过程:协方差函数(核函数)定义函数空间的相似性
- 投资组合优化:协方差矩阵描述资产收益的关联性
4.2.4 分布之间的关系
概率分布之间存在深刻的理论联系:
中心极限定理(Central Limit Theorem)是概率论最重要的定理之一:设 是独立同分布随机变量,,,则:
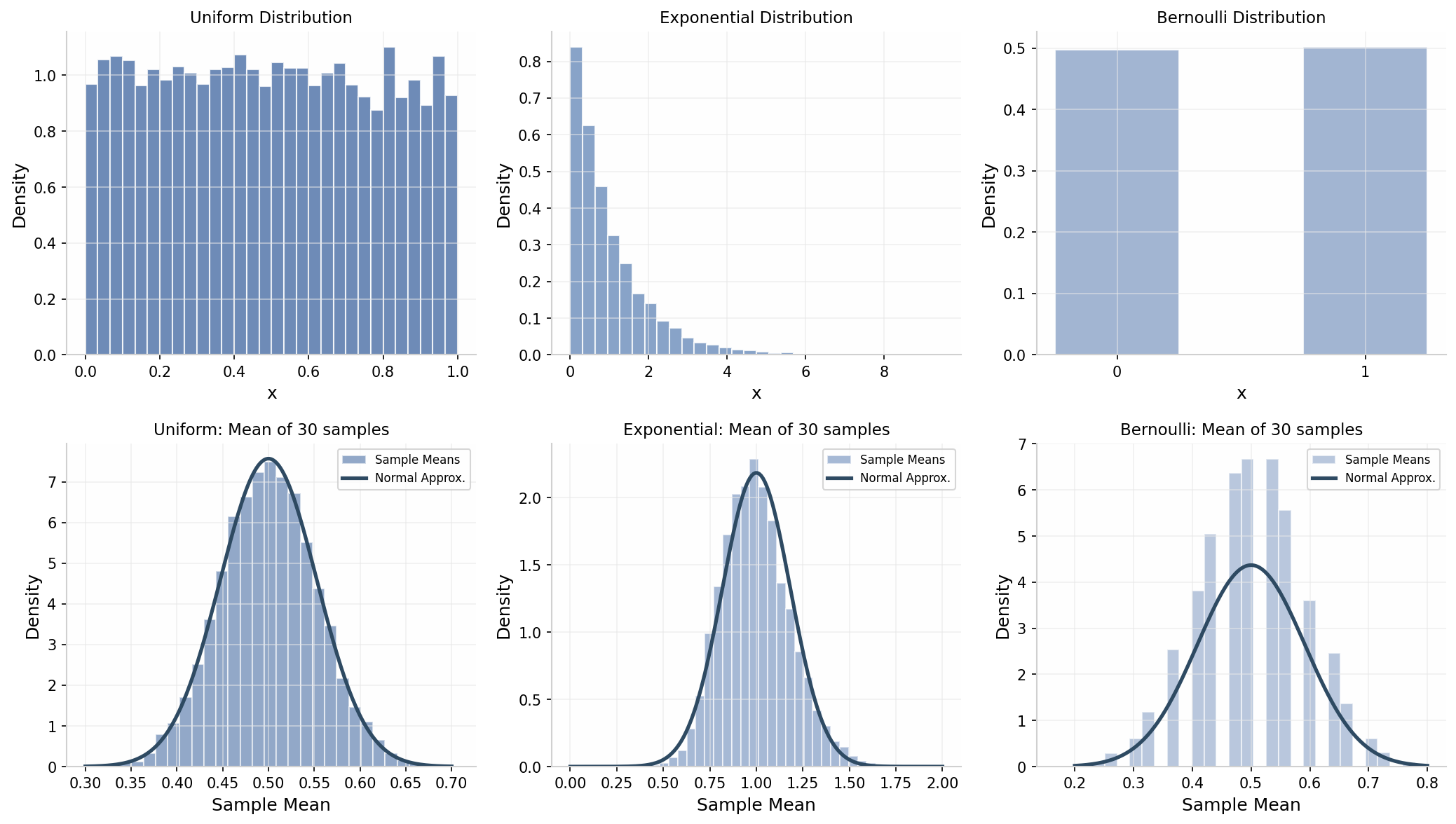
上图展示了中心极限定理的威力:无论原始分布是均匀、指数还是伯努利,样本均值的分布都趋于正态分布。
共轭先验是贝叶斯推断中的重要概念。当先验分布与似然函数共轭时,后验分布与先验属于同一族,大大简化了计算:
| 似然 | 共轭先验 | 后验 |
|---|---|---|
| 二项分布 | Beta 分布 | Beta 分布 |
| 正态分布(已知方差) | 正态分布 | 正态分布 |
| 泊松分布 | Gamma 分布 | Gamma 分布 |
| 多项分布 | Dirichlet 分布 | Dirichlet 分布 |
Dirichlet 分布是 Beta 分布在高维的推广,是主题模型(LDA)的核心组件。
4.3 统计推断基础
4.3.1 点估计与区间估计
点估计是用样本统计量估计总体参数。常用估计方法包括:
矩估计:用样本矩估计总体矩。例如,用样本均值估计总体均值,用样本方差估计总体方差。
最大似然估计(MLE):选择使观测数据出现概率最大的参数值。
估计量的评价标准:
- 无偏性:
- 有效性:方差最小的无偏估计
- 一致性:,当
区间估计给出参数的可能范围。置信区间表示:若重复抽样多次,有 比例的区间包含真实参数。
对于正态总体均值, 置信区间为:
4.3.2 假设检验原理
假设检验是统计推断的核心工具,用于判断样本数据是否支持某个统计假设。
基本步骤:
- 建立原假设 和备择假设
- 选择检验统计量
- 确定显著性水平 (通常为 0.05)
- 计算 p 值或临界值
- 做出决策
p 值是在原假设成立时,观察到当前或更极端结果的概率。若 ,拒绝原假设。
常见检验方法:
- Z 检验:大样本均值检验
- t 检验:小样本均值检验
- 卡方检验:分类变量独立性检验
- F 检验:方差比较检验
在机器学习中,假设检验用于:
- 比较两个模型的性能差异(配对 t 检验)
- 特征选择的显著性检验
- A/B 测试中的效果验证
4.3.3 最大似然估计
最大似然估计(Maximum Likelihood Estimation, MLE)是参数估计的最重要方法。其核心思想是:选择使观测数据出现概率最大的参数值。
给定独立同分布样本 ,似然函数为:
通常对似然函数取对数,得到对数似然函数:
MLE 通过求解优化问题获得:
正态分布的 MLE:
设 ,则:
对 求导并令其为零:
对 求导并令其为零:
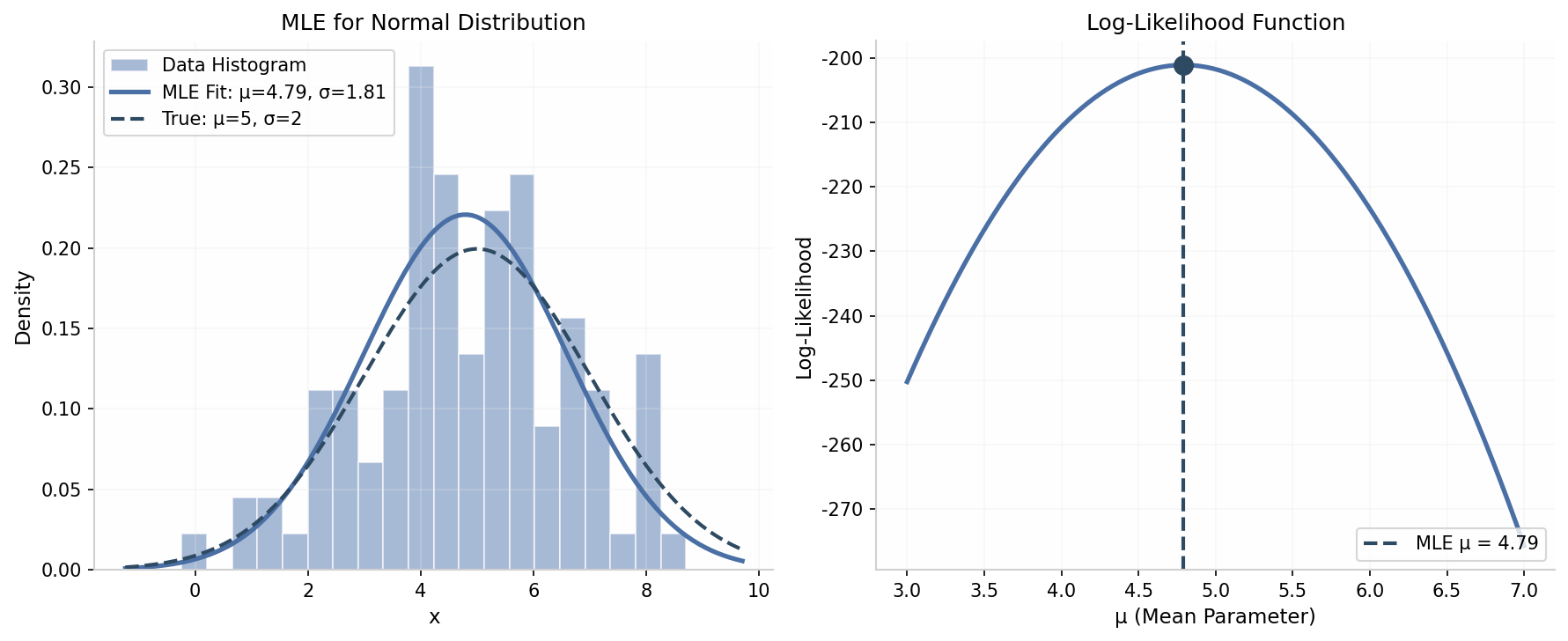
上图展示了 MLE 的工作过程:左图显示数据直方图和拟合的正态分布曲线,右图展示对数似然函数随均值参数的变化,最大值点即为 MLE 估计。
Python 实现:
import numpy as np
from scipy import stats
def mle_normal(data):
"""
正态分布的最大似然估计
参数:
data: 观测数据数组
返回:
mu_mle: 均值的 MLE 估计
sigma_mle: 标准差的 MLE 估计
"""
n = len(data)
# 均值估计
mu_mle = np.mean(data)
# 方差估计(注意:MLE 使用 n 而非 n-1)
sigma_mle = np.sqrt(np.mean((data - mu_mle)**2))
return mu_mle, sigma_mle
# 示例使用
np.random.seed(42)
true_mu, true_sigma = 5, 2
sample_data = np.random.normal(true_mu, true_sigma, 100)
mu_est, sigma_est = mle_normal(sample_data)
print(f"真实参数: μ={true_mu}, σ={true_sigma}")
print(f"MLE 估计: μ={mu_est:.4f}, σ={sigma_est:.4f}")
# 计算对数似然
log_likelihood = np.sum(stats.norm.logpdf(sample_data, mu_est, sigma_est))
print(f"对数似然值: {log_likelihood:.2f}")
逻辑回归的 MLE:
逻辑回归通过 MLE 估计参数。设 ,则:
对数似然函数为:
最大化对数似然等价于最小化交叉熵损失,这是逻辑回归的理论基础。
4.4 概率统计在 AI 中的应用
4.4.1 损失函数的概率解释
机器学习中的损失函数往往有深刻的概率解释。理解这种联系有助于选择合适的损失函数和设计新的优化目标。
MSE 损失与正态分布:
假设观测值 与预测值 的关系为:
则似然函数为:
对数似然为:
最大化对数似然等价于最小化 MSE:
MAE 损失与拉普拉斯分布:
若噪声服从拉普拉斯分布:
则最大化似然等价于最小化 MAE:
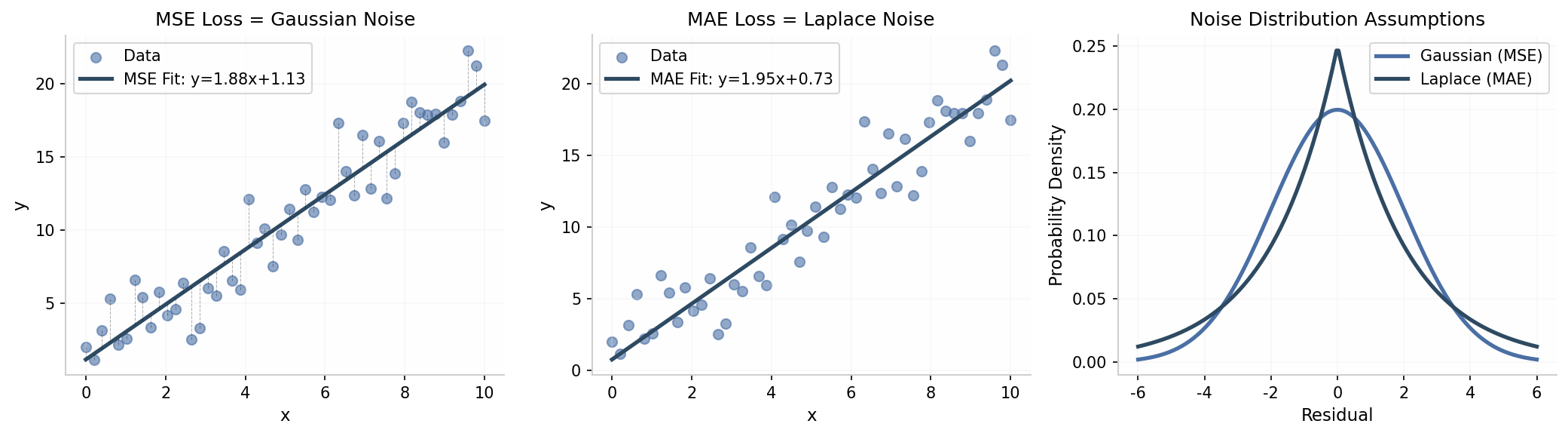
上图对比了 MSE 和 MAE 的拟合效果。MSE 对异常值敏感(平方惩罚),而 MAE 更鲁棒。右图显示高斯分布(MSE)比拉普拉斯分布(MAE)有更轻的尾部。
交叉熵损失与伯努利分布:
对于二分类问题,设真实标签 ,预测概率为 。则似然为:
负对数似然即为交叉熵损失:
KL 散度与信息论:
KL 散度(Kullback-Leibler divergence)度量两个概率分布的差异:
在变分自编码器(VAE)中,ELBO(Evidence Lower Bound)包含重构误差和 KL 散度项,后者约束隐变量分布接近先验。
4.4.2 正则化的贝叶斯视角
正则化技术是防止过拟合的关键手段,从贝叶斯角度看,正则化等价于引入参数的先验分布。
L2 正则化与高斯先验:
假设参数 服从独立同分布的高斯先验:
则后验概率为:
取负对数:
这与 L2 正则化等价,其中 。先验方差越小(对参数约束越强),正则化强度越大。
L1 正则化与拉普拉斯先验:
若参数服从拉普拉斯先验:
则 MAP 估计等价于 L1 正则化:
其中 。
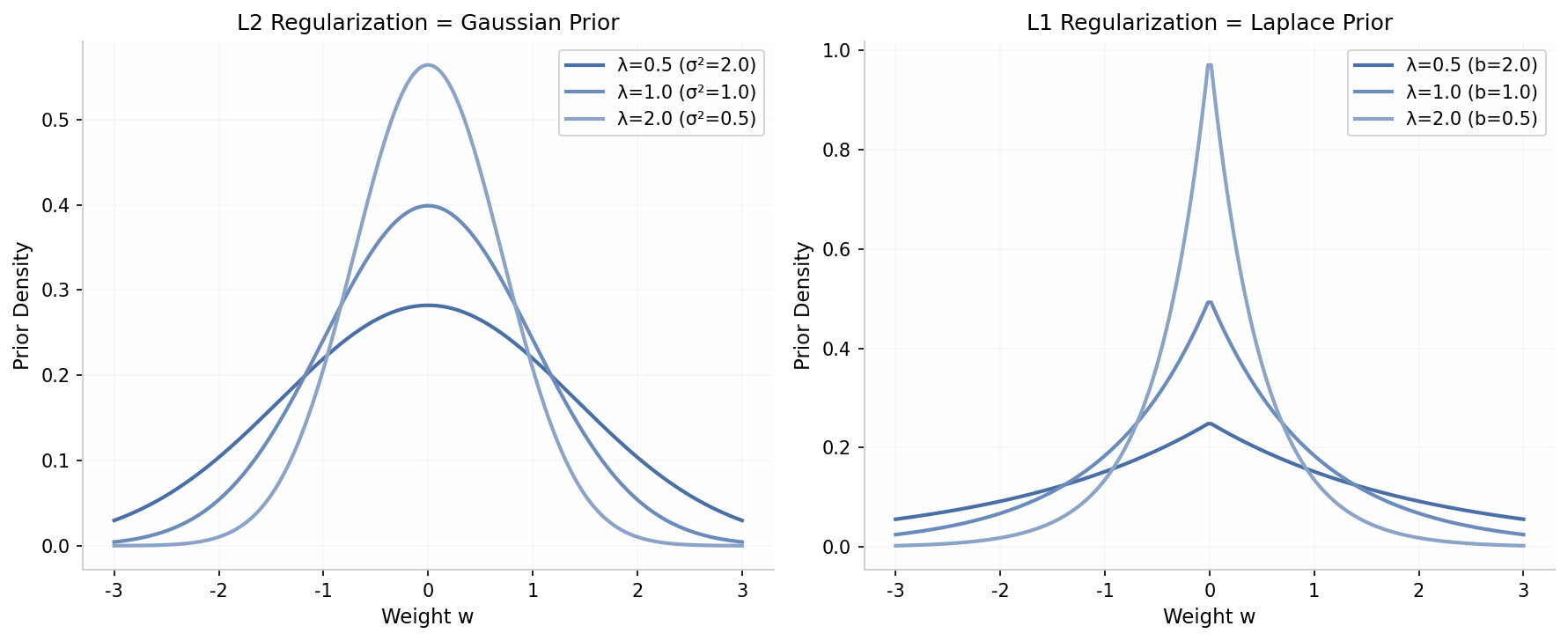
上图展示了不同正则化强度对应的先验分布。L2 的高斯先验倾向于产生小而分散的权重,L1 的拉普拉斯先验(尖峰分布)倾向于产生稀疏解(部分权重恰好为零)。
Dropout 的贝叶斯解释:
Dropout 可以解释为对网络权重的近似贝叶斯推断。训练时随机丢弃神经元等价于对权重进行变分近似,预测时的权重缩放等价于对多个网络进行模型平均。
4.4.3 生成模型与概率建模
生成模型学习数据的概率分布 ,从而能够生成新的样本。这是概率统计在 AI 中最激动人心的应用之一。
朴素贝叶斯分类器:
基于贝叶斯定理和特征条件独立假设:
尽管"朴素"的独立性假设很少成立,朴素贝叶斯在文本分类等任务上表现优异。
高斯混合模型(GMM):
假设数据来自 个高斯分布的混合:
EM 算法用于估计 GMM 参数,是聚类分析的经典方法。
变分自编码器(VAE):
VAE 学习隐变量模型 。通过变分推断,引入编码器 近似后验,优化 ELBO:
生成对抗网络(GAN):
GAN 通过对抗训练学习生成分布。生成器 试图欺骗判别器 ,判别器试图区分真实样本和生成样本。理论上,当判别器最优时,生成器最小化生成分布与真实分布的 JS 散度。
扩散模型:
扩散模型通过逐步去噪学习数据分布。前向过程逐步添加高斯噪声,反向过程学习去噪。扩散模型在图像生成领域取得了最先进的成果。
4.4.4 不确定性量化
深度学习模型不仅要给出预测,还要知道"自己不知道什么"。不确定性量化在安全关键应用中至关重要。
认知不确定性(Epistemic Uncertainty):源于模型参数的不确定性,可以通过更多数据减少。贝叶斯神经网络通过后验分布 建模认知不确定性。
偶然不确定性(Aleatoric Uncertainty):源于数据的固有噪声,无法通过更多数据消除。可以通过让网络同时输出预测均值和方差来建模。
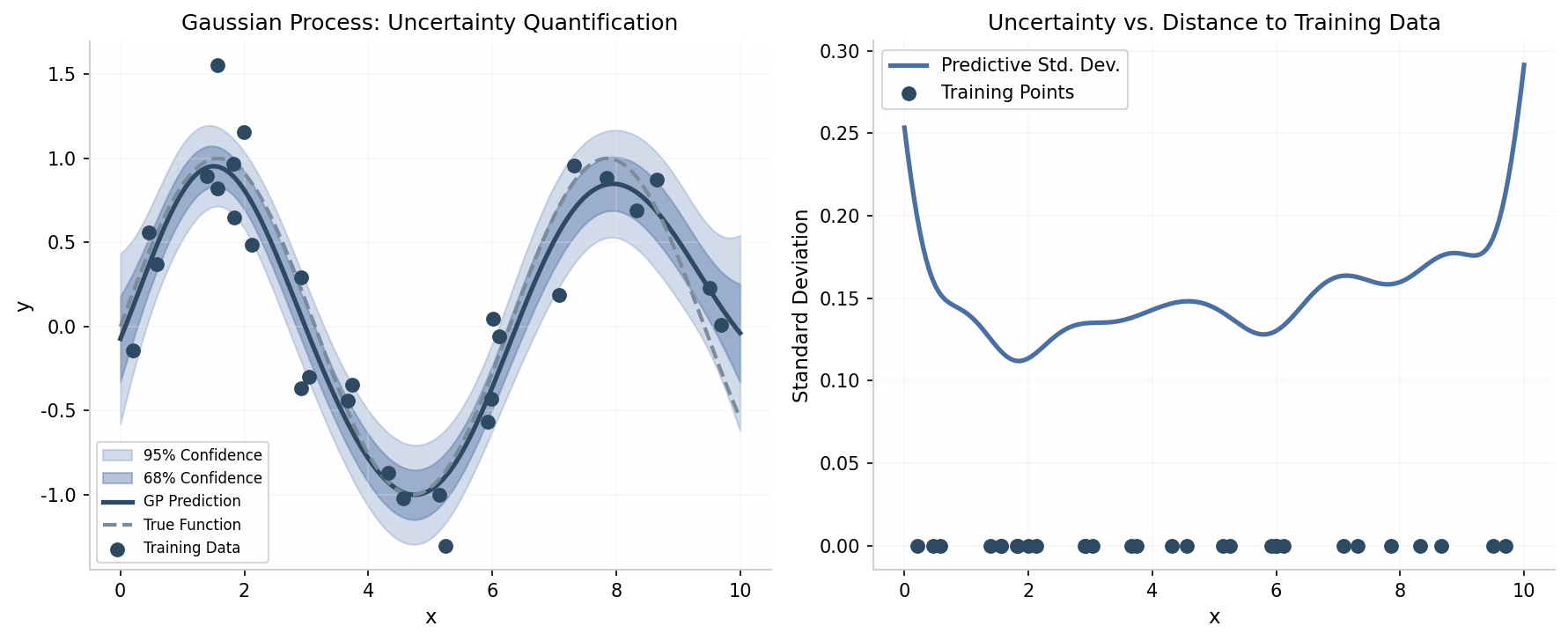
上图展示了高斯过程中的不确定性量化。左图显示预测均值和置信区间,右图显示预测标准差随输入位置的变化。远离训练数据的区域不确定性更大,这是认知不确定性的典型表现。
蒙特卡洛 Dropout:
在测试时保持 Dropout 开启,进行多次前向传播,预测结果的方差即为不确定性估计。这是一种计算高效的近似贝叶斯推断方法。
集成方法:
训练多个模型,预测结果的方差反映认知不确定性。深度集成(Deep Ensemble)在实践中表现优异,但计算成本较高。
贝叶斯神经网络:
对网络权重引入先验,通过变分推断或 MCMC 方法近似后验分布。尽管计算复杂,BNN 提供了最严谨的不确定性量化框架。
概率统计为人工智能提供了坚实的数学基础。从贝叶斯定理到最大似然估计,从损失函数的概率解释到正则化的贝叶斯视角,概率思维贯穿 AI 的方方面面。掌握这些核心概念,将帮助读者更深入地理解机器学习算法的工作原理,并在实践中做出更明智的建模决策。
优化与泛化是机器学习的两大核心问题。优化关注如何高效地找到模型参数使得损失函数最小化,而泛化则关注模型在未见过的数据上的表现能力。本章将深入探讨这两大问题,从理论基础到实践技巧,为读者构建完整的知识体系。
5.1 优化基础
5.1.1 优化问题建模:目标函数、约束条件
机器学习的训练过程本质上是一个优化问题。给定训练数据集 ,我们需要找到一组模型参数 ,使得损失函数 最小化:
目标函数(也称为损失函数或代价函数)衡量模型预测与真实值之间的差距。常见的目标函数包括:
-
均方误差(MSE):用于回归问题
-
交叉熵损失:用于分类问题
-
正则化损失:在原始损失基础上添加正则化项
约束条件在某些优化问题中起着关键作用。约束优化问题的一般形式为:
\min_{\boldsymbol{\theta}} \quad & f(\boldsymbol{\theta}) \\ \text{s.t.} \quad & g_i(\boldsymbol{\theta}) \leq 0, \quad i = 1, \ldots, m \\ & h_j(\boldsymbol{\theta}) = 0, \quad j = 1, \ldots, p \end{aligned}$$ 在实际应用中,约束条件可能包括参数非负约束、参数和为1的约束(如概率分布),或神经网络权重的范数约束等。 ### 5.1.2 凸优化与凸集:凸函数性质、局部最优即全局最优 **凸集**是优化理论中的重要概念。集合 $C \subseteq \mathbb{R}^d$ 是凸集,当且仅当对于任意 $\mathbf{x}, \mathbf{y} \in C$ 和任意 $\lambda \in [0, 1]$,都有: $$\lambda \mathbf{x} + (1-\lambda) \mathbf{y} \in C$$ 直观地说,凸集中任意两点之间的线段完全包含在该集合内。 **凸函数**定义在凸集上。函数 $f: C \to \mathbb{R}$ 是凸函数,当且仅当对于任意 $\mathbf{x}, \mathbf{y} \in C$ 和任意 $\lambda \in [0, 1]$: $$f(\lambda \mathbf{x} + (1-\lambda) \mathbf{y}) \leq \lambda f(\mathbf{x}) + (1-\lambda) f(\mathbf{y})$$ 凸函数具有以下重要性质: 1. **局部最优即全局最优**:对于凸函数,任何局部最小值都是全局最小值。这一性质极大地简化了优化问题的求解。 2. **Jensen不等式**:对于凸函数 $f$ 和随机变量 $X$,有 $f(\mathbb{E}[X]) \leq \mathbb{E}[f(X)]$。 3. **一阶条件**:可微凸函数满足 $f(\mathbf{y}) \geq f(\mathbf{x}) + \nabla f(\mathbf{x})^T(\mathbf{y} - \mathbf{x})$。 4. **二阶条件**:二阶可微函数 $f$ 是凸函数当且仅当其Hessian矩阵半正定,即 $\nabla^2 f(\mathbf{x}) \succeq 0$。 **凸优化问题**是指最小化凸函数(或最大化凹函数)的问题,且可行域为凸集。凸优化问题的优势在于: - 存在多项式时间算法 - 没有局部最优的困扰 - 对偶理论提供了强大的分析工具 - 可以处理大规模问题 然而,深度学习中的优化问题通常是非凸的,这使得优化变得更加复杂。尽管如此,凸优化的理论和方法仍然为理解非凸优化提供了重要基础。 ### 5.1.3 梯度与方向导数:梯度下降原理 **梯度**是多变量函数的一阶导数推广。对于函数 $f: \mathbb{R}^d \to \mathbb{R}$,其梯度定义为: $$\nabla f(\mathbf{x}) = \left[\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \ldots, \frac{\partial f}{\partial x_d}\right]^T$$ 梯度指向函数增长最快的方向,其模长表示该方向的增长率。 **方向导数**衡量函数沿特定方向的变化率。函数 $f$ 在点 $\mathbf{x}$ 沿方向 $\mathbf{v}$(单位向量)的方向导数为: $$D_{\mathbf{v}} f(\mathbf{x}) = \lim_{h \to 0} \frac{f(\mathbf{x} + h\mathbf{v}) - f(\mathbf{x})}{h} = \nabla f(\mathbf{x})^T \mathbf{v}$$ 方向导数与梯度的关系表明,当 $\mathbf{v}$ 与梯度方向一致时,方向导数最大;当 $\mathbf{v}$ 与梯度方向相反时,方向导数最小(即下降最快)。 **梯度下降原理**基于这一观察:为了最小化函数,我们应该沿着梯度的反方向移动。梯度下降算法的迭代公式为: $$\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta \nabla L(\boldsymbol{\theta}_t)$$ 其中 $\eta > 0$ 是学习率(learning rate),控制每次更新的步长。 梯度下降的收敛性分析表明,对于具有 $L$-Lipschitz连续梯度的凸函数,使用适当的学习率,梯度下降具有 $O(1/T)$ 的收敛速率: $$L(\boldsymbol{\theta}_T) - L(\boldsymbol{\theta}^*) \leq \frac{\|\boldsymbol{\theta}_0 - \boldsymbol{\theta}^*\|^2}{2\eta T}$$ 对于强凸函数(满足 $L(\mathbf{y}) \geq L(\mathbf{x}) + \nabla L(\mathbf{x})^T(\mathbf{y}-\mathbf{x}) + \frac{\mu}{2}\|\mathbf{y}-\mathbf{x}\|^2$),梯度下降可以达到线性收敛速率 $O(\rho^T)$,其中 $\rho < 1$。 ## 5.2 梯度下降及其变体 ### 5.2.1 批量梯度下降:全数据集更新 **批量梯度下降**(Batch Gradient Descent, BGD)使用整个训练数据集计算梯度: $$\nabla L(\boldsymbol{\theta}) = \frac{1}{n} \sum_{i=1}^n \nabla L_i(\boldsymbol{\theta})$$ 其中 $L_i(\boldsymbol{\theta})$ 是第 $i$ 个样本的损失。 批量梯度下降的优点包括: 1. **梯度估计准确**:使用全部数据,梯度估计无噪声 2. **收敛稳定**:目标函数单调递减(对于适当的学习率) 3. **理论保证强**:收敛性分析相对完整 然而,批量梯度下降也存在明显缺点: 1. **计算成本高**:每次迭代需要遍历整个数据集 2. **内存需求大**:需要加载全部数据 3. **无法在线学习**:不适用于数据流场景 对于大规模数据集,批量梯度下降的计算效率往往难以接受。例如,当训练数据包含数百万样本时,单次梯度计算可能需要数分钟甚至更长时间。 ### 5.2.2 随机梯度下降:单样本更新、收敛性 **随机梯度下降**(Stochastic Gradient Descent, SGD)每次迭代只使用一个样本来估计梯度: $$\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta_t \nabla L_i(\boldsymbol{\theta}_t)$$ 其中 $i$ 是从 $\{1, \ldots, n\}$ 中随机采样的索引。 SGD的核心思想是用单个样本的梯度 $\nabla L_i(\boldsymbol{\theta})$ 作为整体梯度 $\nabla L(\boldsymbol{\theta})$ 的无偏估计: $$\mathbb{E}_i[\nabla L_i(\boldsymbol{\theta})] = \nabla L(\boldsymbol{\theta})$$ SGD的优点包括: 1. **计算效率高**:每次迭代只需处理一个样本 2. **内存需求低**:无需加载全部数据 3. **支持在线学习**:可以处理数据流 4. **可能逃离局部最优**:噪声有助于跳出鞍点和浅层局部最优 SGD的收敛性分析需要考虑梯度估计的方差。对于凸函数,使用递减学习率 $\eta_t = O(1/\sqrt{t})$,SGD可以达到 $O(1/\sqrt{T})$ 的收敛速率。虽然比批量梯度下降的 $O(1/T)$ 慢,但每次迭代的计算成本大大降低,使得SGD在大规模问题上更具优势。 SGD的主要挑战是梯度估计的高方差导致更新方向不稳定。这在实践中表现为损失函数的剧烈波动,影响收敛速度。 ### 5.2.3 动量方法与自适应学习率:Momentum、RMSprop **动量方法**(Momentum)通过引入速度变量来平滑SGD的更新方向: $$\begin{aligned} \mathbf{v}_{t+1} &= \gamma \mathbf{v}_t + \eta \nabla L(\boldsymbol{\theta}_t) \\ \boldsymbol{\theta}_{t+1} &= \boldsymbol{\theta}_t - \mathbf{v}_{t+1} \end{aligned}$$ 其中 $\gamma \in [0, 1)$ 是动量系数,通常设置为0.9。动量方法可以理解为将过去梯度的指数加权平均作为当前更新方向。 动量的物理直觉是:将参数更新视为小球在损失曲面上滚动,动量使得小球在一致的方向上加速,而在振荡方向上减速。这带来以下好处: 1. **加速收敛**:在梯度方向一致时加速前进 2. **抑制振荡**:在梯度方向变化时减小更新幅度 3. **逃离局部最优**:动量有助于越过浅层局部最优 **Nesterov加速梯度**(NAG)是动量方法的改进版本,它在计算梯度前先按动量方向"预判"一步: $$\begin{aligned} \mathbf{v}_{t+1} &= \gamma \mathbf{v}_t + \eta \nabla L(\boldsymbol{\theta}_t - \gamma \mathbf{v}_t) \\ \boldsymbol{\theta}_{t+1} &= \boldsymbol{\theta}_t - \mathbf{v}_{t+1} \end{aligned}$$ Nesterov动量在理论上具有更好的收敛保证,在实践中通常表现更优。 **自适应学习率方法**为每个参数单独调整学习率。**AdaGrad**是最早的自适应方法之一: $$\begin{aligned} \mathbf{g}_t &= \nabla L(\boldsymbol{\theta}_t) \\ \mathbf{G}_t &= \mathbf{G}_{t-1} + \mathbf{g}_t \odot \mathbf{g}_t \\ \boldsymbol{\theta}_{t+1} &= \boldsymbol{\theta}_t - \frac{\eta}{\sqrt{\mathbf{G}_t} + \epsilon} \odot \mathbf{g}_t \end{aligned}$$ 其中 $\odot$ 表示逐元素乘法,除法和开方也是逐元素操作。AdaGrad为频繁更新的参数减小学习率,为稀疏更新的参数增大学习率。 AdaGrad的主要问题是学习率单调递减,可能导致训练过早停止。**RMSprop**通过引入指数衰减来解决这一问题: $$\begin{aligned} \mathbf{g}_t &= \nabla L(\boldsymbol{\theta}_t) \\ \mathbf{E}[\mathbf{g}^2]_t &= \beta \mathbf{E}[\mathbf{g}^2]_{t-1} + (1-\beta) \mathbf{g}_t \odot \mathbf{g}_t \\ \boldsymbol{\theta}_{t+1} &= \boldsymbol{\theta}_t - \frac{\eta}{\sqrt{\mathbf{E}[\mathbf{g}^2]_t} + \epsilon} \odot \mathbf{g}_t \end{aligned}$$ 其中 $\beta$ 通常设置为0.9。RMSprop在深度学习的早期应用中表现出色,成为许多实际应用的首选优化器。 ### 5.2.4 常用优化器对比:Adam、AdamW、SGD **Adam**(Adaptive Moment Estimation)结合了动量和自适应学习率的优点,是目前深度学习中最流行的优化器之一。Adam维护两个指数移动平均: $$\begin{aligned} \mathbf{m}_t &= \beta_1 \mathbf{m}_{t-1} + (1-\beta_1) \mathbf{g}_t \\ \mathbf{v}_t &= \beta_2 \mathbf{v}_{t-1} + (1-\beta_2) \mathbf{g}_t \odot \mathbf{g}_t \end{aligned}$$ 由于初始值为零,Adam对这两个估计进行偏差修正: $$\begin{aligned} \hat{\mathbf{m}}_t &= \frac{\mathbf{m}_t}{1-\beta_1^t} \\ \hat{\mathbf{v}}_t &= \frac{\mathbf{v}_t}{1-\beta_2^t} \end{aligned}$$ 最终更新公式为: $$\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \frac{\eta}{\sqrt{\hat{\mathbf{v}}_t} + \epsilon} \odot \hat{\mathbf{m}}_t$$ Adam的默认超参数为 $\beta_1 = 0.9$,$\beta_2 = 0.999$,$\epsilon = 10^{-8}$。Adam的优势在于: 1. **自适应学习率**:每个参数有独立的学习率 2. **动量加速**:利用梯度的一阶矩估计 3. **偏差修正**:解决初始阶段的偏差问题 4. **超参数鲁棒性**:对超参数选择不敏感 以下是从零实现Adam优化器的Python代码: ```python import numpy as np class AdamOptimizer: """Adam优化器从零实现""" def __init__(self, params, lr=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8): self.params = params self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.epsilon = epsilon self.t = 0 # 初始化一阶矩和二阶矩 self.m = {name: np.zeros_like(param) for name, param in params.items()} self.v = {name: np.zeros_like(param) for name, param in params.items()} def step(self, gradients): """执行一次参数更新""" self.t += 1 for name in self.params: g = gradients[name] # 更新一阶矩估计(动量) self.m[name] = self.beta1 * self.m[name] + (1 - self.beta1) * g # 更新二阶矩估计(自适应学习率) self.v[name] = self.beta2 * self.v[name] + (1 - self.beta2) * (g ** 2) # 偏差修正 m_hat = self.m[name] / (1 - self.beta1 ** self.t) v_hat = self.v[name] / (1 - self.beta2 ** self.t) # 参数更新 self.params[name] -= self.lr * m_hat / (np.sqrt(v_hat) + self.epsilon) return self.params ``` **AdamW**是Adam的重要改进版本,它将权重衰减(L2正则化)与梯度更新解耦。在原始Adam中,L2正则化与自适应学习率相互作用,导致正则化效果不佳。AdamW将权重衰减直接应用于参数更新: $$\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta \left(\frac{\hat{\mathbf{m}}_t}{\sqrt{\hat{\mathbf{v}}_t} + \epsilon} + \lambda \boldsymbol{\theta}_t\right)$$ 其中 $\lambda$ 是权重衰减系数。AdamW在训练大规模模型时通常优于Adam,特别是在Transformer等架构中。 **SGD with Momentum**虽然简单,但在许多任务上仍然表现出色,尤其是计算机视觉任务。经过精心调参的SGD往往能达到与Adam相当甚至更好的性能,且泛化能力更强。  *图5-1:梯度下降、动量法和Adam优化器在二次函数上的优化轨迹对比。左图展示了优化路径,右图展示了收敛速度。Adam结合了动量的平滑性和自适应学习率的灵活性。*  *图5-2:在Rosenbrock函数(经典的优化测试函数)上的优化表现。该函数具有狭窄弯曲的山谷,对优化算法构成挑战。Adam展现出最快的收敛速度。*  *图5-3:学习率对梯度下降收敛的影响。左图显示适当的学习率可以确保稳定收敛;右图显示学习率过大导致发散。选择合适的学习率是优化成功的关键。* **表5-1:常用优化器特性对比** | 优化器 | 动量 | 自适应学习率 | 内存需求 | 收敛速度 | 泛化能力 | 推荐场景 | |:-------|:-----|:-------------|:---------|:---------|:---------|:---------| | SGD | 否 | 否 | 低 | 慢 | 强 | 大规模CV任务 | | Momentum | 是 | 否 | 低 | 中等 | 强 | 通用场景 | | AdaGrad | 否 | 是 | 中 | 中等 | 中等 | 稀疏梯度 | | RMSprop | 否 | 是 | 中 | 快 | 中等 | RNN训练 | | Adam | 是 | 是 | 高 | 快 | 中等 | 通用首选 | | AdamW | 是 | 是 | 高 | 快 | 较强 | 大规模模型 | 选择优化器时需要考虑任务特性、模型规模、数据分布等因素。Adam通常是一个安全的起点,但对于特定任务,其他优化器可能表现更好。实践中,优化器的选择和超参数调优往往需要结合具体问题进行实验验证。 ## 5.3 反向传播算法 ### 5.3.1 计算图与链式法则:自动微分原理 **计算图**是表达数学运算的有向无环图。图中的节点表示变量(输入、参数、中间结果)或操作(加法、乘法、激活函数等),边表示数据依赖关系。计算图提供了一种结构化的方式来理解和实现梯度计算。 考虑一个简单的函数:$y = f(x_1, x_2) = (x_1 + x_2) \cdot x_2$。其计算图包含: - 输入节点:$x_1$, $x_2$ - 中间节点:$a = x_1 + x_2$ - 输出节点:$y = a \cdot x_2$ **链式法则**是反向传播算法的数学基础。对于复合函数 $y = f(g(x))$,链式法则表明: $$\frac{\partial y}{\partial x} = \frac{\partial y}{\partial g} \cdot \frac{\partial g}{\partial x}$$ 对于多变量函数,链式法则推广为: $$\frac{\partial y}{\partial x} = \sum_i \frac{\partial y}{\partial u_i} \cdot \frac{\partial u_i}{\partial x}$$ 其中 $u_i$ 是中间变量。 **自动微分**(Automatic Differentiation, AD)是利用链式法则自动计算梯度的技术。与符号微分(产生解析表达式)和数值微分(使用有限差分)不同,自动微分通过追踪计算图中的操作来精确计算梯度。 自动微分有两种主要模式: 1. **前向模式**(Forward Mode):从输入开始,沿着计算图正向传播导数 2. **反向模式**(Reverse Mode):从输出开始,沿着计算图反向传播梯度 反向模式自动微分(即反向传播)在神经网络训练中更为高效,因为它只需要一次前向传播和一次反向传播即可计算所有参数的梯度,无论参数数量多少。 ### 5.3.2 反向传播的前向与反向:梯度计算流程 反向传播算法包含两个阶段: **前向传播阶段**: 1. 从输入层开始,逐层计算每个节点的输出 2. 保存中间结果(激活值)供反向传播使用 3. 最终计算损失函数值 对于第 $l$ 层: $$\mathbf{z}^{[l]} = \mathbf{W}^{[l]} \mathbf{a}^{[l-1]} + \mathbf{b}^{[l]}$$ $$\mathbf{a}^{[l]} = g^{[l]}(\mathbf{z}^{[l]})$$ 其中 $\mathbf{W}^{[l]}$ 是权重矩阵,$\mathbf{b}^{[l]}$ 是偏置向量,$g^{[l]}$ 是激活函数。 **反向传播阶段**: 1. 从输出层开始,计算损失函数对输出的梯度 2. 逐层反向传播梯度 3. 计算每层的参数梯度 定义第 $l$ 层的误差项: $$\boldsymbol{\delta}^{[l]} = \frac{\partial L}{\partial \mathbf{z}^{[l]}}$$ 输出层的误差项: $$\boldsymbol{\delta}^{[L]} = \nabla_{\mathbf{a}^{[L]}} L \odot g'^{[L]}(\mathbf{z}^{[L]})$$ 隐藏层的误差项(反向传播): $$\boldsymbol{\delta}^{[l]} = (\mathbf{W}^{[l+1]})^T \boldsymbol{\delta}^{[l+1]} \odot g'^{[l]}(\mathbf{z}^{[l]})$$ 参数梯度: $$\frac{\partial L}{\partial \mathbf{W}^{[l]}} = \boldsymbol{\delta}^{[l]} (\mathbf{a}^{[l-1]})^T$$ $$\frac{\partial L}{\partial \mathbf{b}^{[l]}} = \boldsymbol{\delta}^{[l]}$$ 以下是一个简化的反向传播实现: ```python import numpy as np def sigmoid(z): return 1 / (1 + np.exp(-z)) def sigmoid_derivative(z): s = sigmoid(z) return s * (1 - s) class SimpleNN: """简单神经网络与反向传播实现""" def __init__(self, layer_sizes): self.num_layers = len(layer_sizes) self.weights = [np.random.randn(y, x) * 0.01 for x, y in zip(layer_sizes[:-1], layer_sizes[1:])] self.biases = [np.zeros((y, 1)) for y in layer_sizes[1:]] def forward(self, x): """前向传播""" activation = x activations = [x] zs = [] for w, b in zip(self.weights, self.biases): z = np.dot(w, activation) + b zs.append(z) activation = sigmoid(z) activations.append(activation) return activations, zs def backward(self, x, y, activations, zs): """反向传播""" nabla_w = [np.zeros(w.shape) for w in self.weights] nabla_b = [np.zeros(b.shape) for b in self.biases] # 输出层误差 delta = (activations[-1] - y) * sigmoid_derivative(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].T) # 反向传播到隐藏层 for l in range(2, self.num_layers): delta = np.dot(self.weights[-l+1].T, delta) * sigmoid_derivative(zs[-l]) nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].T) return nabla_w, nabla_b ``` ### 5.3.3 梯度检查与调试技巧:数值梯度验证 梯度检查是验证反向传播实现正确性的重要手段。**数值梯度**使用有限差分近似计算梯度: $$\frac{\partial f}{\partial x_i} \approx \frac{f(x_i + \epsilon) - f(x_i - \epsilon)}{2\epsilon}$$ 其中 $\epsilon$ 是一个很小的数(通常取 $10^{-5}$ 到 $10^{-7}$)。 梯度检查的步骤: 1. 使用反向传播计算解析梯度 2. 使用有限差分计算数值梯度 3. 比较两者的一致性 相对误差通常用于衡量一致性: $$\text{relative\_error} = \frac{|\nabla_{\text{analytic}} - \nabla_{\text{numerical}}|}{|\nabla_{\text{analytic}}| + |\nabla_{\text{numerical}}|}$$ 如果相对误差小于 $10^{-7}$,通常认为实现是正确的;如果在 $10^{-5}$ 到 $10^{-7}$ 之间,可能需要检查;如果大于 $10^{-5}$,则很可能存在错误。 ```python def numerical_gradient(f, x, epsilon=1e-5): """计算数值梯度""" grad = np.zeros_like(x) it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) while not it.finished: idx = it.multi_index old_val = x[idx] x[idx] = old_val + epsilon fx_plus = f(x) x[idx] = old_val - epsilon fx_minus = f(x) grad[idx] = (fx_plus - fx_minus) / (2 * epsilon) x[idx] = old_val it.iternext() return grad def gradient_check(model, x, y, epsilon=1e-5): """梯度检查""" # 获取解析梯度 activations, zs = model.forward(x) nabla_w, nabla_b = model.backward(x, y, activations, zs) # 计算数值梯度 def loss_fn(W): model.weights[0] = W acts, _ = model.forward(x) return np.mean((acts[-1] - y) ** 2) numerical_w = numerical_gradient(loss_fn, model.weights[0], epsilon) # 比较 diff = np.abs(nabla_w[0] - numerical_w) relative_error = diff / (np.abs(nabla_w[0]) + np.abs(numerical_w) + 1e-8) print(f"Max relative error: {np.max(relative_error):.2e}") return relative_error ``` 除了梯度检查,调试神经网络时还可以采用以下技巧: 1. **可视化激活值分布**:检查是否存在梯度消失或爆炸 2. **监控梯度范数**:确保梯度在合理范围内 3. **使用简单数据集**:在小型合成数据集上验证模型能力 4. **逐步增加复杂度**:从线性模型开始,逐步添加非线性 5. **检查损失曲线**:确保损失正常下降 ## 5.4 泛化与正则化 ### 5.4.1 过拟合与欠拟合:偏差-方差权衡 **泛化能力**是机器学习模型的核心指标,指模型在未见过的数据上的表现能力。好的泛化能力意味着模型学到了数据的内在规律,而非仅仅记住了训练样本。 **过拟合**(Overfitting)发生在模型过于复杂时,它记住了训练数据的噪声和细节,而无法泛化到新数据。过拟合的特征包括: - 训练误差很低,但测试误差很高 - 模型对训练数据中的噪声敏感 - 模型参数值通常很大 **欠拟合**(Underfitting)发生在模型过于简单时,它无法捕捉数据的基本模式。欠拟合的特征包括: - 训练误差和测试误差都很高 - 模型无法捕捉数据的复杂模式 - 模型过于简化  *图5-4:过拟合与欠拟合的可视化。左图展示欠拟合(线性模型无法捕捉非线性模式);中图展示合适的拟合;右图展示过拟合(高阶多项式过度拟合噪声)。* **偏差-方差分解**提供了理解泛化误差的理论框架。对于给定的测试点 $x$,期望预测误差可以分解为: $$\mathbb{E}[(y - \hat{f}(x))^2] = \underbrace{(\mathbb{E}[\hat{f}(x)] - f(x))^2}_{\text{Bias}^2} + \underbrace{\mathbb{E}[(\hat{f}(x) - \mathbb{E}[\hat{f}(x)])^2]}_{\text{Variance}} + \underbrace{\sigma^2}_{\text{Noise}}$$ 其中: - **偏差**(Bias):模型期望预测与真实值之间的差距,反映模型的拟合能力 - **方差**(Variance):模型预测在不同训练集上的波动,反映模型的稳定性 - **噪声**(Noise):数据本身的固有噪声,不可减少 偏差-方差权衡是机器学习中的核心权衡: - 简单模型通常具有高偏差、低方差(欠拟合倾向) - 复杂模型通常具有低偏差、高方差(过拟合倾向) - 最优模型复杂度在两者之间找到平衡  *图5-5:偏差-方差分解与权衡。随着模型复杂度增加,偏差减小但方差增大,总误差在某一复杂度达到最小。右下图展示了典型的权衡曲线。* ### 5.4.2 正则化方法:L1、L2、Elastic Net **正则化**是通过在损失函数中添加惩罚项来限制模型复杂度的技术,从而提高泛化能力。 **L2正则化**(Ridge回归)添加权重平方和的惩罚: $$L_{\text{Ridge}}(\boldsymbol{\theta}) = L(\boldsymbol{\theta}) + \lambda \sum_{i} \theta_i^2$$ L2正则化的效果: 1. 使权重趋向于小的非零值 2. 权重均匀收缩,不会产生稀疏性 3. 对异常值相对鲁棒 4. 有解析解(对于线性模型) L2正则化的梯度: $$\nabla L_{\text{Ridge}} = \nabla L + 2\lambda \boldsymbol{\theta}$$ **L1正则化**(Lasso回归)添加权重绝对值和的惩罚: $$L_{\text{Lasso}}(\boldsymbol{\theta}) = L(\boldsymbol{\theta}) + \lambda \sum_{i} |\theta_i|$$ L1正则化的效果: 1. 产生稀疏权重(部分权重变为精确的零) 2. 实现特征选择 3. 对异常值更敏感 4. 没有解析解,需要迭代优化 L1正则化的次梯度: $$\frac{\partial |\theta_i|}{\partial \theta_i} = \text{sign}(\theta_i) = \begin{cases} 1 & \theta_i > 0 \\ -1 & \theta_i < 0 \\ [-1, 1] & \theta_i = 0 \end{cases}$$ **Elastic Net**结合L1和L2正则化: $$L_{\text{Elastic}}(\boldsymbol{\theta}) = L(\boldsymbol{\theta}) + \lambda_1 \sum_{i} |\theta_i| + \lambda_2 \sum_{i} \theta_i^2$$ 或等价地: $$L_{\text{Elastic}}(\boldsymbol{\theta}) = L(\boldsymbol{\theta}) + \lambda \left(\alpha \sum_{i} |\theta_i| + (1-\alpha) \sum_{i} \theta_i^2\right)$$ 其中 $\alpha \in [0, 1]$ 控制L1和L2的比例。Elastic Net结合了两种正则化的优点: 1. L1产生稀疏性,实现特征选择 2. L2处理相关特征,避免L1随机选择 3. 在特征数多于样本数时表现良好  *图5-6:不同正则化方法的效果对比。无正则化导致过拟合;L2产生平滑曲线;L1产生更稀疏的解;Elastic Net结合两者优点。* **表5-2:L1与L2正则化对比** | 特性 | L1正则化 | L2正则化 | |:-----|:---------|:---------| | 惩罚项 | $\sum \|\theta_i\|$ | $\sum \theta_i^2$ | | 解的稀疏性 | 是(特征选择) | 否 | | 权重收缩 | 不均匀(部分归零) | 均匀收缩 | | 计算复杂度 | 较高(需迭代) | 较低(有解析解) | | 多重共线性 | 随机选择特征 | 平均分配权重 | | 最佳应用场景 | 高维稀疏特征 | 相关特征较多 | ### 5.4.3 Dropout与批归一化:训练稳定性 **Dropout**是一种在神经网络训练中随机"关闭"部分神经元的正则化技术。在每次训练迭代中,以概率 $p$(dropout率)随机将某些神经元的输出设为零。 Dropout的数学表达: $$\mathbf{a}^{[l]} = \mathbf{m}^{[l]} \odot g^{[l]}(\mathbf{z}^{[l]})$$ 其中 $\mathbf{m}^{[l]}_j \sim \text{Bernoulli}(1-p)$ 是掩码向量。 Dropout的作用机制: 1. **集成学习效果**:每次训练不同的子网络,相当于训练指数级数量的网络集成 2. **减少共适应**:防止神经元过度依赖特定其他神经元 3. **增加鲁棒性**:强制网络学习更鲁棒的特征表示 测试时的调整: 由于训练时部分神经元被丢弃,测试时需要调整输出以保持一致性。有两种等价的实现方式: 1. **训练时缩放**:训练时将保留的神经元输出除以 $(1-p)$ 2. **测试时缩放**:测试时将所有神经元输出乘以 $(1-p)$ 现代实现通常采用第一种方式(Inverted Dropout),这样测试时无需额外操作。 **批归一化**(Batch Normalization, BN)是另一种重要的训练稳定技术。它对每个小批量数据的激活值进行归一化: $$\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$$ $$y_i = \gamma \hat{x}_i + \beta$$ 其中: - $\mu_B$ 和 $\sigma_B^2$ 是小批量的均值和方差 - $\gamma$ 和 $\beta$ 是可学习的缩放和偏移参数 - $\epsilon$ 是数值稳定性的小常数 批归一化的作用: 1. **加速训练**:允许使用更大的学习率 2. **减少内部协变量偏移**:稳定每层输入的分布 3. **正则化效果**:引入噪声,有一定正则化作用 4. **降低对初始化的敏感性**:使训练更稳定 测试时的批归一化使用训练时累积的滑动平均统计量: $$y = \gamma \frac{x - \mu_{\text{moving}}}{\sqrt{\sigma_{\text{moving}}^2 + \epsilon}} + \beta$$ 批归一化通常放置在卷积层或全连接层之后、激活函数之前(或之后,视具体情况而定)。 ### 5.4.4 早停与模型选择:验证集监控 **早停**(Early Stopping)是一种简单有效的正则化技术,通过在验证误差开始上升时停止训练来防止过拟合。 早停的基本流程: 1. 将数据分为训练集、验证集和测试集 2. 在每个epoch后评估验证集性能 3. 如果验证误差连续多个epoch没有改善,则停止训练 4. 恢复验证误差最小时的模型参数 早停的超参数: - **patience**:允许验证误差不改善的epoch数 - **min_delta**:视为改善的最小误差变化 - **restore_best_weights**:是否恢复最佳模型权重 早停的优点: 1. 简单有效,无需修改损失函数 2. 自动确定最优训练轮数 3. 可以与任何优化器结合使用 4. 计算开销小 **模型选择**是选择最优模型配置的过程。常见的模型选择策略包括: **交叉验证**(Cross-Validation): - **K折交叉验证**:将数据分为K份,轮流使用K-1份训练、1份验证 - **留一交叉验证**:每个样本轮流作为验证集 - **分层交叉验证**:保持各类别比例一致 **网格搜索**(Grid Search): 在预定义的超参数空间中穷举所有组合: ```python from sklearn.model_selection import GridSearchCV param_grid = { 'learning_rate': [0.001, 0.01, 0.1], 'batch_size': [16, 32, 64], 'dropout_rate': [0.2, 0.5] } grid_search = GridSearchCV(model, param_grid, cv=5) grid_search.fit(X_train, y_train) ``` **随机搜索**(Random Search): 在超参数空间中随机采样,通常在超参数维度较高时更有效: ```python from sklearn.model_selection import RandomizedSearchCV from scipy.stats import uniform, randint param_dist = { 'learning_rate': uniform(0.0001, 0.1), 'batch_size': randint(16, 128), 'dropout_rate': uniform(0.1, 0.5) } random_search = RandomizedSearchCV(model, param_dist, n_iter=100, cv=5) ``` **贝叶斯优化**(Bayesian Optimization): 使用概率模型(通常是高斯过程)来建模超参数与性能之间的关系,智能地选择下一个评估点: ```python from skopt import BayesSearchCV opt = BayesSearchCV( model, param_dist, n_iter=50, cv=5, n_jobs=-1 ) opt.fit(X_train, y_train) ``` 模型选择的最佳实践: 1. **保持测试集独立**:测试集只用于最终评估,不参与任何模型选择 2. **使用验证集进行调参**:所有超参数调整基于验证集性能 3. **多次重复实验**:减少随机性带来的偏差 4. **考虑计算成本**:平衡搜索空间大小与计算资源 5. **监控多个指标**:不仅关注准确率,还要考虑召回率、F1等指标 通过合理应用正则化技术和模型选择策略,我们可以构建泛化能力强、在实际应用中表现稳定的机器学习模型。 ### 5.4.5 实践技巧与常见问题 在实际应用中,优化与泛化问题往往交织在一起,需要综合考虑。以下是一些实用的技巧和经验总结。 **学习率调度的最佳实践**: 学习率是影响优化效果最关键的超参数之一。常见的学习率调度策略包括: 1. **阶梯衰减**(Step Decay):每隔固定epoch将学习率乘以一个衰减因子 $$\eta_t = \eta_0 \cdot \gamma^{\lfloor t / k \rfloor}$$ 2. **指数衰减**(Exponential Decay):学习率按指数函数衰减 $$\eta_t = \eta_0 \cdot e^{-\lambda t}$$ 3. **余弦退火**(Cosine Annealing):学习率按余弦函数周期性变化 $$\eta_t = \eta_{\min} + \frac{1}{2}(\eta_{\max} - \eta_{\min})\left(1 + \cos\left(\frac{t}{T}\pi\right)\right)$$ 4. **Warmup预热**:训练初期从小学习率逐渐增大到目标值,有助于稳定训练 ```python # 学习率预热 + 余弦退火示例 def lr_schedule(epoch, warmup_epochs=5, total_epochs=100, base_lr=0.001): if epoch < warmup_epochs: return base_lr * (epoch + 1) / warmup_epochs else: progress = (epoch - warmup_epochs) / (total_epochs - warmup_epochs) return base_lr * 0.5 * (1 + np.cos(np.pi * progress)) ``` **梯度问题的诊断与解决**: 训练过程中常见的梯度问题包括梯度消失和梯度爆炸: **梯度消失**(Vanishing Gradient):梯度在反向传播过程中逐层衰减,导致深层网络参数无法有效更新。解决方法包括: - 使用ReLU等激活函数替代sigmoid/tanh - 采用批归一化稳定激活值分布 - 使用残差连接(ResNet)提供梯度捷径 - 使用更合适的权重初始化(如He初始化、Xavier初始化) **梯度爆炸**(Exploding Gradient):梯度过大导致参数更新剧烈,损失发散。解决方法包括: - 梯度裁剪(Gradient Clipping):限制梯度的最大范数 - 使用较小的学习率 - 使用权重正则化 ```python # 梯度裁剪实现 def clip_gradients(gradients, max_norm=1.0): total_norm = np.sqrt(sum(np.sum(g**2) for g in gradients)) clip_coef = max_norm / (total_norm + 1e-6) if clip_coef < 1: gradients = [g * clip_coef for g in gradients] return gradients ``` **权重初始化策略**: 良好的权重初始化可以加速收敛并提高模型性能: 1. **Xavier/Glorot初始化**:适用于tanh和sigmoid激活函数 $$W \sim \mathcal{U}\left[-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}}\right]$$ 2. **He初始化**:适用于ReLU激活函数 $$W \sim \mathcal{N}\left(0, \sqrt{\frac{2}{n_{in}}}\right)$$ 3. **正交初始化**:保持梯度范数在反向传播中稳定 **正则化组合策略**: 在实践中,通常需要组合多种正则化技术来获得最佳效果: 1. **基础组合**:L2正则化 + Dropout + 早停 2. **深度网络组合**:批归一化 + Dropout + 权重衰减 3. **数据增强**:对图像数据进行旋转、翻转、裁剪等变换 4. **标签平滑**(Label Smoothing):将硬标签转换为软标签,减少过拟合 **超参数调优的工作流程**: 1. **确定搜索空间**:基于经验和文献确定各超参数的合理范围 2. **粗粒度搜索**:使用随机搜索快速定位有希望的区域 3. **细粒度搜索**:在候选区域使用网格搜索或贝叶斯优化精调 4. **交叉验证**:使用K折交叉验证评估模型稳定性 5. **最终评估**:在独立测试集上评估最优模型 ```python # 完整的训练流程示例 def train_model(model, train_loader, val_loader, config): optimizer = AdamOptimizer(model.params, lr=config['lr']) best_val_loss = float('inf') patience_counter = 0 for epoch in range(config['max_epochs']): # 训练阶段 model.train() train_loss = 0 for batch_x, batch_y in train_loader: # 前向传播 activations, zs = model.forward(batch_x) loss = compute_loss(activations[-1], batch_y) # 反向传播 gradients = model.backward(batch_x, batch_y, activations, zs) # 梯度裁剪 gradients = clip_gradients(gradients, max_norm=config['clip_norm']) # 参数更新 optimizer.step(gradients) train_loss += loss # 验证阶段 model.eval() val_loss = evaluate(model, val_loader) # 早停检查 if val_loss < best_val_loss - config['min_delta']: best_val_loss = val_loss patience_counter = 0 save_checkpoint(model, epoch) else: patience_counter += 1 if patience_counter >= config['patience']: print(f"Early stopping at epoch {epoch}") break return load_best_model() ``` **表5-3:常见问题与解决方案速查表** | 问题现象 | 可能原因 | 解决方案 | |:---------|:---------|:---------| | 训练损失不下降 | 学习率过小/梯度消失 | 增大学习率/更换激活函数 | | 训练损失震荡 | 学习率过大/批次过小 | 减小学习率/增大批次大小 | | 训练损失发散 | 学习率过大/梯度爆炸 | 梯度裁剪/权重初始化 | | 验证损失远高于训练 | 过拟合 | 增加正则化/早停/数据增强 | | 训练验证损失都高 | 欠拟合 | 增加模型容量/减少正则化 | | 收敛速度慢 | 学习率不合适 | 使用学习率调度/Adam优化器 | 通过掌握这些优化与泛化的理论和实践技巧,读者可以更加自信地应对各种机器学习任务中的训练挑战,构建出既高效又鲁棒的模型。优化与泛化的研究仍在不断发展,新的算法和技术层出不穷,保持学习和实践是掌握这一领域的关键。 ## 学习建议 1. **够用原则**:不需要从数学分析开始系统学习,而是以问题驱动。遇到不懂的公式时,先理解其直觉含义,再深入学习数学推导。 2. **代码验证**:用 Python(NumPy)手动实现矩阵乘法、梯度下降等基础操作,比阅读公式更能加深理解。 3. **可视化思维**:利用 3Blue1Brown 等可视化资源建立几何直觉,理解向量空间、梯度场等概念。 4. **循序渐进**:先掌握线性代数和微积分(第一周),再学习概率统计(第二周),最后结合实际模型理解优化方法。 5. **回归实践**:学完每个知识点后,回到具体的 AI 模型中找到对应位置,比如注意力计算中的矩阵乘法、损失函数中的交叉熵等。 ## 推荐资源 - **教材:** 《Mathematics for Machine Learning》(Marc Peter Deisenroth 等)— 系统性强,覆盖所有基础主题 - **视频:** 3Blue1Brown《线性代数的本质》和《微积分的本质》— 顶级可视化,建立直觉理解 - **课程:** MIT 18.06(线性代数)+ Stanford CS229(概率统计部分)— 经典公开课 - **互动:** Brilliant.org 线性代数和概率论课程 — 交互式练习,适合快速入门 - **速查:** 《The Matrix Cookbook》— 矩阵求导公式速查手册,阅读论文时的必备工具