概述
人类通过视觉、听觉、触觉等多种感官感知世界,而传统 AI 主要局限于单一模态(通常是文本)。多模态 AI 的目标是让计算机像人类一样,能够同时处理和理解来自不同模态的信息,并在模态之间建立语义对齐。从 GPT-4V 的图像理解到 Sora 的视频生成,从 Whisper 的语音识别到 GPT-4o 的实时语音对话,多模态能力正在成为 AI 系统的标准配置。
多模态 AI 的核心挑战在于"模态对齐"——如何让不同模态的信息在统一的语义空间中进行比较和推理。本模块将介绍视觉-语言模型、图像生成、音频处理、跨模态检索和具身智能的基础知识,帮助你理解这个快速发展的领域。
视觉-语言模型(VLM)
视觉-语言模型(Vision-Language Model)是多模态 AI 中最成熟的分支,它能够同时理解图像和文本,实现图文互搜、视觉问答、图像描述等任务。
架构演进
早期的 VLM 采用双塔架构:图像通过 CNN/ViT 编码为向量,文本通过语言模型编码为向量,然后在对比学习目标下对齐两个空间。CLIP 是这一范式的代表作——通过 4 亿图文对训练,实现了零样本图像分类和跨模态检索。当前的 VLM 则采用统一的 Transformer 架构:将图像切分为 Patch 后与文本 Token 一起输入模型,通过自注意力机制实现模态间的深度交互。GPT-4o、Gemini、Claude 等都采用了这种统一架构。
视觉编码方案
ViT(Vision Transformer)将图像切分为固定大小的 Patch,每个 Patch 通过线性投影映射为向量,加上位置编码后输入 Transformer。ViT 的优势是架构统一(与语言模型共享 Transformer 架构),便于多模态融合。对于高分辨率图像,动态分辨率方案(如 Pixtral)允许模型处理任意大小的图像;对于视频,时序建模方案在 ViT 基础上增加了时间维度的注意力。LLaVA 等开源 VLM 将预训练的 ViT 与 LLaMA 等开源 LLM 连接,通过简单的投影层实现视觉特征到语言空间的映射。
图像理解与生成
图像生成是近年来最引人注目的 AI 应用之一。从 GAN 到 Diffusion 模型再到 Transformer 架构的图像生成器,生成质量经历了质的飞跃。
Diffusion 模型深入理解
Diffusion 模型的核心是一个马尔可夫链:前向过程逐步向图像添加高斯噪声,反向过程学习去噪。具体来说,前向过程定义为一个固定的噪声调度方案(如线性调度或余弦调度),经过 T 步后图像变为纯高斯噪声。反向过程训练一个神经网络(通常是 U-Net 或 Transformer)来预测每一步的噪声,然后从噪声中逐步恢复图像。去噪扩散概率模型(DDPM)和潜在扩散模型(Latent Diffusion,即 Stable Diffusion 的基础)是两个关键变体。
文本到图像的条件生成
Stable Diffusion 通过在去噪过程中引入文本条件(使用 CLIP 文本编码器 + 交叉注意力机制),实现了从文本描述到图像的生成。ControlNet 进一步引入了空间条件控制(如边缘图、深度图、姿态图),允许对生成图像的结构进行精细控制。DALL-E 3 则在文本理解方面做出了突破,能够更准确地理解复杂的长文本描述,生成与描述高度一致的图像。
新兴架构:自回归与流匹配
除了 Diffusion 模型,自回归图像生成(如 Parti、Emu3)将图像的 Token 序列类比于文本序列,直接使用语言模型的 Next-Token 预测范式生成图像。流匹配(Flow Matching)是 Diffusion 的泛化形式,通过学习从简单分布到目标分布的连续概率流来实现生成,训练更稳定且采样速度更快。Flux 等新模型采用了这一技术路线。
音频处理
音频处理涵盖语音识别(ASR)、语音合成(TTS)、音乐生成和音频理解等领域。随着多模态大模型的发展,音频模态正在与文本和视觉深度融合。
语音识别与语音合成
Whisper 是 OpenAI 发布的强大 ASR 模型,支持多语言、多任务(语音识别、语音翻译、语言识别),在噪声环境和口音多样性下表现优异。其架构基于 Encoder-Decoder Transformer,通过大规模多语言语音数据训练。在 TTS 方面,VALL-E、Voicebox 等模型只需几秒参考音频即可克隆说话人音色;Bark 支持多语言语音合成,包括非语言声音(笑声、停顿、音乐)。
全模态语音交互
GPT-4o 和 Gemini 2.0 代表了语音交互的新范式——不再是传统的"语音识别-文本理解-语音合成"的级联管道,而是端到端的音频理解与生成。模型能够理解语音中的情绪、语调和环境声音,并在回复中自然地表达情感。这种原生多模态交互实现了真正自然的语音对话,延迟低至数百毫秒。
跨模态检索
跨模态检索允许用户用一种模态的查询来检索另一种模态的内容,例如"用文字搜图片"或"用图片搜图片"。
CLIP 模型通过对比学习在大规模图文对上训练,使得图像和文本在同一个向量空间中对齐。这意味着"一只橙色的猫"这句话的向量与相应图片的向量距离很近。基于此,跨模态检索变得非常自然:将查询(无论是文本还是图像)编码为向量,在目标模态的向量库中搜索最近邻。ColPali 等方案将视觉信息直接编码为 Token 表示用于检索,绕过了传统 OCR 预处理步骤,在文档图像检索中表现优异。
在实际应用中,跨模态检索常用于电商(以图搜商品)、媒体管理(按内容描述搜索图片/视频)、教育(搜索相关教学材料)等场景。结合多模态 RAG 系统,可以实现"上传图表-自动分析内容-生成文字报告"等复杂工作流。
具身智能基础
具身智能(Embodied AI)是将 AI 放入物理或虚拟环境中,使其能够通过感知和行动与真实世界交互的研究方向。这是 AI 从"数字世界"走向"物理世界"的关键一步。
核心技术栈
具身智能系统通常包含:感知模块(视觉、深度、触觉等传感器数据处理)、决策模块(基于 VLM 的场景理解和任务规划)、控制模块(将高层决策转化为具体的运动指令)。RT-2(Robotics Transformer 2)展示了将大语言模型应用于机器人控制的可能性——它将视觉输入和自然语言指令转化为机器人动作,实现了从语言到物理行动的端到端映射。
当前具身智能面临的核心挑战包括:Sim-to-Real Gap(仿真到现实的迁移)、数据效率(物理世界的交互数据获取成本高)、长程任务规划(机器人需要规划多步骤的复杂操作序列)。虽然距离通用人形机器人还很遥远,但特定领域的具身智能(如仓储机器人、辅助机器人)已经取得了实质进展。对于学习者而言,理解 VLA(Vision-Language-Action)模型的基本架构和训练方法是入门具身智能的关键。
学习建议
- 从 VLM 开始:使用 GPT-4V / Claude Vision API 进行图像理解和分析实验,建立对多模态交互的直觉。
- CLIP 实战:使用 OpenAI CLIP 模型实现图文互搜,理解对比学习的多模态对齐原理。
- 图像生成:使用 Stable Diffusion / DALL-E API 生成图像,探索 ControlNet 的条件控制能力。
- 音频入门:使用 Whisper 进行语音识别,使用 Bark / TTS API 进行语音合成,构建一个语音助手原型。
- 关注进展:多模态 AI 发展极快,建议定期关注 CMU、Stanford、Google DeepMind 等机构的研究动态。
推荐资源
- 论文: 《Learning Transferable Visual Models From Natural Language Supervision》(CLIP)— 多模态对齐的里程碑
- 论文: 《High-Resolution Image Synthesis with Latent Diffusion Models》(Stable Diffusion)— 理解潜在扩散模型
- 课程: Stanford CS231n(计算机视觉)+ MIT 6.S191(深度学习导论)— 建立视觉 AI 基础
- 实践: Hugging Face Diffusers 库 — 图像生成的最佳实践工具库
- 综述: Multimodal Foundation Models 综述论文 — 全面了解多模态 AI 的技术格局
卷积神经网络(Convolutional Neural Network, CNN)是深度学习在计算机视觉领域取得突破性进展的核心技术。从2012年AlexNet在ImageNet竞赛中的惊艳表现,到如今EfficientNet、Vision Transformer等先进架构的广泛应用,CNN及其变体已经成为图像分类、目标检测、语义分割等视觉任务的标准解决方案。本章将系统介绍CNN的核心原理、经典架构演进,以及在各类视觉任务中的应用实践。
8.1 图像分类
8.1.1 分类任务概述
图像分类是计算机视觉中最基础的任务,其目标是将输入图像分配到预定义的类别标签中。根据标签数量的不同,图像分类可分为两种主要类型:
单标签分类:每张图像仅属于一个类别。例如,在ImageNet数据集中,一张包含猫的图像只会被标注为"猫"这一个类别。单标签分类通常使用Softmax激活函数输出类别概率分布,并通过交叉熵损失函数进行优化:
其中,为类别数,为真实标签的one-hot编码,为模型预测的概率。
多标签分类:每张图像可能同时属于多个类别。例如,一张风景照片可能同时包含"山"、"水"、"云"等多个元素。多标签分类通常使用Sigmoid激活函数独立预测每个类别的存在概率,并采用二元交叉熵损失:
图像分类任务的挑战主要包括:类内差异(同一类别的图像可能外观差异很大)、类间相似(不同类别的图像可能外观相似)、以及视角、光照、遮挡等因素带来的变化。
8.1.2 经典网络演进
卷积神经网络的发展经历了从浅层到深层、从简单到复杂的演进过程。表8-1总结了CNN架构的关键里程碑。
表8-1 CNN架构演进时间线
| 年份 | 网络 | 核心创新 | 参数量 | ImageNet Top-5准确率 |
|---|---|---|---|---|
| 1998 | LeNet-5 | 首个成功的CNN架构,卷积+池化+全连接 | 6万 | - |
| 2012 | AlexNet | ReLU激活、Dropout、GPU训练 | 6000万 | 84.7% |
| 2014 | VGGNet | 小卷积核(3×3)堆叠,网络深度达19层 | 1.38亿 | 92.5% |
| 2014 | GoogLeNet | Inception模块,1×1卷积降维 | 400万 | 93.3% |
| 2015 | ResNet | 残差连接,可训练152+层 | 6000万 | 96.4% |
| 2016 | DenseNet | 密集连接,特征重用 | 800万 | 96.9% |
| 2019 | EfficientNet | 复合缩放,平衡深度/宽度/分辨率 | 6600万 | 97.1% |
| 2020 | Vision Transformer | 将Transformer应用于图像 | 8600万 | 97.9% |
LeNet-5 (1998):由Yann LeCun等人提出,是首个成功应用于实际任务的CNN架构。LeNet-5包含两个卷积层、两个池化层和三个全连接层,在手写数字识别任务上取得了优异性能。虽然以今天的标准来看LeNet非常浅,但它确立了卷积、池化、全连接的基本范式。
AlexNet (2012):Alex Krizhevsky等人在ImageNet 2012竞赛中以显著优势获胜,将Top-5错误率从26.2%降至15.3%。AlexNet的核心创新包括:使用ReLU激活函数解决梯度消失问题;引入Dropout正则化防止过拟合;利用GPU进行并行训练。AlexNet证明了深度CNN在大规模图像识别中的有效性,开启了深度学习的新纪元。
VGGNet (2014):牛津大学视觉几何组提出的VGGNet采用堆叠小卷积核(3×3)的策略替代大卷积核。多个3×3卷积层的感受野等效于一个更大的卷积核,但参数量更少且非线性能力更强。VGG-16和VGG-19成为后续许多网络的基础骨干。
ResNet (2015):微软研究院提出的残差网络解决了深层网络的退化问题。通过引入跳跃连接(Skip Connection),ResNet允许梯度直接回传,使得训练超过100层的网络成为可能。残差块的核心公式为:
其中,为残差映射,为恒等映射。ResNet-152在ImageNet上取得了3.57%的Top-5错误率,首次超越人类水平。
DenseNet (2016):DenseNet将跳跃连接发挥到极致,每一层都与前面所有层直接连接。这种密集连接促进了特征重用,减少了参数量,同时改善了梯度流动。DenseNet的复合函数定义为:
其中,表示前面所有层特征图的拼接。
EfficientNet (2019):Google提出的EfficientNet通过复合缩放方法同时调整网络的深度、宽度和输入分辨率。其缩放公式为:
其中,、、分别表示深度、宽度和分辨率,为复合系数。EfficientNet-B7在保持较高准确率的同时大幅减少了参数量和计算量。
8.1.3 数据增强策略
数据增强通过对训练图像进行变换来扩充数据集,提高模型的泛化能力。主要的数据增强策略包括:
几何变换:
- 随机裁剪与缩放:从图像中随机裁剪区域并调整大小
- 水平/垂直翻转:以一定概率对图像进行镜像翻转
- 旋转:将图像旋转一定角度
- 仿射变换:包括平移、剪切等线性变换
颜色变换:
- 亮度、对比度、饱和度调整:随机改变图像的色彩属性
- 颜色抖动:在HSV色彩空间中添加随机扰动
- 灰度化:以一定概率将彩色图像转为灰度
高级增强技术:
Mixup :将两张图像按一定比例混合,标签也相应混合:
其中,,通常取。
CutMix :将一张图像的某个区域剪切并粘贴到另一张图像上,标签按区域面积比例混合。相比Mixup,CutMix保留了更多的局部信息。
AutoAugment :通过强化学习自动搜索最优的数据增强策略组合,在多个数据集上取得了显著的性能提升。
8.1.4 迁移学习应用
迁移学习利用在大规模数据集(如ImageNet)上预训练的模型,通过微调适应特定任务。这种方法特别适用于训练数据有限的场景。
预训练模型:ImageNet预训练模型学习到了丰富的视觉特征表示,包括边缘、纹理、形状等低级特征,以及物体部件、整体结构等高级特征。这些特征对于大多数视觉任务都具有迁移价值。
微调策略:
-
特征提取:冻结预训练模型的所有卷积层,仅训练新添加的分类层。适用于目标任务与预训练任务相似且数据量较小的情况。
-
部分微调:冻结底层参数,微调顶层参数。底层学习的是通用特征,顶层学习的是任务相关特征。
-
完全微调:使用较小的学习率对所有层进行微调。适用于目标任务与预训练任务差异较大或数据量充足的情况。
微调技巧:
- 使用较小的学习率(如0.0001)避免破坏预训练权重
- 对最后一层使用较大的学习率
- 采用学习率衰减策略
- 使用早停防止过拟合
以下代码展示了使用PyTorch进行迁移学习的完整实现:
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 数据预处理与增强
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载预训练ResNet50模型
model = models.resnet50(pretrained=True)
# 冻结底层参数
for param in model.parameters():
param.requires_grad = False
# 替换分类层
num_classes = 10 # 目标任务的类别数
model.fc = nn.Linear(model.fc.in_features, num_classes)
# 仅新分类层参与训练
for param in model.fc.parameters():
param.requires_grad = True
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)
# 训练循环
def train_model(model, train_loader, val_loader, num_epochs=10):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
for epoch in range(num_epochs):
# 训练阶段
model.train()
train_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 验证阶段
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_acc = 100 * correct / total
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Train Loss: {train_loss/len(train_loader):.4f}, '
f'Val Loss: {val_loss/len(val_loader):.4f}, '
f'Val Acc: {val_acc:.2f}%')
return model
# 使用示例
# train_dataset = datasets.ImageFolder('path/to/train', transform=train_transform)
# val_dataset = datasets.ImageFolder('path/to/val', transform=val_transform)
# train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# val_loader = DataLoader(val_dataset, batch_size=32)
# trained_model = train_model(model, train_loader, val_loader)
迁移学习的优势在于:大幅减少训练时间、降低对大规模标注数据的需求、提高小样本任务的性能。研究表明,即使目标任务与ImageNet差异较大,预训练模型通常仍能取得比从头训练更好的结果。
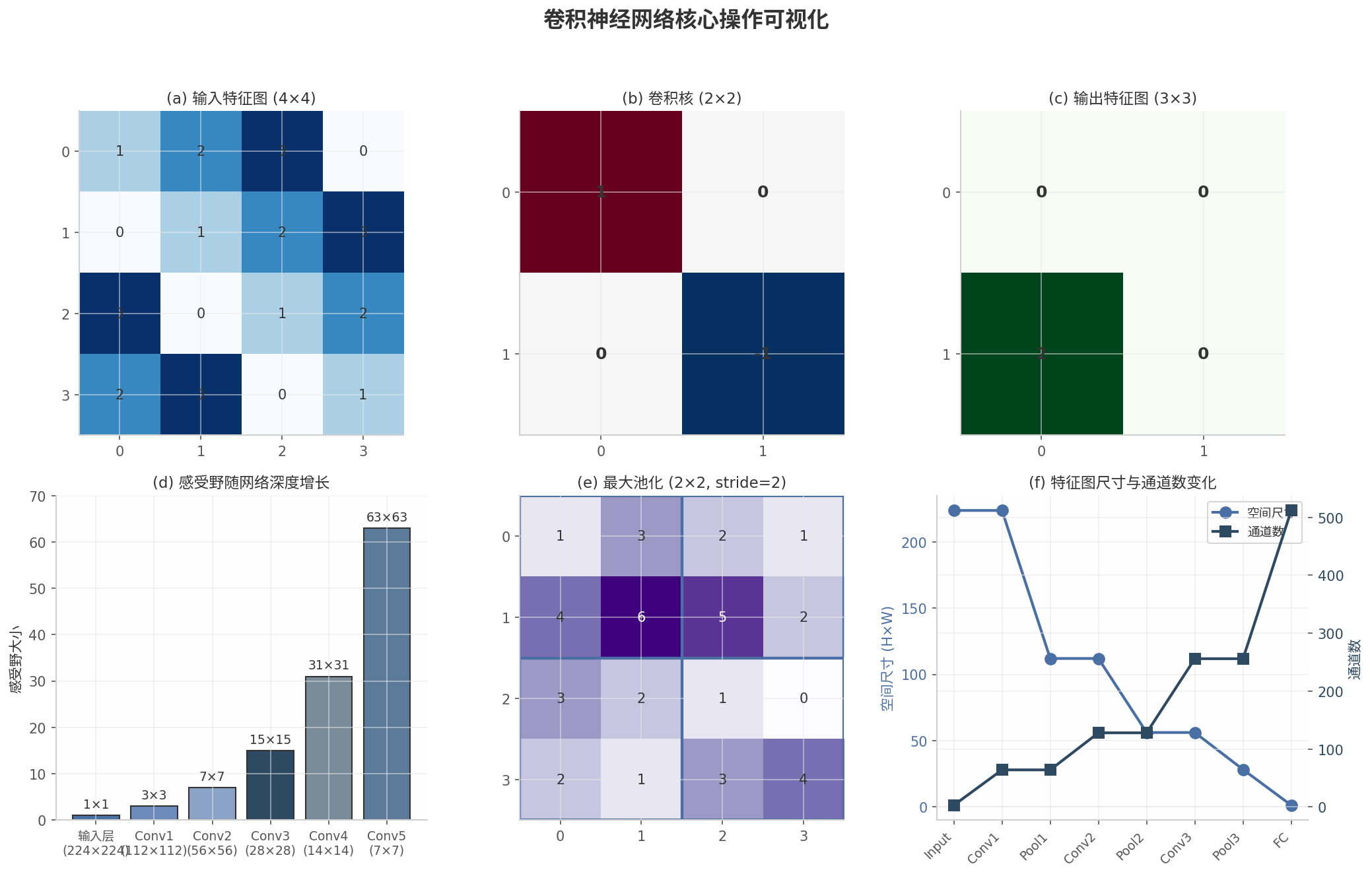
图8-1 卷积神经网络核心操作可视化:(a)输入特征图 (b)卷积核 (c)输出特征图 (d)感受野随网络深度增长 (e)最大池化操作 (f)特征图尺寸与通道数变化
图8-1展示了CNN的核心操作。卷积操作通过滑动窗口方式提取局部特征;感受野随网络深度指数增长,使深层神经元能够捕获全局信息;池化操作降低特征图分辨率,增强平移不变性;特征图的空间尺寸逐渐减小而通道数逐渐增加,实现了从低级到高级特征的层次化提取。
8.2 目标检测
8.2.1 检测任务定义
目标检测是计算机视觉中的核心任务,不仅需要识别图像中的物体类别,还需要精确定位物体的位置。与图像分类相比,目标检测的输出更加复杂,需要同时预测类别标签和边界框坐标。
边界框(Bounding Box):用于定位目标物体的矩形框,通常用四元组表示,其中是边界框中心点坐标,是宽度和高度。也可以用表示左上角和右下角坐标。
交并比(Intersection over Union, IoU):衡量两个边界框重叠程度的指标,定义为交集面积与并集面积之比:
IoU取值范围为,通常设定阈值(如0.5)来判断检测结果是否正确。IoU越高,表示预测框与真实框越接近。
非极大值抑制(Non-Maximum Suppression, NMS):目标检测算法通常会在同一目标周围产生多个重叠的检测框。NMS通过保留置信度最高的检测框,并移除与之IoU超过阈值的其他框,来消除冗余检测。NMS算法流程如下:
- 将所有检测框按置信度降序排序
- 选择置信度最高的框,加入输出列表
- 计算该框与其他所有框的IoU,移除IoU大于阈值的框
- 重复步骤2-3,直到所有框处理完毕
8.2.2 两阶段检测器
两阶段检测器将检测任务分解为区域提议和目标分类两个阶段,以R-CNN系列为代表。
R-CNN (2014) :Region-based CNN是深度学习目标检测的开创性工作。其流程为:
- 使用选择性搜索(Selective Search)生成约2000个候选区域
- 将每个候选区域缩放至固定大小,输入CNN提取特征
- 使用SVM对每个区域进行分类
- 使用回归器精修边界框位置
R-CNN的主要缺点是速度较慢,每个区域都需要单独进行CNN前向传播。
Fast R-CNN (2015) :Fast R-CNN对R-CNN进行了显著改进:
- 先将整张图像输入CNN提取特征图
- 使用RoI(Region of Interest)池化从特征图中提取每个候选区域的特征
- 使用全连接层同时进行分类和边界框回归
Fast R-CNN通过共享卷积计算大幅提高了速度,但候选区域生成仍依赖选择性搜索。
Faster R-CNN (2015) :Faster R-CNN引入区域提议网络(Region Proposal Network, RPN),实现了端到端的训练:
RPN在特征图上滑动,每个位置预测多个候选框(称为anchor)。对于每个anchor,RPN输出:
- 目标/背景二分类得分
- 边界框回归偏移量
RPN与检测网络共享卷积特征,形成统一的端到端框架。Faster R-CNN在VOC 2007数据集上达到73.2%的mAP,检测速度约5 FPS。
8.2.3 单阶段检测器
单阶段检测器直接预测目标的类别和位置,省去了区域提议阶段,速度更快但精度略低。
YOLO (You Only Look Once) :YOLO将检测视为回归问题,将图像划分为的网格,每个网格预测个边界框及其置信度,以及个类别概率。每个边界框预测包含5个值:。
YOLO的损失函数由三部分组成:
YOLO系列持续演进,YOLOv2引入anchor机制,YOLOv3采用多尺度预测,YOLOv4整合多种优化技巧。最新的YOLOv8 采用先进的骨干网络和颈部架构,使用无锚点(anchor-free)的检测头,在精度和速度之间取得了优异平衡。
SSD (Single Shot MultiBox Detector) :SSD在多个不同尺度的特征图上同时进行检测,浅层特征图检测小目标,深层特征图检测大目标。SSD使用预设的default box(类似anchor),通过卷积层直接预测类别得分和边界框偏移。
SSD的多尺度检测策略使其在不同大小的目标上都表现良好,但对小目标的检测效果仍有提升空间。
RetinaNet (2017) :RetinaNet针对单阶段检测器的类别不平衡问题(背景框远多于目标框),提出了Focal Loss:
其中,为模型对正确类别的预测概率,为聚焦参数(通常取2)。Focal Loss降低了易分类样本的权重,使模型更关注难分类样本。RetinaNet首次证明单阶段检测器可以达到与两阶段检测器相当的精度。
表8-2 主流目标检测器对比
| 检测器 | 类型 | 骨干网络 | 输入尺寸 | mAP (COCO) | 速度 (FPS) |
|---|---|---|---|---|---|
| Faster R-CNN | 两阶段 | ResNet-101 | 1000×600 | 42.0% | 5 |
| YOLOv3 | 单阶段 | DarkNet-53 | 608×608 | 33.0% | 35 |
| SSD512 | 单阶段 | VGG-16 | 512×512 | 34.4% | 22 |
| RetinaNet | 单阶段 | ResNet-101 | 800×800 | 44.0% | 11 |
| YOLOv5 | 单阶段 | CSPDarknet | 640×640 | 50.0% | 140 |
| YOLOv8 | 单阶段 | CSPNet | 640×640 | 53.9% | 120 |
8.2.4 检测评估与优化
平均精度均值(mean Average Precision, mAP):目标检测的标准评估指标。mAP计算步骤如下:
- 对于每个类别,计算不同召回率下的精确率,绘制PR曲线
- 计算PR曲线下面积,得到该类别的AP(Average Precision)
- 对所有类别的AP取平均,得到mAP
COCO数据集通常报告mAP@0.5(IoU阈值为0.5)和mAP@0.5:0.95(IoU阈值从0.5到0.95的平均)。
速度-精度权衡:实际应用中需要在检测精度和推理速度之间取得平衡。影响检测速度的因素包括:
- 网络深度和宽度
- 输入图像分辨率
- 检测头复杂度
- 后处理(如NMS)效率
常用的优化策略包括:
- 模型压缩:剪枝、量化、知识蒸馏
- 轻量级网络:MobileNet、ShuffleNet作为骨干
- TensorRT/ONNX:使用推理加速框架
- 批量推理:提高GPU利用率
8.3 图像分割
图像分割将图像划分为具有语义意义的区域,是像素级别的预测任务。根据分割粒度,可分为语义分割和实例分割。
8.3.1 语义分割
语义分割为每个像素分配类别标签,不区分同类别的不同实例。例如,所有"人"类别的像素都被标记为同一标签。
FCN (Fully Convolutional Network) :FCN是首个端到端的语义分割网络,将全连接层替换为卷积层,使网络可以接受任意尺寸的输入并输出对应尺寸的分割图。FCN的关键设计包括:
- 全卷积化:将分类网络(如VGG)的全连接层转为1×1卷积
- 反卷积(Deconvolution):使用转置卷积上采样恢复空间分辨率
- 跳跃连接:融合浅层细节信息和深层语义信息
FCN-32s、FCN-16s、FCN-8s分别表示上采样倍率,跳跃连接越多,分割边界越精细。
U-Net (2015) :U-Net最初为医学图像分割设计,其编码器-解码器结构配合跳跃连接,在数据量有限的场景下表现优异。U-Net的特点包括:
- 对称结构:编码器逐步下采样提取特征,解码器逐步上采样恢复分辨率
- 跳跃连接:将编码器特征与解码器特征拼接,保留空间细节
- 数据高效:即使在少量标注数据上也能取得良好效果
U-Net已成为医学图像分割的标准基线,并被广泛应用于遥感图像、工业检测等领域。
DeepLab系列 :DeepLab通过空洞卷积(Atrous Convolution)扩大感受野而不损失分辨率。空洞卷积通过在卷积核中插入空洞来增大有效感受野:
其中,为空洞率(dilation rate)。
DeepLabv2引入ASPP(Atrous Spatial Pyramid Pooling),使用不同空洞率的并行卷积捕获多尺度信息。DeepLabv3+采用编码器-解码器结构,进一步提升了分割精度。
8.3.2 实例分割
实例分割不仅预测像素类别,还区分同类别的不同实例。例如,图像中的每个人都将被分割为独立的区域。
Mask R-CNN (2017) :Mask R-CNN在Faster R-CNN基础上增加了分割分支,实现了目标检测与实例分割的统一框架。其关键创新包括:
- RoIAlign:使用双线性插值替代RoI Pooling的量化操作,避免特征错位
- 并行分支:在边界框回归和分类的同时,增加掩码预测分支
- FCN掩码:对每个RoI使用全卷积网络预测分割掩码
Mask R-CNN的损失函数为:
其中,为分类损失,为边界框回归损失,为平均二值交叉熵损失。
Mask R-CNN在COCO实例分割任务上取得了显著领先,且推理速度接近Faster R-CNN,成为实例分割的主流方法。
8.3.3 分割网络架构
编码器-解码器结构是现代分割网络的主流范式:
编码器:通常使用预训练的分类网络(如ResNet、VGG)作为骨干,通过连续的卷积和下采样提取多尺度特征。编码器输出低分辨率、高语义信息的特征图。
解码器:通过上采样逐步恢复空间分辨率,同时融合编码器的低级特征。常用的上采样方法包括:
- 转置卷积(Transposed Convolution):可学习的上采样
- 双线性插值上采样 + 卷积:计算效率更高
- 亚像素卷积(PixelShuffle):低通道数高分辨率重排
跳跃连接:将编码器特征与解码器特征融合,弥补上采样过程中的细节损失。融合方式包括:
- 拼接(Concatenation):通道维度拼接
- 逐元素相加:需要通道数匹配
- 注意力门控:自适应选择重要特征
表8-3 语义分割网络对比
| 网络 | 骨干网络 | 关键特点 | VOC mIoU | 参数量 |
|---|---|---|---|---|
| FCN-8s | VGG-16 | 全卷积+跳跃连接 | 67.2% | 134M |
| U-Net | - | 对称结构+跳跃连接 | 74.5% | 31M |
| SegNet | VGG-16 | 编码器-解码器+池化索引 | 71.2% | 29M |
| DeepLabv3+ | ResNet-101 | ASPP+编码器-解码器 | 87.8% | 62M |
| PSPNet | ResNet-101 | 金字塔池化模块 | 85.4% | 68M |
视觉 Transformer
ViT 架构原理
Vision Transformer(ViT)将自然语言处理中的 Transformer 架构成功应用于计算机视觉任务,开启了视觉模型的新范式。ViT 的核心思想是将图像视为序列数据,而非传统的网格结构。
图像分块(Patch Embedding):ViT 首先将输入图像划分为固定大小的非重叠块(patch)。对于 的图像,划分为 的块后,得到 个 patch。每个 patch 展平后通过线性投影映射到 维嵌入空间:
其中, 为第 个 patch 的展平向量, 为可学习的投影矩阵, 为位置嵌入。
CLS Token:借鉴 BERT 的做法,ViT 在 patch 序列前添加一个可学习的分类 token()。该 token 在 Transformer 各层与所有 patch 交互,最终输出用于图像分类。
Transformer Encoder:ViT 使用标准的 Transformer 编码器,由 个相同的块堆叠而成。每个块包含:
- 多头自注意力(MSA):计算 patch 之间的全局关联
- 前馈网络(FFN):对每个位置独立进行非线性变换
- 层归一化(LayerNorm)和残差连接
数学表达为:
MLP Head:Transformer 编码器的输出经过层归一化后,提取 CLS token 对应的特征,输入 MLP 分类头得到最终预测。
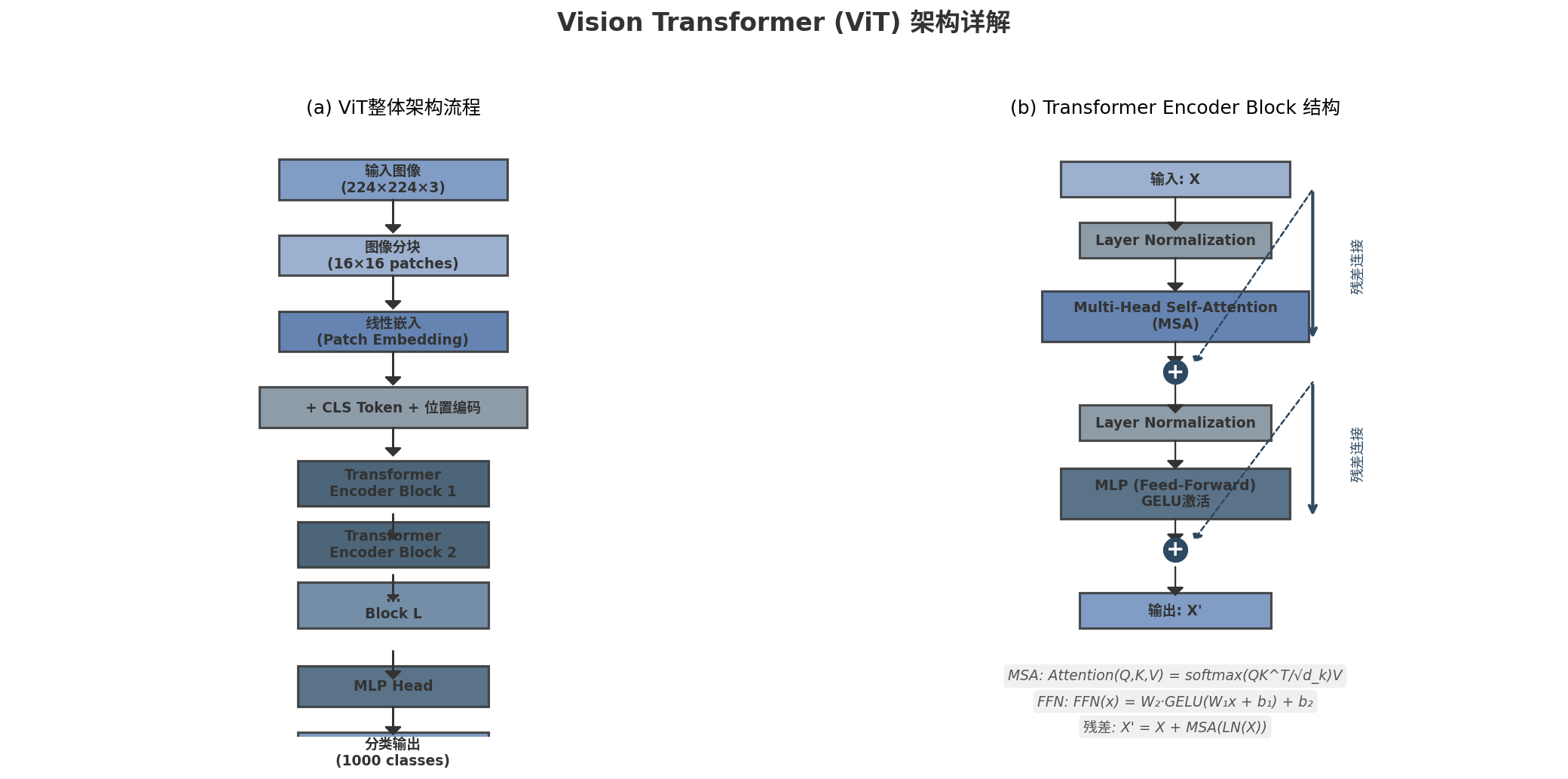
图8-2 Vision Transformer 架构详解:(a) ViT 整体架构流程 (b) Transformer Encoder Block 结构
图 8-2 展示了 ViT 的完整架构。与 CNN 相比,ViT 的主要区别在于:
- 全局感受野:自注意力机制使每个 patch 能直接关注所有其他 patch
- 弱归纳偏置:ViT 不假设局部性和平移不变性,依赖数据学习空间关系
- 数据需求:ViT 需要大规模数据(如 ImageNet-21k、JFT-300M)才能达到最佳性能
位置编码与分块
位置编码是 Transformer 的关键组件,用于注入序列元素的位置信息。
可学习位置嵌入:ViT 采用可学习的位置嵌入,与 patch 嵌入相加后输入 Transformer。对于 个 patch,学习 个位置向量(包括 CLS token):
实验表明,可学习位置嵌入与正弦/余弦固定编码效果相当,但实现更简单。
1D 位置嵌入:将 patch 按光栅扫描顺序(从左到右、从上到下)排列为一维序列,分配位置编码。
2D 位置嵌入:分别学习行方向和列方向的位置编码,然后相加。对于 的 patch 网格:
实验表明,1D 和 2D 位置嵌入在分类任务上差异不大,但 2D 嵌入可能对检测和分割任务更有利。
相对位置编码:部分变体使用相对位置编码,编码两个 patch 之间的相对距离而非绝对位置。这种方法对序列长度变化更具泛化能力。
视觉 Transformer 变体
DeiT (Data-efficient Image Transformer):DeiT 解决了 ViT 对大规模数据依赖的问题,通过知识蒸馏在 ImageNet 上训练。DeiT 引入蒸馏 token(distillation token),与 CLS token 并行学习,分别优化硬标签和教师模型的软标签。
DeiT 的核心思想是:使用 ConvNet(如 RegNet)作为教师模型,通过注意力蒸馏将归纳偏置传递给 ViT。DeiT-Ti 在 ImageNet 上达到 72.2% 的 Top-1 准确率,参数量仅 5.7M。
Swin Transformer:Swin Transformer 引入层次化结构和移位窗口注意力,在保持 Transformer 全局建模能力的同时,降低了计算复杂度。
层次化结构:Swin Transformer 类似 CNN,逐层降低分辨率、增加通道数:
- 第 1 阶段:,通道数
- 第 2 阶段:,通道数
- 第 3 阶段:,通道数
- 第 4 阶段:,通道数
移位窗口注意力(Shifted Window Attention):标准自注意力的计算复杂度为 ,对于高分辨率图像不可接受。Swin 将特征图划分为不重叠的窗口,在每个窗口内独立计算自注意力,复杂度降为 ,其中 为窗口大小。
为解决窗口间信息隔离问题,Swin 在相邻层之间移位窗口划分方式,使不同窗口的 patch 能够交互。这种设计使 Swin 在分类、检测、分割等任务上都取得了优异性能。
视觉 Transformer 变体对比
| 模型 | 核心创新 | 参数量 | ImageNet Top-1 | 特点 |
|---|---|---|---|---|
| ViT-B/16 | 纯 Transformer | 86M | 84.6% | 需要大数据预训练 |
| DeiT-B | 知识蒸馏 | 86M | 85.2% | 数据高效 |
| Swin-B | 移位窗口+层次化 | 88M | 85.2% | 多任务通用 |
| Swin-L | 更大规模 | 197M | 86.4% | SOTA 性能 |
| CvT | 卷积+Transformer | 32M | 83.3% | 结合 CNN 优势 |
混合架构设计
纯 Transformer 在视觉任务上取得了巨大成功,但 CNN 的局部性和平移不变性等归纳偏置仍有价值。研究者提出了多种 CNN 与 Transformer 的混合架构。
CNN+Transformer 串联:使用 CNN 作为特征提取器,将输出的特征图输入 Transformer 进行全局建模。
BoTNet (Bottleneck Transformer):将 ResNet 最后几个 bottleneck 块中的 3x3 卷积替换为多头自注意力,在检测和分割任务上取得提升。
CoAtNet (Convolution and Attention):系统研究了卷积和注意力的结合方式,发现"卷积在前、注意力在后"的垂直堆叠结构效果最佳。CoAtNet 在 ImageNet 上达到 90.88% 的 Top-1 准确率,超越了所有现有模型。
ConvNeXt (2022):ConvNeXt 将标准 CNN(ResNet)按照 Swin Transformer 的设计进行现代化改造,包括:
- 更大的卷积核(7x7)
- 深度可分离卷积
- LayerNorm 替代 BatchNorm
- GELU 激活函数
- 更少的激活和归一化层
令人惊讶的是,这种"纯 CNN"架构在 ImageNet 上达到了与 Swin Transformer 相当的性能,证明了 CNN 架构仍有巨大的优化空间。
CNN 与 Transformer 对比
| 特性 | CNN | Vision Transformer |
|---|---|---|
| 归纳偏置 | 强(局部性、平移不变性) | 弱(依赖数据学习) |
| 感受野 | 局部,随深度增长 | 全局,所有层一致 |
| 计算复杂度 | (全局注意力) | |
| 数据效率 | 高,小数据集表现好 | 低,需要大数据预训练 |
| 特征层次 | 渐进式特征提取 | 统一处理所有 patch |
| 最佳应用场景 | 通用视觉任务 | 大规模数据、长程依赖 |
感受野计算:感受野(Receptive Field)是 CNN 中的重要概念,表示输出特征图中一个像素对应的输入图像区域大小。感受野的计算公式为:
其中, 为第 层的感受野大小, 为卷积核大小, 为第 层的步长。
对于堆叠的 3x3 卷积层(步长为 1),感受野增长如下:
- 1 层:
- 2 层:
- 3 层:
- 层:
这种感受野的渐进增长使 CNN 能够层次化地提取从边缘到物体的特征。相比之下,ViT 的自注意力机制在第一层就具有全局感受野,但需要更多数据来学习有效的空间关系。
未来趋势:视觉模型的发展呈现以下趋势:
- 统一架构:一个模型处理多种视觉任务(分类、检测、分割)
- 自监督预训练:MAE、DINO 等方法减少对标注数据的依赖
- 高效设计:MobileViT、EdgeViT 等面向边缘设备的轻量模型
- 多模态融合:视觉-语言模型(CLIP、SAM)实现跨模态理解
CNN 与 Transformer 并非对立关系,而是相互借鉴、融合发展。Swin Transformer 引入了 CNN 的层次化结构,ConvNeXt 则将 Transformer 的设计理念应用于 CNN。未来的视觉模型将结合两者的优势,在效率、精度和通用性之间取得更好的平衡。
学习建议
- 从 VLM 开始:使用 GPT-4V / Claude Vision API 进行图像理解和分析实验,建立对多模态交互的直觉。
- CLIP 实战:使用 OpenAI CLIP 模型实现图文互搜,理解对比学习的多模态对齐原理。
- 图像生成:使用 Stable Diffusion / DALL-E API 生成图像,探索 ControlNet 的条件控制能力。
- 音频入门:使用 Whisper 进行语音识别,使用 Bark / TTS API 进行语音合成,构建一个语音助手原型。
- 关注进展:多模态 AI 发展极快,建议定期关注 CMU、Stanford、Google DeepMind 等机构的研究动态。
推荐资源
- 论文: 《Learning Transferable Visual Models From Natural Language Supervision》(CLIP)— 多模态对齐的里程碑
- 论文: 《High-Resolution Image Synthesis with Latent Diffusion Models》(Stable Diffusion)— 理解潜在扩散模型
- 课程: Stanford CS231n(计算机视觉)+ MIT 6.S191(深度学习导论)— 建立视觉 AI 基础
- 实践: Hugging Face Diffusers 库 — 图像生成的最佳实践工具库
- 综述: Multimodal Foundation Models 综述论文 — 全面了解多模态 AI 的技术格局
视觉 Transformer
ViT 架构原理
Vision Transformer(ViT)将自然语言处理中的 Transformer 架构成功应用于计算机视觉任务,开启了视觉模型的新范式。ViT 的核心思想是将图像视为序列数据,而非传统的网格结构。
图像分块(Patch Embedding):ViT 首先将输入图像划分为固定大小的非重叠块(patch)。对于 的图像,划分为 的块后,得到 个 patch。每个 patch 展平后通过线性投影映射到 维嵌入空间:
其中, 为第 个 patch 的展平向量, 为可学习的投影矩阵, 为位置嵌入。
CLS Token:借鉴 BERT 的做法,ViT 在 patch 序列前添加一个可学习的分类 token()。该 token 在 Transformer 各层与所有 patch 交互,最终输出用于图像分类。
Transformer Encoder:ViT 使用标准的 Transformer 编码器,由 个相同的块堆叠而成。每个块包含:
- 多头自注意力(MSA):计算 patch 之间的全局关联
- 前馈网络(FFN):对每个位置独立进行非线性变换
- 层归一化(LayerNorm)和残差连接
数学表达为:
MLP Head:Transformer 编码器的输出经过层归一化后,提取 CLS token 对应的特征,输入 MLP 分类头得到最终预测。
图8-2 Vision Transformer 架构详解:(a) ViT 整体架构流程 (b) Transformer Encoder Block 结构
图 8-2 展示了 ViT 的完整架构。与 CNN 相比,ViT 的主要区别在于:
- 全局感受野:自注意力机制使每个 patch 能直接关注所有其他 patch
- 弱归纳偏置:ViT 不假设局部性和平移不变性,依赖数据学习空间关系
- 数据需求:ViT 需要大规模数据(如 ImageNet-21k、JFT-300M)才能达到最佳性能
位置编码与分块
位置编码是 Transformer 的关键组件,用于注入序列元素的位置信息。
可学习位置嵌入:ViT 采用可学习的位置嵌入,与 patch 嵌入相加后输入 Transformer。对于 个 patch,学习 个位置向量(包括 CLS token):
实验表明,可学习位置嵌入与正弦/余弦固定编码效果相当,但实现更简单。
1D 位置嵌入:将 patch 按光栅扫描顺序(从左到右、从上到下)排列为一维序列,分配位置编码。
2D 位置嵌入:分别学习行方向和列方向的位置编码,然后相加。对于 的 patch 网格:
实验表明,1D 和 2D 位置嵌入在分类任务上差异不大,但 2D 嵌入可能对检测和分割任务更有利。
相对位置编码:部分变体使用相对位置编码,编码两个 patch 之间的相对距离而非绝对位置。这种方法对序列长度变化更具泛化能力。
视觉 Transformer 变体
DeiT (Data-efficient Image Transformer):DeiT 解决了 ViT 对大规模数据依赖的问题,通过知识蒸馏在 ImageNet 上训练。DeiT 引入蒸馏 token(distillation token),与 CLS token 并行学习,分别优化硬标签和教师模型的软标签。
DeiT 的核心思想是:使用 ConvNet(如 RegNet)作为教师模型,通过注意力蒸馏将归纳偏置传递给 ViT。DeiT-Ti 在 ImageNet 上达到 72.2% 的 Top-1 准确率,参数量仅 5.7M。
Swin Transformer:Swin Transformer 引入层次化结构和移位窗口注意力,在保持 Transformer 全局建模能力的同时,降低了计算复杂度。
层次化结构:Swin Transformer 类似 CNN,逐层降低分辨率、增加通道数:
- 第 1 阶段:,通道数
- 第 2 阶段:,通道数
- 第 3 阶段:,通道数
- 第 4 阶段:,通道数
移位窗口注意力(Shifted Window Attention):标准自注意力的计算复杂度为 ,对于高分辨率图像不可接受。Swin 将特征图划分为不重叠的窗口,在每个窗口内独立计算自注意力,复杂度降为 ,其中 为窗口大小。
为解决窗口间信息隔离问题,Swin 在相邻层之间移位窗口划分方式,使不同窗口的 patch 能够交互。这种设计使 Swin 在分类、检测、分割等任务上都取得了优异性能。
视觉 Transformer 变体对比
| 模型 | 核心创新 | 参数量 | ImageNet Top-1 | 特点 |
|---|---|---|---|---|
| ViT-B/16 | 纯 Transformer | 86M | 84.6% | 需要大数据预训练 |
| DeiT-B | 知识蒸馏 | 86M | 85.2% | 数据高效 |
| Swin-B | 移位窗口+层次化 | 88M | 85.2% | 多任务通用 |
| Swin-L | 更大规模 | 197M | 86.4% | SOTA 性能 |
| CvT | 卷积+Transformer | 32M | 83.3% | 结合 CNN 优势 |
混合架构设计
纯 Transformer 在视觉任务上取得了巨大成功,但 CNN 的局部性和平移不变性等归纳偏置仍有价值。研究者提出了多种 CNN 与 Transformer 的混合架构。
CNN+Transformer 串联:使用 CNN 作为特征提取器,将输出的特征图输入 Transformer 进行全局建模。
BoTNet (Bottleneck Transformer):将 ResNet 最后几个 bottleneck 块中的 3x3 卷积替换为多头自注意力,在检测和分割任务上取得提升。
CoAtNet (Convolution and Attention):系统研究了卷积和注意力的结合方式,发现"卷积在前、注意力在后"的垂直堆叠结构效果最佳。CoAtNet 在 ImageNet 上达到 90.88% 的 Top-1 准确率,超越了所有现有模型。
ConvNeXt (2022):ConvNeXt 将标准 CNN(ResNet)按照 Swin Transformer 的设计进行现代化改造,包括:
- 更大的卷积核(7x7)
- 深度可分离卷积
- LayerNorm 替代 BatchNorm
- GELU 激活函数
- 更少的激活和归一化层
令人惊讶的是,这种"纯 CNN"架构在 ImageNet 上达到了与 Swin Transformer 相当的性能,证明了 CNN 架构仍有巨大的优化空间。
CNN 与 Transformer 对比
| 特性 | CNN | Vision Transformer |
|---|---|---|
| 归纳偏置 | 强(局部性、平移不变性) | 弱(依赖数据学习) |
| 感受野 | 局部,随深度增长 | 全局,所有层一致 |
| 计算复杂度 | (全局注意力) | |
| 数据效率 | 高,小数据集表现好 | 低,需要大数据预训练 |
| 特征层次 | 渐进式特征提取 | 统一处理所有 patch |
| 最佳应用场景 | 通用视觉任务 | 大规模数据、长程依赖 |
感受野计算:感受野(Receptive Field)是 CNN 中的重要概念,表示输出特征图中一个像素对应的输入图像区域大小。感受野的计算公式为:
其中, 为第 层的感受野大小, 为卷积核大小, 为第 层的步长。
对于堆叠的 3x3 卷积层(步长为 1),感受野增长如下:
- 1 层:
- 2 层:
- 3 层:
- 层:
这种感受野的渐进增长使 CNN 能够层次化地提取从边缘到物体的特征。相比之下,ViT 的自注意力机制在第一层就具有全局感受野,但需要更多数据来学习有效的空间关系。
未来趋势:视觉模型的发展呈现以下趋势:
- 统一架构:一个模型处理多种视觉任务(分类、检测、分割)
- 自监督预训练:MAE、DINO 等方法减少对标注数据的依赖
- 高效设计:MobileViT、EdgeViT 等面向边缘设备的轻量模型
- 多模态融合:视觉-语言模型(CLIP、SAM)实现跨模态理解
CNN 与 Transformer 并非对立关系,而是相互借鉴、融合发展。Swin Transformer 引入了 CNN 的层次化结构,ConvNeXt 则将 Transformer 的设计理念应用于 CNN。未来的视觉模型将结合两者的优势,在效率、精度和通用性之间取得更好的平衡。