概述
从实验室到生产环境,模型训练和推理部署是 AI 工程化的核心环节。大语言模型通常有数十亿到数千亿参数,训练需要数百到数千张 GPU 协同工作数周到数月。推理部署则面临延迟、吞吐量、成本和硬件适配等多重挑战。理解这些底层工程细节,不仅能帮助你更好地使用预训练模型,还能在需要微调、优化或自训练模型时做出正确的工程决策。
本模块覆盖两个核心主题:分布式训练系统(如何高效训练大模型)和推理部署优化(如何快速低成本地服务模型)。对于应用开发者而言,推理优化部分尤为重要;对于研究方向的学习者,训练系统则是理解大模型能力的必备知识。
分布式训练策略
单张 GPU 的显存(通常 24-80GB)无法容纳大模型的全部参数、梯度和优化器状态。分布式训练通过将计算任务分配到多张 GPU 上,解决了单卡显存不足的问题,同时提供了近似线性的加速比。
数据并行(Data Parallelism)
数据并行是最简单的分布式策略:每张 GPU 持有模型的完整副本,将训练数据的不同批次分配到不同 GPU 上并行计算梯度,然后通过 AllReduce 操作汇总梯度并更新模型。PyTorch 的 DistributedDataParallel(DDP)是数据并行的标准实现。然而,当模型参数量超过单卡显存时,数据并行就不够用了——这需要模型并行。
模型并行(Model Parallelism)
模型并行将模型的不同层或不同部分分配到不同 GPU 上。张量并行(Tensor Parallelism,TP)将单个矩阵运算(如注意力计算中的 QKV 线性层)拆分到多张 GPU 上并行计算,每张 GPU 只存储部分权重。流水线并行(Pipeline Parallelism,PP)将模型的不同层放置在不同 GPU 上,数据按流水线方式流经各层。Megatron-LM 是张量并行的代表性框架,DeepSpeed 和 FSDP(Fully Sharded Data Parallel)则提供了更灵活的分片策略。
3D 并行与专家并行
在实践中,大规模训练通常结合数据并行、张量并行和流水线并行,称为 3D 并行。例如,GPT-3 的训练使用了 3D 并行 + 3D 并行(DP + TP + PP)。对于混合专家模型(MoE),还需要专家并行(Expert Parallelism)——将不同的专家路由到不同的 GPU 上,实现稀疏激活下的高效计算。MoE 模型(如 Mixtral)虽然总参数量大,但每次推理只激活部分专家,在保持大模型能力的同时降低了推理成本。
混合精度训练与 ZeRO 优化
混合精度训练(Mixed Precision Training)和 ZeRO(Zero Redundancy Optimizer)是提升训练效率的两个关键技术。
混合精度训练
传统训练使用 FP32(32 位浮点数)存储和计算,但这并不总是必要的。混合精度训练在保持精度的前提下,使用 FP16 或 BF16(16 位浮点数)进行大部分计算,仅对需要高精度的部分(如损失函数归约)使用 FP32。BF16 比 FP16 更适合深度学习训练,因为它的指数范围与 FP32 相同,不容易出现数值溢出。现代 GPU(如 A100、H100)对 BF16 计算有硬件加速,混合精度训练可以获得 1.5-3 倍的加速。
ZeRO 优化
ZeRO 是 DeepSpeed 提出的显存优化技术,核心思想是消除数据并行中的冗余存储。在标准数据并行中,每张 GPU 都存储完整的模型参数、梯度和优化器状态。ZeRO 将这些冗余数据分片到不同 GPU 上:ZeRO-1 分片优化器状态,ZeRO-2 额外分片梯度,ZeRO-3 额外分片模型参数。通过按需收集和释放分片数据,ZeRO 可以在显存有限的情况下训练更大的模型。FSDP(PyTorch 原生的全分片数据并行)提供了类似的功能,是当前 PyTorch 生态中推荐的大模型训练方案。
推理优化技术
模型推理部署面临的核心挑战是"三高一低":高延迟要求(实时交互需要低延迟)、高吞吐量要求(服务大量用户)、高成本压力(GPU 采购和运维成本高)和低资源限制(边缘设备计算能力有限)。推理优化通过一系列技术手段在精度、速度和成本之间找到最优平衡。
剪枝与知识蒸馏
剪枝(Pruning)移除模型中不重要的参数或层,减少计算量和模型大小。非结构化剪枝移除单个权重(需要稀疏计算支持才能获得加速),结构化剪枝移除整个通道或层(可以直接获得加速)。知识蒸馏(Knowledge Distillation)让一个小模型(学生模型)学习大模型(教师模型)的输出分布或中间特征,使小模型获得接近大模型的性能。DistilBERT、TinyLLaMA 等都是蒸馏成功的案例。
量化:INT8 与 INT4
量化是将模型权重从高精度(FP32/FP16)降低到低精度(INT8/INT4)的技术。INT8 量化通常只带来很小的精度损失(1-2%),但可以将模型大小减半并显著提升推理速度。INT4 量化(如 GPTQ、AWQ、GGUF)可以进一步将模型大小压缩到原始的 1/4 到 1/8,但需要更精细的校准策略。Post-Training Quantization(PTQ,训练后量化)不需要重新训练,实现简单;Quantization-Aware Training(QAT,量化感知训练)在训练过程中模拟量化误差,精度更高但实现复杂。
KV Cache 优化与推测解码
自回归生成模型在推理时需要缓存已计算的 Key-Value 对(KV Cache),这占据了大量显存。KV Cache 量化、PagedAttention(vLLM 实现)和滑动窗口注意力(Mistral 的 sliding window)是常见的优化手段。推测解码(Speculative Decoding)使用一个小模型快速生成多个候选 Token,然后大模型并行验证这些 Token,将推理速度提升 2-3 倍而不损失生成质量。这是一种"以小博大"的巧妙策略——用少量额外计算换取显著的速度提升。
部署框架与推理引擎
选择合适的推理框架对部署效率和成本至关重要。不同框架在支持的模型类型、硬件平台、优化技术和易用性方面各有侧重。
主流推理引擎对比
vLLM 是当前最流行的 LLM 推理引擎,通过 PagedAttention 技术高效管理 KV Cache,支持连续批处理(Continuous Batching)以最大化吞吐量。TensorRT-LLM(NVIDIA)针对 NVIDIA GPU 进行了深度优化,结合 TensorRT 的图优化和核函数融合,在 NVIDIA 硬件上性能最优。TGI(Hugging Face)提供了开箱即用的部署方案,支持 Flash Attention 和量化。llama.cpp 针对纯 CPU 推理进行了优化,支持 GGUF 格式的量化模型,适合在消费级硬件或边缘设备上运行大模型。
ONNX 与跨平台部署
ONNX(Open Neural Network Exchange)是一种开放的模型交换格式,支持 PyTorch、TensorFlow 等框架的模型互转。ONNX Runtime 提供了跨平台的推理运行时,支持 CPU、GPU、NPU 等多种硬件。对于需要在多种设备上部署的场景(如移动端、嵌入式设备),ONNX 提供了良好的兼容性。此外,TFLite(移动端)、Core ML(iOS)和 OpenVINO(Intel 硬件)是针对特定平台的优化推理引擎。
边缘部署
边缘部署是指在终端设备(手机、IoT 设备、车载系统等)上直接运行 AI 模型,无需依赖云端。它的优势包括低延迟(无需网络传输)、隐私保护(数据不离开设备)和离线可用。
边缘部署的核心挑战是资源约束:设备算力有限、内存紧张、功耗要求严格。应对策略包括:使用小型专用模型(如 MobileNet、Phi-3-mini)、激进量化(INT4/INT2)、模型蒸馏和硬件加速(NPU/DSP)。Apple 的 Core ML 框架针对 Apple Silicon 优化了模型推理;Android 的 NNAPI 提供了统一的神经网络推理接口。端侧大模型(如 LLaMA.cpp on Mobile)正在快速发展,使得在手机上运行数十亿参数的模型成为可能。
对于 AI 工程师而言,理解云-端协同部署(Cloud-Edge Collaboration)是一个重要的方向——将复杂推理放在云端,将实时、隐私敏感的推理放在端侧,通过智能任务调度实现最优的用户体验和成本平衡。
学习建议
- 先部署后训练:大多数工程师的日常工作更接近推理部署。先用 vLLM / llama.cpp 部署模型,理解推理优化技术。
- 量化实验:使用 llama.cpp 或 AWQ 对同一模型分别进行 FP16、INT8、INT4 量化,对比生成质量和推理速度。
- 微调实践:使用 LoRA/QLoRA 对开源模型进行领域微调,理解 PEFT(Parameter-Efficient Fine-Tuning)技术。
- 性能分析:学习使用 NVIDIA Nsight Systems、PyTorch Profiler 等工具分析推理瓶颈,找到优化方向。
- 成本意识:在部署前计算 GPU 需求和运营成本,评估 ROI。了解 Spot Instance、Auto-scaling 等云成本优化策略。
推荐资源
- 系统: Berkeley CS285(Deep Reinforcement Learning)中关于分布式训练的部分 — 理解并行计算基础
- 引擎: vLLM 官方文档 + DeepSpeed 教程 — 两大主流推理和训练框架
- 论文: 《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》— 理解显存优化技术
- 实践: 使用 Ollama 或 llama.cpp 在本地部署开源大模型 — 快速上手推理部署
- 工具: Hugging Face PEFT + Transformers — 微调和部署开源模型的完整工具链
模型推理与部署
推理优化技术:KV Cache、投机解码
大语言模型推理面临两大挑战:计算量大和内存占用高。优化推理性能需要针对预填充(Prefill)和解码(Decode)两个阶段分别设计策略。
KV Cache 是解码阶段的核心优化技术。在自回归生成过程中,每个新 token 的计算都需要与之前所有 token 进行注意力计算。为了避免重复计算,模型将之前 token 的 Key 和 Value 向量缓存起来,只需计算当前 token 的 K、V 并追加到缓存中。
KV Cache 的内存占用为:
其中 是 batch size, 是层数, 是注意力头数, 是每头维度, 是序列长度。对于长序列推理,KV Cache 可能成为内存瓶颈。
PagedAttention 是 vLLM 提出的内存管理优化。受操作系统虚拟内存分页启发,PagedAttention 将 KV Cache 划分为固定大小的块(block),按需分配而非预先分配连续内存。这种设计:
- 消除了内存碎片和过度预留
- 支持在序列间共享 KV Cache(如并行采样)
- 实现了高效的内存复用
投机解码(Speculative Decoding) 通过引入小型草稿模型(draft model)加速生成。基本流程为:
- 草稿模型快速生成 个候选 token
- 目标模型并行验证这 个 token
- 接受所有匹配的 token,从第一个不匹配处重新生成
当草稿模型与目标模型输出一致时,一次前向传播可生成多个 token,实现 2-3 倍的加速。投机解码的关键是选择合适的草稿模型——需要足够快且与目标模型输出分布相似。
量化与剪枝:INT8、INT4、GPTQ
模型量化通过降低权重和激活值的精度,减少内存占用和计算量,是部署大模型的必备技术。
INT8 量化 将 FP16/BF16 权重转换为 8-bit 整数,可将模型大小减半。实现方式包括:
- PTQ(Post-Training Quantization):训练后量化,无需重新训练
- QAT(Quantization-Aware Training):量化感知训练,在训练中模拟量化效果
LLM.INT8() 算法发现,模型中的"离群值特征"(outlier features)是量化误差的主要来源。通过分离离群值进行 FP16 计算,其余部分使用 INT8,可在几乎不损失精度的情况下实现量化。
INT4 量化 进一步将精度降至 4-bit,模型大小仅为 FP16 的 1/4。主要方法包括:
- GPTQ:基于近似二阶信息的逐层量化方法,支持 4-bit 量化
- AWQ(Activation-aware Weight Quantization):考虑激活值分布的量化,保护重要权重
- GGUF/GGML:llama.cpp 使用的量化格式,支持多种精度组合
| 量化方法 | 精度 | 模型大小 | 性能损失 | 适用场景 |
|---|---|---|---|---|
| FP16 | 16-bit | 100% | 0% | 训练、高精度推理 |
| INT8 | 8-bit | 50% | <1% | 通用推理 |
| FP8 | 8-bit | 50% | <1% | NVIDIA H100 |
| INT4-GPTQ | 4-bit | 25% | 2-4% | 资源受限部署 |
| INT4-AWQ | 4-bit | 25% | 1-2% | 高质量推理 |
上表对比了不同量化方案的特点。实践中,INT8 是性能与精度的最佳平衡点,INT4 适用于显存极度受限的场景。
模型剪枝 通过移除不重要的权重或神经元压缩模型。主要方法包括:
- 结构化剪枝:移除整个神经元或注意力头
- 非结构化剪枝:移除单个权重,需要专用硬件支持稀疏计算
- SparseGPT:针对大语言模型的一次性剪枝方法
服务化部署方案:vLLM、TGI、TensorRT-LLM
生产环境部署大语言模型需要专业的推理服务框架。当前主流的部署方案包括 vLLM、TGI 和 TensorRT-LLM。
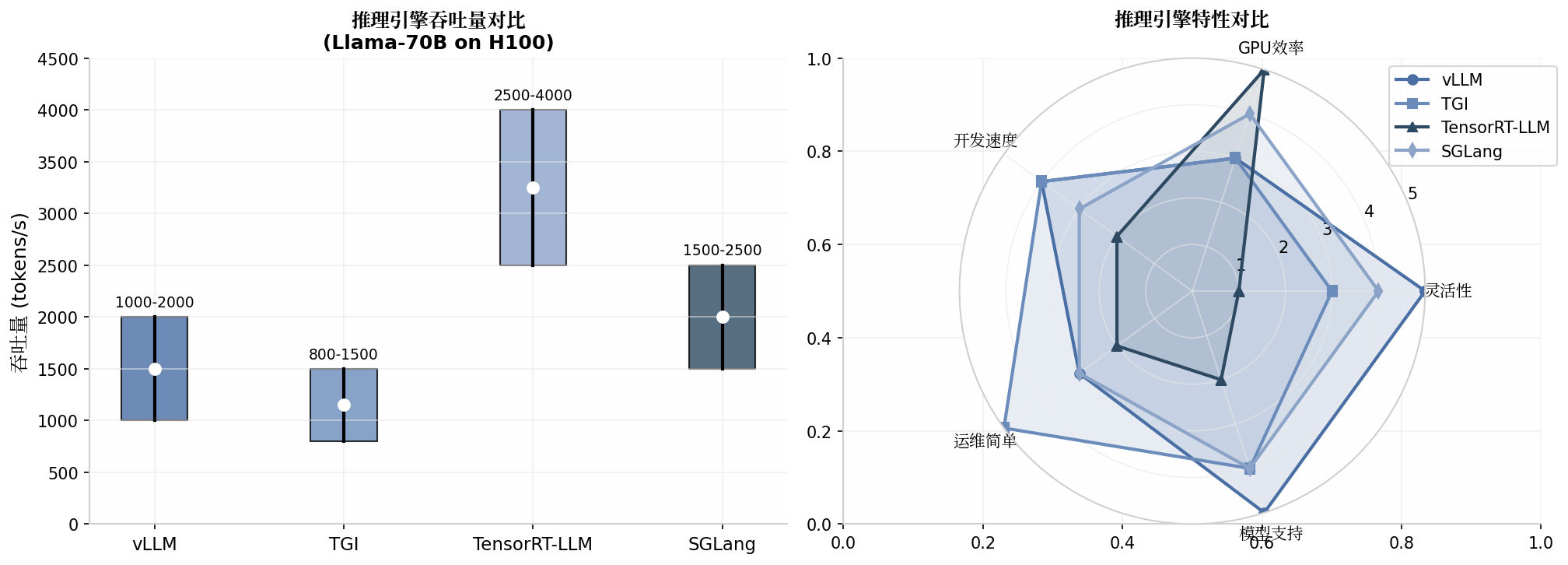
vLLM 是 UC Berkeley 开发的开源推理引擎,核心创新是 PagedAttention 算法。主要特性:
- 高效的 KV Cache 管理,内存利用率 > 90%
- 连续批处理(Continuous Batching),动态调度请求
- 支持张量并行和流水线并行
- 活跃的社区,模型支持广泛
vLLM 适合需要灵活性和快速迭代的场景,是大多数团队的首选方案。
TGI(Text Generation Inference) 是 HuggingFace 官方推出的推理服务框架。特点包括:
- 与 HuggingFace 生态深度集成
- Rust 实现的高性能核心
- 内置健康检查、监控指标、分布式追踪
- 支持 Safetensors 格式和 Flash Attention
TGI 适合已使用 HuggingFace 生态的团队,提供企业级的稳定性和可观测性。
TensorRT-LLM 是 NVIDIA 开发的高性能推理引擎。优势在于:
- 针对 NVIDIA GPU 深度优化,吞吐量最高
- 支持 FP8/NVFP4 量化,充分利用新硬件特性
- 内核融合和算子优化
- 与 Triton Inference Server 集成
TensorRT-LLM 的局限是需要 NVIDIA GPU,且模型编译需要额外工程投入。适合对性能要求极高、基础设施稳定的场景。
| 特性 | vLLM | TGI | TensorRT-LLM |
|---|---|---|---|
| 吞吐量 | 1000-2000 tok/s | 800-1500 tok/s | 2500-4000+ tok/s |
| 灵活性 | 高 | 中 | 低 |
| 易用性 | 中 | 高 | 低 |
| 硬件支持 | 多厂商 | NVIDIA 为主 | NVIDIA only |
| 模型支持 | 广泛 | 广泛 | 有限 |
| 运维复杂度 | 中 | 低 | 高 |
上表对比了三种部署方案的核心特性。选择时需要权衡性能、灵活性、运维成本等因素。对于大多数团队,建议从 vLLM 开始,在性能成为瓶颈时再考虑迁移到 TensorRT-LLM。
推理框架选择:性能、易用性对比
选择合适的推理框架需要综合考虑多方面因素。以下是决策框架:
选择 vLLM 的场景:
- 模型迭代频繁,需要快速切换
- 使用 AMD 或多种 GPU 硬件
- 团队规模较小,运维资源有限
- 需要多租户和动态 LoRA 切换
选择 TGI 的场景:
- 深度使用 HuggingFace 生态
- 需要企业级的监控和可观测性
- 部署在 AWS SageMaker 等托管平台
- 追求部署简单性和稳定性
选择 TensorRT-LLM 的场景:
- 推理成本占预算大头,需要极致性能
- 基础设施稳定,模型变更不频繁
- 团队具备 CUDA/系统优化能力
- 使用 NVIDIA H100 等最新硬件
性能优化建议:
- 批处理优化:使用动态批处理或连续批处理提高 GPU 利用率
- 量化部署:优先尝试 INT8 量化,必要时使用 INT4
- KV Cache 管理:合理设置最大序列长度,启用 KV Cache 压缩
- 投机解码:在延迟敏感场景尝试投机解码
- 前缀缓存:对于共享前缀的请求(如多轮对话),启用前缀缓存复用 KV Cache