背景知识
1.1 AI发展历程与现状
1.1.1 人工智能的三次浪潮:从符号主义到连接主义再到深度学习
人工智能的发展历程可追溯至1956年的达特茅斯会议,这场具有里程碑意义的会议首次正式提出了"人工智能"这一概念。此后近70年间,AI领域经历了三次主要的发展浪潮,每一次浪潮都代表着技术范式的根本性转变。
第一次浪潮(1950-1970年代):符号主义的黄金时代
符号主义(Symbolism)认为智能的本质是符号推理,通过明确的规则(If-Then)来实现智能行为。这一时期的核心成果包括:
- 逻辑推理系统:基于形式逻辑的自动定理证明
- 专家系统:将人类专家的知识编码为规则库,如MYCIN医疗诊断系统
- 深蓝(Deep Blue):1997年击败国际象棋世界冠军卡斯帕罗夫,标志着符号AI的巅峰
然而,符号主义面临根本性局限:知识获取瓶颈(难以穷举所有规则)和常识推理困难。当问题复杂度增加时,规则组合呈指数级爆炸,系统变得难以维护。
第二次浪潮(1980-1990年代):连接主义的蛰伏与觉醒
连接主义(Connectionism)模拟大脑神经网络的工作方式,通过调整神经元之间的连接权重来学习。1958年,罗森布拉特(Frank Rosenblatt)提出了感知机(Perceptron),这是神经网络的原型。然而,1969年明斯基(Marvin Minsky)在《感知机》一书中证明了单层网络的局限性(无法解决异或问题),导致连接主义研究陷入长达20年的低谷。
1986年,反向传播算法(Backpropagation)的提出为多层神经网络训练提供了可行方案。但受限于当时的计算能力和数据规模,神经网络的表现仍不及传统的机器学习方法如支持向量机(SVM)。
第三次浪潮(2006年至今):深度学习的革命
2006年,Hinton等人提出深度信念网络(Deep Belief Network),标志着深度学习时代的开启。2012年,AlexNet在ImageNet图像分类竞赛中以压倒性优势夺冠,将图像识别错误率从26%降至15%,引发了学术界和工业界对深度学习的广泛关注。
深度学习革命的核心驱动力来自三方面:
- 大数据:ImageNet等大规模标注数据集的出现
- 算力爆发:GPU并行计算能力的大幅提升
- 算法突破:ReLU激活函数、批归一化、残差连接等技术解决了深层网络训练的梯度消失问题
表1-1 AI发展关键里程碑
| 年份 | 事件 | 技术意义 |
|---|---|---|
| 1956 | 达特茅斯会议 | AI概念正式诞生 |
| 1958 | 感知机提出 | 连接主义起点 |
| 1980s | 专家系统兴起 | 符号主义商业化应用 |
| 1997 | 深蓝战胜卡斯帕罗夫 | 符号AI巅峰 |
| 2006 | 深度信念网络 | 深度学习开端 |
| 2012 | AlexNet夺冠 | 深度学习爆发点 |
| 2016 | AlphaGo战胜李世石 | 强化学习里程碑 |
| 2017 | Transformer架构提出 | 大模型时代基础 |
| 2020 | GPT-3发布 | 大模型能力飞跃 |
| 2022 | ChatGPT发布 | AI应用全民化 |
| 2024 | GPT-4o/Sora发布 | 多模态能力突破 |
| 2025 | GPT-5/DeepSeek-R1 | 推理能力大幅提升 |
从上表可以看出,AI发展呈现出明显的加速趋势。从1956年概念诞生到2012年深度学习爆发,历时56年;而从2017年Transformer架构提出到2025年GPT-5发布,仅用了8年时间,技术迭代速度提升了近7倍。这种加速态势意味着学习者需要建立持续学习的意识,紧跟技术前沿。
1.1.2 机器学习到深度学习的演进:数据驱动范式的转变
机器学习(Machine Learning, ML)与深度学习(Deep Learning, DL)的关系,类似于"工具箱"与"精密仪器"的关系。理解两者的演进路径,有助于把握AI技术的本质特征。
传统机器学习的特征
传统机器学习方法包括线性回归、逻辑回归、决策树、支持向量机(SVM)、随机森林等。这些方法的核心特点是:
- 特征工程依赖:需要领域专家手工设计特征,将原始数据转换为模型可理解的表示形式
- 数据需求适中:通常在数千至数百万样本规模即可训练出有效模型
- 可解释性强:模型决策过程相对透明,便于理解和调试
- 计算成本低:可在普通CPU上快速训练和推理
深度学习的范式转变
深度学习带来的核心变革是表征学习(Representation Learning)。与传统方法不同,深度学习模型能够自动从原始数据中学习层次化的特征表示:
- 底层:学习边缘、纹理等基本视觉元素
- 中层:学习形状、部件等中间抽象
- 高层:学习完整对象或概念的语义表示
这种自动特征提取能力使得深度学习在图像识别、语音识别、自然语言处理等领域取得了突破性进展。2012年ImageNet竞赛中,AlexNet以15.3%的top-5错误率夺冠,而传统方法的最佳成绩仅为26.2%,性能提升幅度超过40%。
数据驱动范式的深化
从机器学习到深度学习的演进,本质上是数据驱动范式的深化。传统机器学习中,算法设计占据核心地位;而在深度学习中,数据规模和计算资源成为决定模型性能的关键因素。这一转变带来了新的行业格局:拥有海量数据的大型科技公司(如Google、Meta、OpenAI)在AI领域占据了主导地位。
1.1.3 大模型时代的开启:GPT系列与ChatGPT现象
2022年11月30日,OpenAI发布ChatGPT,这一事件被普遍认为是AI发展史上的分水岭。ChatGPT在发布后5天内用户突破100万,两个月内月活用户超过1亿,成为人类历史上增长最快的消费级应用。
GPT系列模型演进
GPT(Generative Pre-trained Transformer)系列模型的发展轨迹清晰地展示了大模型能力的跃升:
- GPT-1(2018):1.17亿参数,证明生成式预训练的有效性
- GPT-2(2019):15亿参数,展现零样本学习能力
- GPT-3(2020):1750亿参数,涌现上下文学习和推理能力
- GPT-4(2023):约1.8万亿参数,支持多模态输入,在多项专业考试中达到人类水平
- GPT-4o(2024):优化多模态能力,实现音频直接输出
- GPT-5(2025):内置高级思考能力,成为"最智能、最快、最有用的模型"
参数规模的指数级增长带来了模型能力的质变。研究表明,当模型参数超过一定阈值(约600亿)时,会出现涌现能力(Emergent Abilities)——模型突然展现出训练时未明确教授的新能力。
ChatGPT现象的产业影响
ChatGPT的爆火不仅是一项技术突破,更引发了全球性的AI产业变革:
- 资本涌入:2023年全球生成式AI投资超过250亿美元
- 人才竞争:AI研究员年薪飙升至百万美元级别
- 应用爆发:从内容创作到代码生成,从教育辅导到医疗咨询,AI应用场景快速扩展
- 中国跟进:百度文心一言、阿里通义千问、字节豆包等国产大模型相继发布
2025年的最新趋势显示,大模型发展已从"参数竞赛"转向"效率优化"。阿里云Qwen3模型仅激活220亿参数就能超越千亿级模型性能,部署成本降低67%。华为盘古通过快慢思考切换技术,推理效率提升8倍。这表明大模型技术正在走向成熟和实用化。
1.2 AI技术体系概览
AI技术体系庞大而复杂,涵盖从基础算法到应用系统的多个层次。本节将从机器学习核心分支、深度学习主要架构、大语言模型技术栈、多模态与前沿方向四个维度,为读者勾勒完整的技术地图。
1.2.1 机器学习核心分支:监督学习、无监督学习、强化学习
机器学习的三大范式——监督学习、无监督学习和强化学习——构成了AI技术的基础框架。理解它们的区别与适用场景,是掌握AI技术的第一步。
监督学习(Supervised Learning)
监督学习从标注数据中学习输入到输出的映射关系,类似于"有老师指导的学习"。其核心要素包括:
- 数据形式:成对的输入-输出样本(X, y)
- 任务类型:分类(预测离散标签)和回归(预测连续值)
- 典型算法:线性回归、逻辑回归、决策树、支持向量机、神经网络
- 应用场景:垃圾邮件检测、房价预测、医疗诊断、信用评分
监督学习的优势在于目标明确、效果可量化,但依赖高质量的标注数据,数据获取成本较高。
无监督学习(Unsupervised Learning)
无监督学习从无标注数据中发现隐藏的模式和结构。其核心要素包括:
- 数据形式:仅有输入样本,无对应输出标签
- 任务类型:聚类(将数据分组)、降维(减少特征维度)、关联规则挖掘
- 典型算法:K-Means聚类、层次聚类、主成分分析(PCA)、自编码器
- 应用场景:客户分群、异常检测、推荐系统、数据可视化
无监督学习的优势在于无需标注数据,可以发现数据中未知的模式,但评估难度较大,结果解释性相对较弱。
强化学习(Reinforcement Learning, RL)
强化学习通过与环境的交互来学习最优行为策略。其核心要素包括:
- 核心概念:智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)
- 学习目标:最大化长期累积奖励
- 典型算法:Q-Learning、DQN、策略梯度、PPO
- 应用场景:游戏AI(AlphaGo)、机器人控制、自动驾驶、资源调度
强化学习的优势在于能够处理序列决策问题,适应动态环境,但训练难度大、样本效率低,且对奖励函数设计敏感。
表1-2 三种机器学习范式对比
| 维度 | 监督学习 | 无监督学习 | 强化学习 |
|---|---|---|---|
| 数据类型 | 标注数据(X, y) | 无标注数据(X) | 无预设数据,环境交互 |
| 学习方式 | 从标注中学习映射 | 发现数据内在结构 | 试错学习,奖励驱动 |
| 典型任务 | 分类、回归 | 聚类、降维、异常检测 | 序列决策、控制优化 |
| 代表算法 | SVM、决策树、神经网络 | K-Means、PCA、自编码器 | Q-Learning、DQN、PPO |
| 主要挑战 | 数据标注成本高 | 评估和解释困难 | 样本效率低、训练不稳定 |
| 典型应用 | 图像分类、情感分析 | 客户分群、推荐系统 | 游戏AI、机器人、自动驾驶 |
从表中可以看出,三种范式各有优势和局限。在实际应用中,它们往往结合使用:例如,先用无监督学习进行数据预处理和特征学习,再用监督学习训练分类器;或先通过监督学习预训练模型,再通过强化学习进行策略优化。
1.2.2 深度学习主要架构:CNN、RNN、Transformer
深度学习的发展离不开神经网络架构的持续创新。卷积神经网络(CNN)、循环神经网络(RNN)和Transformer是三种最具影响力的架构,分别在不同领域取得了突破性成果。
卷积神经网络(CNN)
CNN专为处理网格状数据(如图像)而设计,其核心创新是卷积操作,通过局部连接和权重共享大幅减少参数数量。
- LeNet-5(1998):最早的CNN架构之一,6万个参数,用于手写数字识别
- AlexNet(2012):6000万参数,引入ReLU激活和Dropout,ImageNet竞赛夺冠
- VGGNet(2014):1.38亿参数,使用3×3小卷积核堆叠,结构规整
- ResNet(2015):2500万参数,引入残差连接,可训练152层以上的深层网络
CNN在计算机视觉领域占据主导地位,广泛应用于图像分类、目标检测、语义分割等任务。
循环神经网络(RNN)
RNN专为处理序列数据而设计,能够捕捉时间维度上的依赖关系。
- 基础RNN:简单的循环结构,但存在梯度消失/爆炸问题
- LSTM(1997):引入门控机制,解决长程依赖问题,1-1000万参数规模
- GRU:LSTM的简化变体,参数更少,训练更快
- BiLSTM:双向LSTM,同时捕捉前后文信息
RNN曾广泛应用于自然语言处理任务,如机器翻译、文本生成、语音识别等。但随着Transformer的兴起,RNN在NLP领域的主导地位已被取代。
Transformer
2017年,Google在论文《Attention Is All You Need》中提出Transformer架构,彻底改变了NLP领域。其核心创新是自注意力机制(Self-Attention),能够并行处理序列中的所有位置,捕捉长距离依赖关系。
Transformer架构的优势包括:
- 并行计算:不像RNN需要顺序处理,Transformer可并行处理整个序列
- 长程依赖:自注意力机制直接建模任意两个位置的关系
- 可扩展性:模型规模可从百万级扩展到万亿级参数
表1-3 深度学习架构演进与参数规模
| 架构类型 | 代表模型 | 年份 | 参数规模 | 主要应用领域 |
|---|---|---|---|---|
| FNN | LeNet-5 | 1998 | 60K | 手写数字识别 |
| RNN | LSTM | 1997 | 1-10M | 序列建模、NLP |
| CNN | AlexNet | 2012 | 60M | 图像分类 |
| CNN | VGG-16 | 2014 | 138M | 计算机视觉 |
| CNN | ResNet-50 | 2015 | 25M | 图像识别 |
| Transformer | GPT-3 | 2020 | 175B | 自然语言处理 |
| Transformer | GPT-4 | 2023 | 1T | 多模态AI |
| Transformer | DeepSeek-V3 | 2024 | 671B | 通用人工智能 |
从上表可以观察到两个明显趋势:一是参数规模呈指数级增长,从60K到1T增长了约1600万倍;二是Transformer架构自2017年后快速崛起,成为大模型的标准架构。这种规模扩张带来了能力的质变,但也对计算资源和训练数据提出了更高要求。
1.2.3 大语言模型技术栈:预训练、微调、对齐
大语言模型(Large Language Model, LLM)的训练是一个复杂的系统工程,通常包括预训练(Pre-training)、监督微调(SFT)和对齐(Alignment)三个阶段。
预训练阶段
预训练是构建大语言模型的基础阶段,目标是让模型学习语言的通用表示和世界知识。
- 数据规模:数千亿至数万亿token的未标注文本
- 训练目标:下一个token预测(Causal Language Modeling)
- 计算成本:千亿参数模型需数万GPU小时
- 输出成果:基础模型(Base Model),具备文本补全和零样本泛化能力
预训练阶段决定了模型的"知识储备"和"语言能力",是后续所有能力的基础。
监督微调(SFT)阶段
监督微调使用人工标注的指令-响应对,使模型学会遵循人类指令。
- 数据形式:成对的<指令, 回复>数据,如"写一首关于春天的诗"→"春风拂面柳丝长..."
- 数据规模:通常1K-50K高质量样本
- 训练目标:与预训练相同(下一个token预测),但数据格式不同
- 关键要求:数据多样性(覆盖不同任务类型)和高质量(人工标注或大模型筛选)
SFT使模型从"文本补全器"转变为"指令跟随者",能够理解和执行人类的自然语言指令。
对齐阶段(RLHF/DPO)
对齐阶段的目标是使模型输出符合人类价值观,做到"有用、诚实、无害"。
**RLHF(基于人类反馈的强化学习)**流程包括:
- 收集偏好数据:人类评审员对模型生成的多个回答进行排序
- 训练奖励模型:学习预测人类偏好分数
- PPO优化:使用近端策略优化算法微调模型,最大化奖励分数
**DPO(直接偏好优化)**是2024年兴起的新方法,无需训练奖励模型,直接优化偏好对比损失,简化了流程且稳定性更高。
表1-4 LLM训练三阶段对比
| 阶段 | 预训练 | 监督微调(SFT) | 对齐(RLHF/DPO) |
|---|---|---|---|
| 数据类型 | 无标注文本 | 指令-响应对 | 偏好排序数据 |
| 数据规模 | 万亿级token | 千至万级样本 | 万级偏好对 |
| 训练目标 | 下一个token预测 | 下一个token预测 | 奖励最大化/偏好优化 |
| 计算成本 | 最高(数万GPU小时) | 中等(数百GPU小时) | 较高(数千GPU小时) |
| 主要产出 | 基础语言能力 | 指令跟随能力 | 价值观对齐 |
从技术趋势看,2024-2025年对齐技术正在经历从RLHF向DPO等新方法的转变。DPO等直接优化方法无需训练单独的奖励模型,大幅简化了对齐流程,同时保持了与RLHF相当甚至更优的效果。这一趋势表明,大模型技术正在从"大力出奇迹"向"效率优化"演进。
1.2.4 多模态与前沿方向:视觉-语言模型、具身智能
大模型技术正在从单一模态向多模态融合演进,同时与物理世界的交互能力也在不断增强。
多模态大模型
多模态大模型能够理解和生成多种类型的数据(文本、图像、音频、视频),实现跨模态的理解和推理。
- GPT-4V(2023):支持图像输入,可理解图片内容并回答相关问题
- GPT-4o(2024):实现音频直接输入输出,响应延迟降至毫秒级
- Sora(2024):文本生成视频模型,可生成长达20秒的高质量视频
- Gemini:原生多模态架构,文本、图像、音频、视频、代码五模态统一处理
多模态能力的突破使AI应用边界大幅扩展。例如,用户可上传一张冰箱内食材的照片,AI可直接生成相应的菜谱建议,无需人工描述食材内容。
具身智能(Embodied AI)
具身智能是指具有物理实体、能与环境交互的AI系统。2025年被业界认为是具身智能从"表演"走向"实用"的关键年份。
具身智能的技术架构包括:
- 物理实践:机器人在真实环境中积累经验,理解物体属性和物理规律
- 物理仿真器:在虚拟环境中进行大规模试错学习,加速技能掌握
- 世界模型:从海量数据中提取环境运行规律,实现"先思考后行动"
- 端到端决策:将感知直接映射到动作,实现快速响应
2025年具身智能领域的投资呈现爆发式增长。据统计,2025年前三季度国内机器人行业融资约500亿元,是2024年同期的2.5倍。从春晚舞台表演到深圳地铁安检机器人,从北京人形机器人马拉松到工厂产线应用,具身智能正在从"玩具"转变为"同事"。
前沿方向展望
除多模态和具身智能外,AI领域还有若干值得关注的前沿方向:
- AI Agent:能够自主规划、使用工具、完成复杂任务的智能体
- 科学发现AI:用于药物研发、材料设计、数学定理证明等领域
- 神经符号AI:结合神经网络的模式识别能力和符号推理的逻辑严谨性
- 高效推理:模型压缩、量化、蒸馏等技术,降低部署成本
学习内容
Python的数据类型系统简洁而强大,理解其核心特性是高效编程的基础。Python内置的常用数据类型包括数值型(int、float、complex)、序列型(list、tuple、str、range)、映射型(dict)以及集合型(set、frozenset)。
列表(List) 是Python中最常用的可变序列类型,支持动态扩容和异构元素存储:
# 列表创建与基本操作
numbers = [1, 2, 3, 4, 5]
mixed = [1, "hello", 3.14, True] # 异构元素
# 列表推导式 - Pythonic的优雅写法
squares = [x**2 for x in range(10)] # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
evens = [x for x in range(20) if x % 2 == 0] # 条件过滤
# 切片操作
subset = numbers[1:4] # [2, 3, 4]
reversed_list = numbers[::-1] # [5, 4, 3, 2, 1]
字典(Dictionary) 提供键值对的快速查找,平均时间复杂度为O(1):
# 字典创建与操作
student = {
"name": "张三",
"age": 25,
"scores": [85, 90, 78]
}
# 字典推导式
word_freq = {"apple": 3, "banana": 5, "cherry": 2}
doubled = {k: v*2 for k, v in word_freq.items()} # {'apple': 6, 'banana': 10, 'cherry': 4}
# get方法提供默认值,避免KeyError
score = student.get("gpa", 0.0) # 返回0.0而非抛出异常
控制结构 方面,Python使用缩进来定义代码块,这种强制性的格式规范提高了代码可读性:
# 条件语句
age = 25
category = "成年" if age >= 18 else "未成年" # 三元表达式
# 循环结构
# enumerate同时获取索引和值
fruits = ["apple", "banana", "cherry"]
for idx, fruit in enumerate(fruits):
print(f"{idx}: {fruit}")
# zip并行迭代
names = ["Alice", "Bob", "Charlie"]
scores = [85, 92, 78]
for name, score in zip(names, scores):
print(f"{name}: {score}")
# 列表处理常用模式
# 使用any/all进行条件判断
has_positive = any(x > 0 for x in numbers)
all_positive = all(x > 0 for x in numbers)
2.1.2 函数与面向对象编程
函数定义 在Python中通过def关键字实现,支持默认参数、可变参数和关键字参数:
# 函数定义与参数
from typing import List, Union, Optional
def process_data(
data: List[float],
threshold: float = 0.5,
*, # 关键字参数分隔符
verbose: bool = False
) -> List[float]:
"""
处理数据,过滤低于阈值的元素。
Args:
data: 输入数据列表
threshold: 过滤阈值
verbose: 是否打印详细信息
Returns:
过滤后的数据列表
"""
result = [x for x in data if x >= threshold]
if verbose:
print(f"原始数据: {len(data)}条, 过滤后: {len(result)}条")
return result
# 可变参数与解包
def sum_all(*args: float) -> float:
"""接受任意数量的参数"""
return sum(args)
# 关键字参数
def create_config(**kwargs) -> dict:
"""接受任意关键字参数"""
defaults = {"learning_rate": 0.01, "epochs": 100}
defaults.update(kwargs)
return defaults
面向对象编程 是组织复杂代码的核心范式。Python支持封装、继承和多态三大特性:
from abc import ABC, abstractmethod
from dataclasses import dataclass
# 抽象基类定义接口
class DataProcessor(ABC):
"""数据处理器抽象基类"""
def __init__(self, name: str):
self.name = name
self.processed_count = 0
@abstractmethod
def process(self, data):
"""子类必须实现的处理方法"""
pass
def get_stats(self) -> dict:
"""获取处理统计信息"""
return {"name": self.name, "processed": self.processed_count}
# 具体实现类
class Normalizer(DataProcessor):
"""数据归一化处理器"""
def __init__(self, name: str, method: str = "minmax"):
super().__init__(name)
self.method = method
def process(self, data: List[float]) -> List[float]:
if not data:
return []
if self.method == "minmax":
min_val, max_val = min(data), max(data)
range_val = max_val - min_val if max_val != min_val else 1
result = [(x - min_val) / range_val for x in data]
else:
# Z-score标准化
mean = sum(data) / len(data)
std = (sum((x - mean) ** 2 for x in data) / len(data)) ** 0.5
std = std if std > 0 else 1
result = [(x - mean) / std for x in data]
self.processed_count += len(data)
return result
# 使用dataclass简化数据类定义
@dataclass
class Dataset:
"""数据集类"""
features: List[List[float]]
labels: List[int]
name: str = "unnamed"
def __len__(self) -> int:
return len(self.labels)
def get_shape(self) -> tuple:
if not self.features:
return (0, 0)
return (len(self.features), len(self.features[0]))
2.1.3 模块管理与虚拟环境
模块导入 遵循特定的搜索路径规则:当前目录 → PYTHONPATH → 标准库 → 第三方库。理解这一机制有助于解决导入问题:
# 导入方式对比
import numpy as np # 推荐:使用别名
from pandas import DataFrame # 导入特定类
from matplotlib import pyplot as plt # 子模块导入
# 相对导入(在包内部使用)
from . import utils # 同级目录
from ..config import settings # 上级目录
虚拟环境 是隔离项目依赖的标准做法。venv是Python 3.3+内置的虚拟环境工具:
# 创建虚拟环境
python -m venv myproject_env
# 激活虚拟环境
# Linux/macOS:
source myproject_env/bin/activate
# Windows:
myproject_env\Scripts\activate
# 导出依赖
pip freeze > requirements.txt
# 安装依赖
pip install -r requirements.txt
Conda 是数据科学领域更流行的环境管理工具,特别适合管理非Python依赖(如CUDA):
# 创建环境
conda create -n datasci python=3.11 numpy pandas matplotlib
# 激活环境
conda activate datasci
# 导出环境
conda env export > environment.yml
# 从文件创建环境
conda env create -f environment.yml
依赖管理最佳实践:
# requirements.txt 示例
numpy>=1.24.0,<2.0.0 # 版本范围
pandas==2.0.3 # 固定版本
matplotlib>=3.7.0 # 最低版本
scikit-learn # 最新版本
| 工具 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| venv | 纯Python项目 | 轻量、内置 | 无法管理非Python依赖 |
| conda | 数据科学项目 | 支持二进制依赖、环境隔离彻底 | 体积较大、启动较慢 |
| pipenv | Web开发 | 自动管理依赖锁定 | 社区支持度下降 |
| poetry | 现代Python项目 | 依赖解析智能、构建工具集成 | 学习曲线较陡 |
上表对比了主流Python环境管理工具的特性。对于AI和数据科学项目,conda因其对科学计算库(如NumPy、SciPy)及其底层依赖(BLAS、MKL)的良好支持而成为首选。venv适合轻量级项目,而poetry在依赖管理和打包发布方面提供了更现代化的体验。
2.2 NumPy数值计算
NumPy(Numerical Python)是Python科学计算的基础库,提供了高性能的多维数组对象和丰富的数学函数库。根据GitHub统计,NumPy的月下载量超过1亿次,是数据科学生态系统的核心组件。
2.2.1 数组创建与索引操作
ndarray 是NumPy的核心数据结构,它是一个同构多维数组,所有元素具有相同的数据类型:
import numpy as np
# 数组创建方法
# 从列表创建
arr1 = np.array([1, 2, 3, 4, 5])
# 创建特定形状的数组
zeros = np.zeros((3, 4)) # 3x4零矩阵
ones = np.ones((2, 3, 4)) # 2x3x4全1张量
identity = np.eye(5) # 5x5单位矩阵
# 等差数列
linear = np.linspace(0, 10, 50) # 0到10之间的50个等间距点
arange = np.arange(0, 10, 0.5) # 步长为0.5的序列
# 随机数组
np.random.seed(42) # 设置随机种子保证可复现
rand_uniform = np.random.rand(3, 3) # 均匀分布[0,1)
rand_normal = np.random.randn(3, 3) # 标准正态分布
rand_int = np.random.randint(0, 100, (5, 5)) # 随机整数
索引与切片 支持多维索引和布尔索引:
# 创建示例数组
arr = np.arange(24).reshape(4, 6)
print("原始数组形状:", arr.shape) # (4, 6)
# 基本索引
row = arr[2] # 第3行
element = arr[1, 3] # 第2行第4列
# 切片
subarray = arr[1:3, 2:5] # 行1-2,列2-4
# 布尔索引 - 条件筛选
mask = arr > 10
filtered = arr[mask] # 所有大于10的元素
# 花式索引
rows = [0, 2, 3]
cols = [1, 4, 5]
selected = arr[rows, cols] # 取(0,1), (2,4), (3,5)位置的元素
# 条件赋值
arr[arr < 5] = 0 # 将小于5的元素设为0
2.2.2 广播机制与向量化运算
广播(Broadcasting) 是NumPy最强大的特性之一,它允许不同形状的数组进行算术运算而无需显式复制数据。广播遵循以下规则:
- 如果两个数组维度数不同,将较小维度数组的形状前面补1,直到维度数相同
- 如果两个数组在某个维度大小不同,且其中一个为1,则在该维度进行广播
- 如果两个数组在某个维度大小不同且都不为1,则报错
# 广播示例
A = np.array([[1, 2, 3],
[4, 5, 6]]) # 形状 (2, 3)
b = np.array([10, 20, 30]) # 形状 (3,) -> 广播为 (1, 3) -> (2, 3)
result = A + b
# [[11, 22, 33],
# [14, 25, 36]]
# 列向量广播
c = np.array([[1], [2]]) # 形状 (2, 1)
result2 = A + c
# [[2, 3, 4],
# [6, 7, 8]]
# 使用newaxis显式控制广播
row_vec = np.array([1, 2, 3]) # (3,)
col_vec = np.array([10, 20]) # (2,)
result3 = row_vec[np.newaxis, :] + col_vec[:, np.newaxis] # (2, 3)
向量化运算 替代Python循环,可显著提升性能:
import time
# 性能对比:循环 vs 向量化
size = 1000000
a = np.random.rand(size)
b = np.random.rand(size)
# 方法1: Python循环(慢)
start = time.time()
result_loop = []
for i in range(size):
result_loop.append(a[i] + b[i])
loop_time = time.time() - start
# 方法2: NumPy向量化(快)
start = time.time()
result_vectorized = a + b
vector_time = time.time() - start
print(f"循环耗时: {loop_time:.4f}s")
print(f"向量化耗时: {vector_time:.4f}s")
print(f"加速比: {loop_time/vector_time:.1f}x")
2.2.3 线性代数运算与随机数
NumPy的linalg模块提供了完整的线性代数运算功能,这些运算是机器学习算法的数学基础:
# 线性代数运算
A = np.array([[4, 2], [3, 1]])
B = np.array([[1, 2], [3, 4]])
# 矩阵乘法
C = A @ B # 或 np.dot(A, B)
# [[10, 16],
# [ 6, 10]]
# 矩阵转置和逆
A_T = A.T
A_inv = np.linalg.inv(A)
# 行列式和迹
det_A = np.linalg.det(A)
trace_A = np.trace(A)
# 特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(A)
# 解线性方程组 Ax = b
b = np.array([1, 2])
x = np.linalg.solve(A, b)
# SVD分解(奇异值分解)
U, S, Vh = np.linalg.svd(A)
# 矩阵范数
frobenius_norm = np.linalg.norm(A, 'fro')
spectral_norm = np.linalg.norm(A, 2)
随机数生成 在机器学习中用于权重初始化、数据增强和蒙特卡洛模拟:
# 随机数生成
np.random.seed(42)
# 各种分布
uniform = np.random.uniform(0, 1, 1000) # 均匀分布
normal = np.random.normal(0, 1, 1000) # 正态分布(均值0, 标准差1)
exp = np.random.exponential(1.0, 1000) # 指数分布
poisson = np.random.poisson(5, 1000) # 泊松分布
# 随机采样
population = np.arange(100)
sample = np.random.choice(population, size=10, replace=False) # 无放回抽样
# 打乱数组
shuffled = np.random.permutation(population)
# 多维随机数组
random_2d = np.random.randn(3, 4, 5) # 3x4x5的正态分布数组
2.3 Pandas数据处理
Pandas是Python数据处理的事实标准库,提供了DataFrame和Series两种核心数据结构。根据KDnuggets调查,Pandas在数据科学家工具使用排名中稳居前三。
2.3.1 DataFrame与Series基础
Series 是一维带标签数组,DataFrame 是二维表格型数据结构:
import pandas as pd
import numpy as np
# Series创建
s = pd.Series([1, 3, 5, np.nan, 6, 8], name="values")
print(s)
# 0 1.0
# 1 3.0
# 2 5.0
# 3 NaN
# 4 6.0
# 5 8.0
# Name: values, dtype: float64
# DataFrame创建
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'age': [25, 30, 35, 28],
'salary': [50000, 60000, 75000, 55000],
'department': ['IT', 'HR', 'IT', 'Finance']
})
# 从NumPy数组创建
df_from_array = pd.DataFrame(
np.random.randn(5, 3),
columns=['A', 'B', 'C'],
index=['row1', 'row2', 'row3', 'row4', 'row5']
)
# 基本信息查看
print(df.info())
print(df.describe()) # 统计摘要
print(df.head(3)) # 前3行
print(df.tail(2)) # 后2行
数据选择 提供多种索引方式:
# 列选择
ages = df['age'] # 单列(Series)
subset = df[['name', 'age']] # 多列(DataFrame)
# 行选择(loc vs iloc)
row = df.loc[0] # 按标签索引
row = df.iloc[0] # 按位置索引
# 条件筛选
it_staff = df[df['department'] == 'IT']
high_earners = df[df['salary'] > 55000]
# 多条件筛选
filtered = df[(df['age'] > 25) & (df['salary'] > 55000)]
# 使用query方法(更简洁)
result = df.query("age > 25 and salary > 55000")
2.3.2 数据清洗与缺失值处理
真实数据往往存在缺失值、异常值和格式不一致等问题,数据清洗是数据分析的关键步骤:
# 创建含缺失值的示例数据
df_dirty = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': ['a', 'b', 'c', None, 'e'],
'C': [10, np.nan, 30, 40, 50],
'D': ['2023-01-01', 'invalid', '2023-03-01', '2023-04-01', '2023-05-01']
})
# 检测缺失值
print(df_dirty.isnull().sum()) # 每列缺失值数量
print(df_dirty.isnull().mean() * 100) # 缺失值百分比
# 处理缺失值
# 方法1: 删除含缺失值的行
df_clean = df_dirty.dropna() # 删除任何含NaN的行
df_clean = df_dirty.dropna(subset=['A', 'C']) # 仅检查指定列
df_clean = df_dirty.dropna(thresh=3) # 保留至少有3个非NaN值的行
# 方法2: 填充缺失值
df_filled = df_dirty.copy()
df_filled['A'] = df_filled['A'].fillna(df_filled['A'].mean()) # 均值填充
df_filled['B'] = df_filled['B'].fillna('unknown') # 常量填充
df_filled['C'] = df_filled['C'].fillna(method='ffill') # 前向填充
# 方法3: 插值
df_interpolated = df_dirty.copy()
df_interpolated['A'] = df_interpolated['A'].interpolate(method='linear')
# 处理重复值
print(df.duplicated().sum()) # 重复行数量
df_unique = df.drop_duplicates()
df_unique = df.drop_duplicates(subset=['name'], keep='first') # 按列去重
# 数据类型转换
df['D'] = pd.to_datetime(df['D'], errors='coerce') # 转换日期,无效值设为NaT
df['age'] = df['age'].astype(int) # 整数转换
df['salary'] = pd.to_numeric(df['salary'], errors='coerce') # 数值转换
异常值检测与处理:
# IQR方法检测异常值
Q1 = df['salary'].quantile(0.25)
Q3 = df['salary'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['salary'] < lower_bound) | (df['salary'] > upper_bound)]
# Z-score方法
from scipy import stats
z_scores = np.abs(stats.zscore(df['salary'].dropna()))
outliers_z = df[z_scores > 3]
# 异常值处理:截断
df['salary_capped'] = df['salary'].clip(lower=lower_bound, upper=upper_bound)
2.3.3 数据分组与聚合分析
groupby 是Pandas最强大的功能之一,支持SQL风格的分组聚合操作:
# 创建示例数据
sales_df = pd.DataFrame({
'date': pd.date_range('2023-01-01', periods=100, freq='D'),
'product': np.random.choice(['A', 'B', 'C'], 100),
'region': np.random.choice(['North', 'South', 'East', 'West'], 100),
'quantity': np.random.randint(1, 50, 100),
'price': np.random.uniform(10, 100, 100)
})
sales_df['revenue'] = sales_df['quantity'] * sales_df['price']
# 基础分组聚合
product_stats = sales_df.groupby('product').agg({
'quantity': ['sum', 'mean', 'std'],
'revenue': ['sum', 'mean', 'count']
})
# 多列分组
region_product = sales_df.groupby(['region', 'product']).agg({
'revenue': 'sum',
'quantity': 'mean'
}).reset_index()
# 自定义聚合函数
def profit_margin(x):
return (x.sum() * 0.3) / x.sum() # 假设30%利润率
custom_agg = sales_df.groupby('product').agg({
'revenue': ['sum', profit_margin]
})
# transform - 保持原DataFrame形状
sales_df['avg_revenue_by_product'] = sales_df.groupby('product')['revenue'].transform('mean')
# apply - 更灵活的自定义操作
def top_n_revenue(group, n=3):
return group.nlargest(n, 'revenue')[['date', 'revenue']]
top_sales = sales_df.groupby('product').apply(top_n_revenue, n=2)
透视表与交叉表:
# 透视表
pivot = pd.pivot_table(
sales_df,
values='revenue',
index='region',
columns='product',
aggfunc='sum',
fill_value=0,
margins=True # 添加总计行/列
)
# 交叉表(专门用于频数统计)
cross_tab = pd.crosstab(
sales_df['region'],
sales_df['product'],
values=sales_df['revenue'],
aggfunc='sum',
normalize='index' # 按行归一化
)
2.3.4 数据合并与重塑操作
数据合并 是整合多数据源的核心操作:
# 创建示例数据
df1 = pd.DataFrame({
'id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'dept_id': [101, 102, 101, 103]
})
df2 = pd.DataFrame({
'dept_id': [101, 102, 103],
'dept_name': ['IT', 'HR', 'Finance'],
'location': ['NYC', 'LA', 'Chicago']
})
df3 = pd.DataFrame({
'id': [1, 2, 5],
'bonus': [1000, 2000, 1500]
})
# merge - 类似SQL JOIN
# 内连接
inner_join = pd.merge(df1, df2, on='dept_id', how='inner')
# 左连接(保留左表所有行)
left_join = pd.merge(df1, df3, on='id', how='left')
# 右连接
right_join = pd.merge(df1, df3, on='id', how='right')
# 外连接
outer_join = pd.merge(df1, df3, on='id', how='outer')
# 多键连接
multi_key = pd.merge(df1, df2, left_on='dept_id', right_on='dept_id')
# concat - 轴向连接
df_vertical = pd.concat([df1, df1], axis=0, ignore_index=True) # 纵向连接
df_horizontal = pd.concat([df1, df3], axis=1) # 横向连接
数据重塑 在数据预处理中经常使用:
# 创建宽格式数据
wide_df = pd.DataFrame({
'id': [1, 2, 3],
'math_score': [85, 90, 78],
'english_score': [88, 92, 80],
'science_score': [90, 85, 88]
})
# melt - 宽格式转长格式
long_df = pd.melt(
wide_df,
id_vars=['id'],
value_vars=['math_score', 'english_score', 'science_score'],
var_name='subject',
value_name='score'
)
# pivot - 长格式转宽格式
wide_back = long_df.pivot(index='id', columns='subject', values='score')
# stack/unstack - 层级索引操作
stacked = wide_df.set_index('id').stack()
unstacked = stacked.unstack()
完整数据清洗流程示例:
def clean_dataset(df):
"""
完整的数据清洗流程
"""
df_clean = df.copy()
# 1. 处理缺失值
# 数值列用中位数填充
numeric_cols = df_clean.select_dtypes(include=[np.number]).columns
for col in numeric_cols:
df_clean[col] = df_clean[col].fillna(df_clean[col].median())
# 类别列用众数填充
categorical_cols = df_clean.select_dtypes(include=['object']).columns
for col in categorical_cols:
df_clean[col] = df_clean[col].fillna(df_clean[col].mode()[0])
# 2. 处理异常值(IQR方法)
for col in numeric_cols:
Q1 = df_clean[col].quantile(0.25)
Q3 = df_clean[col].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
df_clean[col] = df_clean[col].clip(lower, upper)
# 3. 删除重复值
df_clean = df_clean.drop_duplicates()
# 4. 数据类型优化
for col in numeric_cols:
if df_clean[col].dtype == 'float64':
df_clean[col] = df_clean[col].astype('float32')
elif df_clean[col].dtype == 'int64':
df_clean[col] = df_clean[col].astype('int32')
return df_clean
# 应用清洗流程
# df_cleaned = clean_dataset(raw_df)
2.4 数据可视化
数据可视化是数据科学的核心技能,它能够将复杂数据转化为直观的图形表达。Matplotlib是Python可视化的基础库,而Seaborn在其基础上提供了更高级的统计可视化功能。根据DataCamp统计,Matplotlib和Seaborn的GitHub星标数分别达到18K和11.6K。
2.4.1 Matplotlib基础绘图
Matplotlib提供了精细的绘图控制,适合创建出版质量的图表:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局样式
plt.rcParams['figure.figsize'] = (10, 6)
plt.rcParams['font.size'] = 11
# 生成示例数据
np.random.seed(42)
x = np.linspace(0, 10, 100)
y1 = np.sin(x) + np.random.normal(0, 0.1, 100)
y2 = np.cos(x) + np.random.normal(0, 0.1, 100)
# 创建图形和子图
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 1. 折线图
axes[0, 0].plot(x, y1, label='sin(x)', linewidth=2, color='#4A6FA5')
axes[0, 0].plot(x, y2, label='cos(x)', linewidth=2, color='#6B8CBB', linestyle='--')
axes[0, 0].set_xlabel('X轴')
axes[0, 0].set_ylabel('Y轴')
axes[0, 0].set_title('折线图示例')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 2. 散点图
categories = np.random.choice(['A', 'B', 'C'], 100)
colors = {'A': '#4A6FA5', 'B': '#6B8CBB', 'C': '#8BA3C7'}
for cat in ['A', 'B', 'C']:
mask = categories == cat
axes[0, 1].scatter(x[mask], y1[mask], label=f'类别{cat}',
alpha=0.6, s=50, color=colors[cat])
axes[0, 1].set_xlabel('X轴')
axes[0, 1].set_ylabel('Y轴')
axes[0, 1].set_title('散点图示例')
axes[0, 1].legend()
# 3. 柱状图
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May']
sales = [120, 150, 180, 140, 200]
bars = axes[1, 0].bar(months, sales, color='#4A6FA5', edgecolor='#2E4A62')
axes[1, 0].set_xlabel('月份')
axes[1, 0].set_ylabel('销售额')
axes[1, 0].set_title('柱状图示例')
# 添加数值标签
for bar in bars:
height = bar.get_height()
axes[1, 0].text(bar.get_x() + bar.get_width()/2., height,
f'{height}', ha='center', va='bottom')
# 4. 直方图
data = np.random.normal(100, 15, 1000)
axes[1, 1].hist(data, bins=30, color='#6B8CBB', edgecolor='white', alpha=0.7)
axes[1, 1].axvline(data.mean(), color='#2E4A62', linestyle='--',
linewidth=2, label=f'均值: {data.mean():.1f}')
axes[1, 1].set_xlabel('数值')
axes[1, 1].set_ylabel('频数')
axes[1, 1].set_title('直方图示例')
axes[1, 1].legend()
plt.tight_layout()
plt.savefig('matplotlib_examples.png', dpi=150, bbox_inches='tight')
plt.show()
2.4.2 Seaborn统计可视化
Seaborn简化了统计图表的创建过程,提供了美观的默认样式:
import seaborn as sns
import pandas as pd
# 设置Seaborn样式
sns.set_style("whitegrid")
sns.set_palette("deep")
# 创建示例数据集
np.random.seed(42)
df = pd.DataFrame({
'x': np.random.randn(200),
'y': np.random.randn(200) * 2 + 1,
'category': np.random.choice(['A', 'B', 'C'], 200),
'value': np.random.exponential(2, 200)
})
# 创建子图
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 1. 分布图(带核密度估计)
sns.histplot(data=df, x='x', kde=True, ax=axes[0, 0], color='#4A6FA5')
axes[0, 0].set_title('分布图与KDE')
# 2. 箱线图
sns.boxplot(data=df, x='category', y='y', ax=axes[0, 1], palette='Blues')
axes[0, 1].set_title('箱线图')
# 3. 小提琴图
sns.violinplot(data=df, x='category', y='value', ax=axes[1, 0], palette='Blues')
axes[1, 0].set_title('小提琴图')
# 4. 配对图(简化版)
# 由于配对图需要整个figure,这里用散点图矩阵代替
for i, cat in enumerate(['A', 'B', 'C']):
mask = df['category'] == cat
axes[1, 1].scatter(df[mask]['x'], df[mask]['y'],
label=f'类别{cat}', alpha=0.6, s=50)
axes[1, 1].set_xlabel('X')
axes[1, 1].set_ylabel('Y')
axes[1, 1].set_title('分类散点图')
axes[1, 1].legend()
plt.tight_layout()
plt.savefig('seaborn_examples.png', dpi=150, bbox_inches='tight')
plt.show()
# 热力图示例
corr_data = df[['x', 'y', 'value']].corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr_data, annot=True, cmap='Blues', fmt='.2f',
square=True, linewidths=0.5)
plt.title('特征相关性热力图')
plt.savefig('heatmap_example.png', dpi=150, bbox_inches='tight')
plt.show()
2.4.3 可视化最佳实践
有效的数据可视化需要遵循一系列设计原则:
图表选择指南:
| 数据类型 | 推荐图表 | 适用场景 |
|---|---|---|
| 时间序列 | 折线图、面积图 | 趋势分析、周期性变化 |
| 分类比较 | 柱状图、条形图 | 类别间数值对比 |
| 分布分析 | 直方图、箱线图、小提琴图 | 数据分布特征、异常值检测 |
| 相关性 | 散点图、热力图 | 变量间关系探索 |
| 占比分析 | 饼图、堆叠柱状图 | 部分与整体关系 |
| 多维度 | 配对图、平行坐标图 | 高维数据可视化 |
配色与可访问性:
# 使用色盲友好的配色方案
colors = sns.color_palette("colorblind", 8)
plt.rcParams['axes.prop_cycle'] = plt.cycler(color=colors)
# 避免仅依靠颜色区分信息
# 好的做法:结合形状、线型
plt.plot(x, y1, 'o-', label='系列1', color=colors[0])
plt.plot(x, y2, 's--', label='系列2', color=colors[1])
标注与注释:
# 添加有意义的标题和标签
plt.title('2023年各季度销售额对比', fontsize=14, fontweight='bold')
plt.xlabel('季度', fontsize=12)
plt.ylabel('销售额(万元)', fontsize=12)
# 突出显示关键数据点
max_idx = np.argmax(sales)
plt.annotate(f'峰值: {sales[max_idx]}',
xy=(months[max_idx], sales[max_idx]),
xytext=(months[max_idx], sales[max_idx] + 20),
arrowprops=dict(arrowstyle='->', color='red'),
fontsize=10, color='red')
图表优化清单:
- 数据-墨水比:最大化数据信息,最小化装饰元素
- 坐标轴范围:数值轴通常应从0开始,避免误导
- 图例位置:放置在不影响数据展示的区域
- 字体大小:确保所有文字清晰可读
- 输出设置:屏幕显示72 DPI,印刷品300+ DPI
# 完整的可视化流程示例
def create_publication_plot(data, title, xlabel, ylabel, save_path):
"""
创建符合出版标准的图表
"""
fig, ax = plt.subplots(figsize=(8, 6), dpi=150)
# 绘制数据
ax.plot(data['x'], data['y'], linewidth=2, color='#4A6FA5')
# 设置标签
ax.set_title(title, fontsize=14, fontweight='bold', pad=15)
ax.set_xlabel(xlabel, fontsize=12)
ax.set_ylabel(ylabel, fontsize=12)
# 优化网格
ax.grid(True, alpha=0.3, linestyle='--')
ax.set_axisbelow(True)
# 移除顶部和右侧边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
# 调整布局
plt.tight_layout()
# 保存
plt.savefig(save_path, dpi=300, bbox_inches='tight',
facecolor='white', edgecolor='none')
plt.show()
2.5 性能优化与工具选择
数据处理库性能对比
随着数据规模的扩大,选择合适的工具变得至关重要。下表对比了主流数据处理库在典型任务上的性能表现:
| 操作 | Pandas 2.2.2 | Polars 1.31.0 | 加速比 |
|---|---|---|---|
| 读取CSV (1M行) | 1.92s | 0.23s | 8.3x |
| 分组聚合 | 0.126s | 0.077s | 1.6x |
| 过滤操作 | 0.70s | 0.07s | 10.0x |
| 写入CSV (1M行) | 20.55s | 10.39s | 2.0x |
数据来源:基于100万行数据集的中位数执行时间测试
上表数据显示,Polars在大多数操作上显著优于Pandas,尤其在读取和过滤操作上优势更为明显。这种性能差异主要源于Polars的Rust底层实现和向量化查询引擎。然而,Pandas凭借其成熟的生态系统和丰富的文档资源,在中小型数据集和快速原型开发中仍具有不可替代的优势。
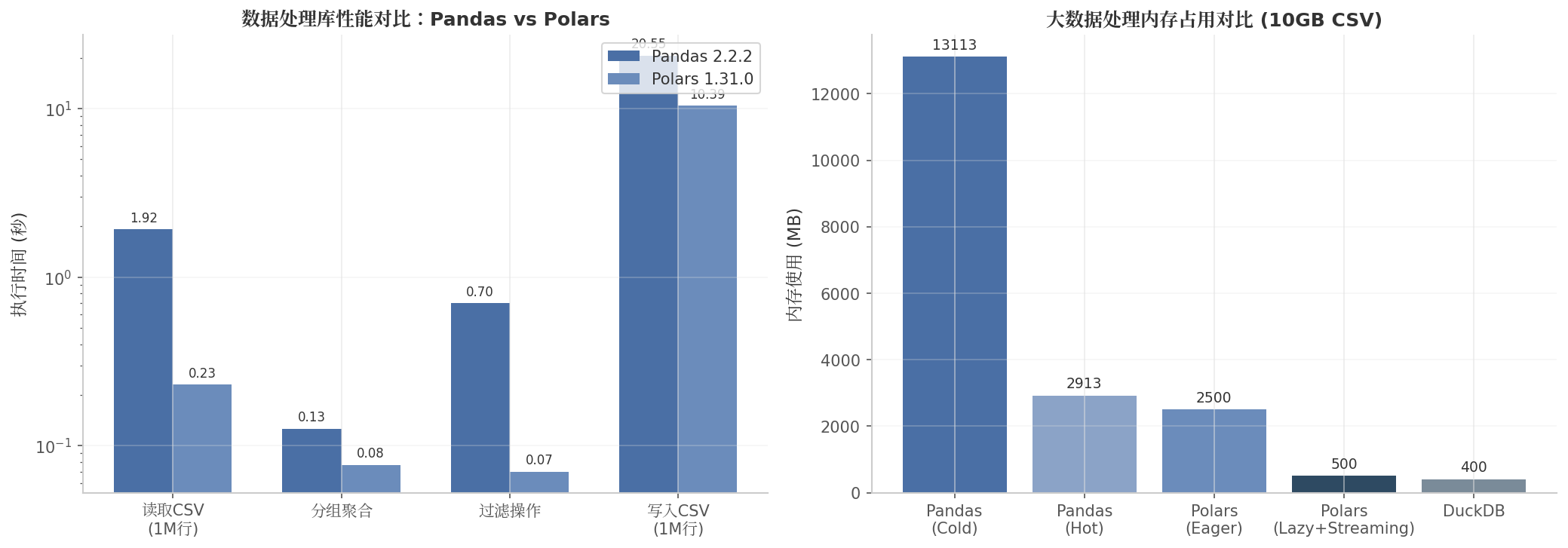
图2-1 数据处理库性能与内存占用对比。左图显示Pandas与Polars在典型操作上的执行时间差异,右图展示处理10GB CSV文件时的内存占用情况。数据来源:独立基准测试。
工具选择建议
| 场景 | 推荐工具 | 理由 |
|---|---|---|
| 数据探索(<1GB) | Pandas | 生态成熟、文档丰富 |
| 大数据处理(>10GB) | Polars/DuckDB | 内存效率高、并行处理 |
| ETL流水线 | Polars | 延迟计算、查询优化 |
| SQL优先团队 | DuckDB | SQL语法、与Pandas互操作 |
| 生产环境 | 混合使用 | 各取所长 |
图2-2 常用数据可视化类型示例,包括折线图(趋势分析)、散点图(相关性)、柱状图(分类比较)和热力图(相关性矩阵)。
本章系统介绍了Python数据处理的核心技术栈。从Python基础语法到NumPy数值计算,再到Pandas数据处理和数据可视化,这些技能构成了AI开发的编程基础。掌握这些工具后,读者可以高效地进行数据预处理、特征工程和结果分析,为后续章节的数学建模和机器学习实践做好准备。