每周 6-10 小时
本周目标
掌握 RAG(Retrieval-Augmented Generation)的完整技术栈。RAG 让 LLM 能够基于外部知识回答问题, 有效缓解幻觉问题。从文档预处理到检索策略再到答案生成,理解每个环节的技术选择和权衡。
学习内容
11.2 文档处理与分块
文档处理是RAG系统的第一道关卡,其质量直接影响后续检索和生成的效果。本节将详细介绍文档加载、分块策略、元数据管理等关键技术。
11.2.1 文档加载与解析:PDF、Word、HTML
RAG系统需要处理多种格式的文档,不同格式的解析方法各有特点。
PDF文档解析是最常见的需求。PDF格式设计用于保持排版一致性,而非结构化文本提取,因此解析存在一定挑战。常用的Python库包括:
- PyPDF2:纯Python实现,轻量级,适合简单文本提取
- pdfplumber:基于pdfminer,能更好地保留表格结构
- pymupdf(fitz):速度快,支持图像提取,适合复杂PDF
- Unstructured:企业级方案,支持多种文档格式
对于扫描版PDF(图像格式),需要先进行OCR识别。Tesseract是开源OCR引擎的代表,而商业方案如Azure Document Intelligence、Google Document AI在复杂版式识别上表现更好。
Word文档(.docx)解析相对简单,python-docx库可以直接提取段落、表格、样式信息。需要注意的是,Word文档中的复杂格式(如嵌套表格、文本框)可能需要特殊处理。
HTML/网页解析需要考虑网页的动态性和多样性。BeautifulSoup配合requests可以处理静态页面,而Selenium或Playwright则用于渲染JavaScript动态内容。对于大规模网页抓取,还需要考虑反爬虫策略和抓取频率控制。
以下是一个使用LangChain加载多种文档格式的示例代码:
from langchain.document_loaders import (
PyPDFLoader,
Docx2txtLoader,
UnstructuredHTMLLoader,
TextLoader
)
from langchain.schema import Document
from typing import List
import os
def load_documents(directory: str) -> List[Document]:
"""加载目录下的所有支持格式的文档"""
documents = []
for filename in os.listdir(directory):
filepath = os.path.join(directory, filename)
if filename.endswith('.pdf'):
loader = PyPDFLoader(filepath)
elif filename.endswith('.docx'):
loader = Docx2txtLoader(filepath)
elif filename.endswith('.html') or filename.endswith('.htm'):
loader = UnstructuredHTMLLoader(filepath)
elif filename.endswith('.txt') or filename.endswith('.md'):
loader = TextLoader(filepath, encoding='utf-8')
else:
print(f"跳过不支持的文件格式: {filename}")
continue
docs = loader.load()
# 添加文件名作为元数据
for doc in docs:
doc.metadata['source'] = filename
documents.extend(docs)
return documents
# 使用示例
docs = load_documents("/data/documents")
print(f"共加载 {len(docs)} 个文档片段")
11.2.2 分块策略与方法:固定长度、语义切分、递归切分
文本分块(Text Chunking)是RAG系统的关键环节。分块策略的选择会直接影响检索精度和生成质量。
**固定长度分块(Fixed-size Chunking)**是最简单的方法,按照固定的token数或字符数切分文本,可设置重叠区域保持上下文连贯。
from langchain.text_splitter import CharacterTextSplitter
# 固定长度分块示例
text_splitter = CharacterTextSplitter(
separator="\n", # 分隔符
chunk_size=500, # 每块大小
chunk_overlap=50, # 重叠大小
length_function=len,
)
chunks = text_splitter.split_documents(docs)
固定长度分块的优点是实现简单、速度快,缺点是可能切断语义完整的句子或段落,导致检索时丢失上下文。
**递归字符切分(Recursive Character Text Splitter)**是LangChain推荐的分块策略。它尝试使用一系列分隔符(段落→句子→单词)递归地切分文本,优先保持语义单元的完整性。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 递归字符切分
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", " ", ""],
chunk_size=500,
chunk_overlap=50,
length_function=len,
)
chunks = text_splitter.split_documents(docs)
递归切分能更好地保留段落和句子边界,是大多数场景下的推荐选择。
**语义切分(Semantic Chunking)**基于文本的语义相似度进行切分。它使用嵌入模型计算相邻句子的相似度,在相似度低于阈值的位置进行切分。这种方法能产生语义更连贯的文本块。
from langchain.text_splitter import SemanticChunker
from langchain.embeddings import OpenAIEmbeddings
# 语义切分
text_splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=85
)
chunks = text_splitter.split_documents(docs)
语义切分的优点是生成的文本块语义一致性高,缺点是计算开销较大,需要为每个句子生成嵌入向量。
基于结构的分块针对特定文档类型设计。例如,Markdown文档可以按标题层级切分,HTML可以按标签切分,代码文件可以按函数或类切分。
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Markdown按标题切分
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
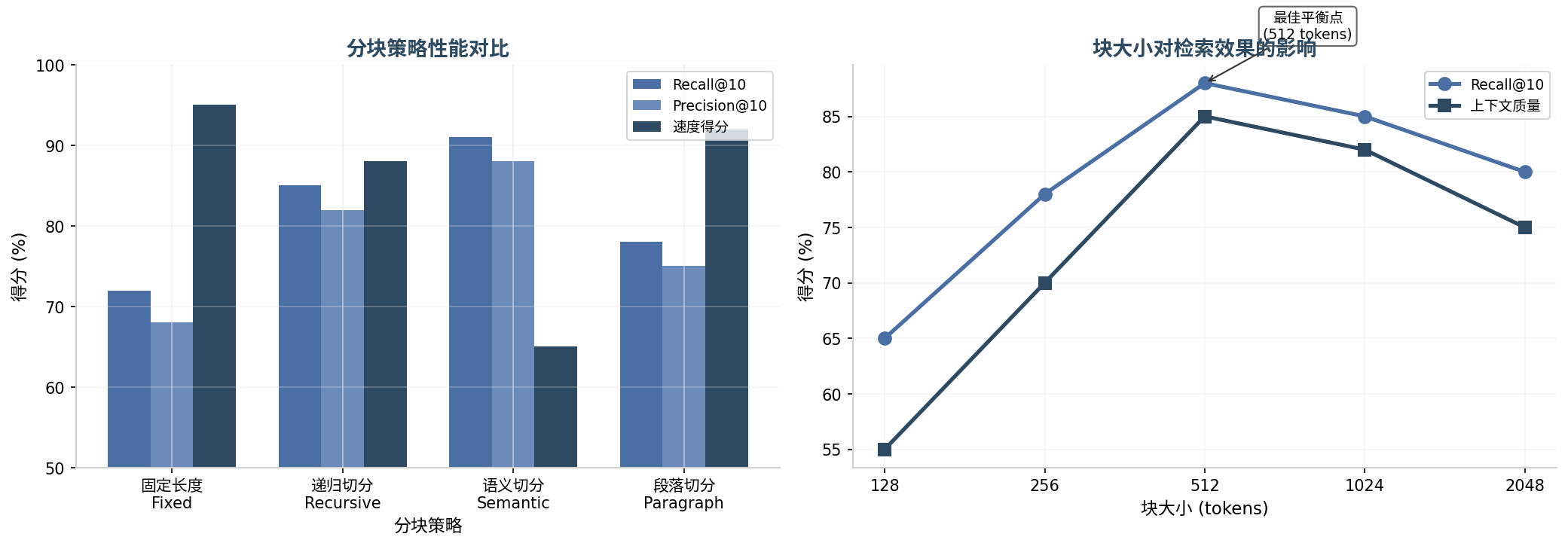
上图展示了不同分块策略的性能对比。从实验结果可以看出,语义切分在召回率和精确率上表现最佳,但速度较慢;递归切分在各项指标上取得了较好的平衡,是生产环境的推荐选择。
分块大小选择是另一个关键参数。块太小会丢失上下文信息,块太大则会稀释关键信息。根据实践经验,对于中文文本,256-512个token是较好的选择范围。具体选择需要结合嵌入模型的上下文窗口和实际应用场景进行测试。
| 分块策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定长度 | 实现简单、速度快 | 可能切断语义单元 | 快速原型、简单文档 |
| 递归切分 | 保留结构边界、效果均衡 | 对复杂格式支持有限 | 通用场景、推荐首选 |
| 语义切分 | 语义一致性高 | 计算开销大 | 高质量要求场景 |
| 结构切分 | 保留文档结构 | 需要格式预处理 | Markdown、HTML、代码 |
11.2.3 元数据与上下文保留:标题、页码、来源
在文档处理过程中,保留元数据对于提升RAG系统的效果至关重要。元数据不仅可以帮助用户追溯信息来源,还可以在检索时进行过滤和排序。
基础元数据包括:
- 来源(source):文档文件名或URL
- 页码(page):PDF或Word文档的页码
- 标题(title):文档标题或章节标题
- 创建时间(created_at):文档创建或更新时间
结构化元数据根据文档类型有所不同:
- 技术文档:产品版本、模块名称、文档类型
- 法律文档:法律领域、效力级别、发布机构
- 新闻文档:发布时间、作者、分类标签
以下是在分块时保留元数据的示例:
from langchain.schema import Document
from typing import List
def split_documents_with_metadata(
documents: List[Document],
text_splitter
) -> List[Document]:
"""分块并保留元数据"""
chunks = []
for doc in documents:
# 获取原始元数据
base_metadata = doc.metadata.copy()
# 分块
doc_chunks = text_splitter.split_documents([doc])
# 为每个块添加序号和上下文
for i, chunk in enumerate(doc_chunks):
chunk.metadata.update(base_metadata)
chunk.metadata['chunk_index'] = i
chunk.metadata['total_chunks'] = len(doc_chunks)
# 添加上下文信息
if i > 0:
chunk.metadata['prev_context'] = doc_chunks[i-1].page_content[-100:]
if i < len(doc_chunks) - 1:
chunk.metadata['next_context'] = doc_chunks[i+1].page_content[:100]
chunks.extend(doc_chunks)
return chunks
上下文增强是一种进阶技术,通过将相邻块的内容作为上下文附加到当前块,帮助模型理解更完整的语义。例如,可以将前一个块的末尾100个字符和后一个块的开头100个字符作为上下文。
11.2.4 多模态文档处理:图像、表格、图表
实际业务中的文档往往包含图像、表格、图表等多模态元素,这些元素的处理对RAG系统提出了更高要求。
表格处理是常见挑战。简单的文本提取会将表格内容打乱,丢失行列关系。处理策略包括:
- 结构化提取:使用专门的表格提取工具(如Camelot、Tabula)将表格转换为结构化数据
- HTML表示:将表格转换为HTML格式保留结构
- 描述生成:使用多模态模型生成表格的文字描述
import camelot
def extract_tables_from_pdf(pdf_path: str):
"""从PDF中提取表格"""
tables = camelot.read_pdf(pdf_path, pages='all')
table_docs = []
for i, table in enumerate(tables):
# 转换为DataFrame
df = table.df
# 生成文本描述
table_text = f"表格 {i+1}:\n"
table_text += df.to_string(index=False)
doc = Document(
page_content=table_text,
metadata={
'source': pdf_path,
'page': table.page,
'type': 'table',
'table_index': i
}
)
table_docs.append(doc)
return table_docs
图像处理可以采用以下策略:
- OCR识别:对包含文字的图像进行OCR,提取文本内容
- 图像描述:使用视觉语言模型(如GPT-4V、CLIP)生成图像描述
- 多模态嵌入:使用多模态嵌入模型将图像和文本映射到同一向量空间
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
# 加载CLIP模型
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def get_image_description(image_path: str) -> str:
"""使用CLIP获取图像描述(简化示例)"""
image = Image.open(image_path)
# 候选描述
candidate_labels = ["图表", "流程图", "截图", "照片", "示意图"]
inputs = processor(
text=candidate_labels,
images=image,
return_tensors="pt",
padding=True
)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
# 返回最可能的描述
best_idx = probs.argmax().item()
return f"这是一个{candidate_labels[best_idx]}"
11.3 向量检索系统
向量检索是RAG系统的核心技术,负责在海量文档中快速找到与用户查询最相关的内容。本节将介绍嵌入模型选择、向量数据库对比、索引优化等关键技术。
11.3.1 嵌入模型选择:Sentence-Transformers、OpenAI Embedding
嵌入模型(Embedding Model)将文本转换为高维向量,使得语义相似的文本在向量空间中距离更近。选择合适的嵌入模型对RAG系统的性能至关重要。
Sentence-Transformers是开源嵌入模型的事实标准,提供了多种预训练模型:
| 模型名称 | 维度 | 特点 | 适用场景 |
|---|---|---|---|
| all-MiniLM-L6-v2 | 384 | 轻量快速 | 原型开发、资源受限环境 |
| all-mpnet-base-v2 | 768 | 质量均衡 | 通用检索任务 |
| all-distilroberta-v1 | 768 | 蒸馏模型 | 速度与质量的平衡 |
| paraphrase-multilingual-MiniLM-L12-v2 | 384 | 多语言支持 | 非英语文本 |
from sentence_transformers import SentenceTransformer
# 加载Sentence-Transformer模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 生成嵌入
texts = ["这是一个测试句子", "这是另一个句子"]
embeddings = model.encode(texts)
print(f"嵌入维度: {embeddings.shape[1]}")
print(f"嵌入示例: {embeddings[0][:5]}")
OpenAI Embedding提供了商业级的嵌入服务,包括text-embedding-ada-002和text-embedding-3系列:
| 模型名称 | 维度 | 特点 | 价格(每1K tokens) |
|---|---|---|---|
| text-embedding-ada-002 | 1536 | 通用性强 | $0.0001 |
| text-embedding-3-small | 1536 | 性价比高 | $0.00002 |
| text-embedding-3-large | 3072 | 最高质量 | $0.00013 |
from openai import OpenAI
client = OpenAI()
def get_openai_embedding(texts: list) -> list:
"""使用OpenAI API获取嵌入"""
response = client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
return [item.embedding for item in response.data]
模型选择建议:
- 快速原型:使用all-MiniLM-L6-v2或text-embedding-3-small
- 生产环境:根据质量要求选择all-mpnet-base-v2或text-embedding-3-large
- 多语言场景:使用paraphrase-multilingual系列或E5多语言模型
- 领域特定:考虑在领域数据上微调开源模型
MTEB基准(Massive Text Embedding Benchmark)是评估嵌入模型的重要参考。它涵盖了检索、聚类、分类等多种任务,可以帮助开发者选择适合特定场景的模型。
11.3.2 向量数据库对比:FAISS、Chroma、Pinecone、Milvus
向量数据库负责存储和检索高维向量,是RAG系统的核心基础设施。选择合适的向量数据库需要考虑性能、规模、运维成本等多个因素。
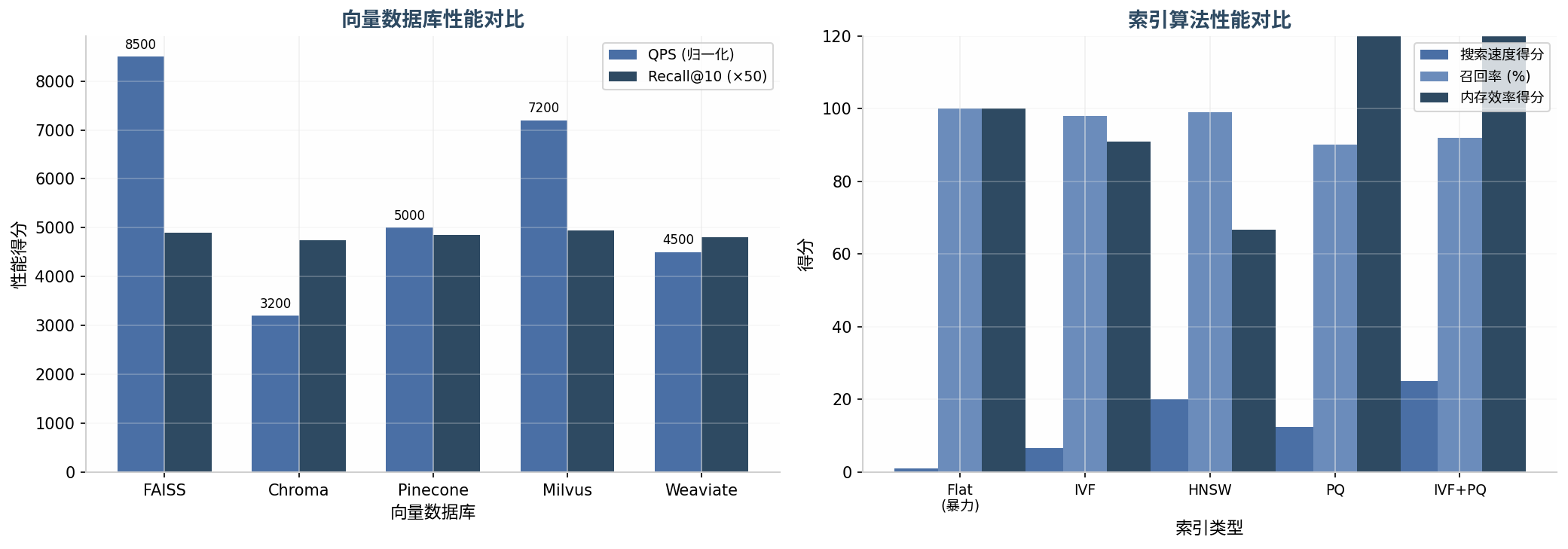
| 数据库 | 类型 | 特点 | 适用规模 | 索引类型 |
|---|---|---|---|---|
| FAISS | 开源库 | 纯内存、速度快 | <1000万 | HNSW、IVF、PQ |
| Chroma | 开源数据库 | 轻量易用 | <500万 | HNSW |
| Pinecone | 托管服务 | 免运维、弹性扩展 | 任意规模 | 专有算法 |
| Milvus | 开源/托管 | 分布式、功能丰富 | 十亿级 | 多种索引 |
| Weaviate | 开源/托管 | 混合搜索强 | <5000万 | HNSW |
| Qdrant | 开源/托管 | 过滤功能强 | <5000万 | HNSW |
FAISS(Facebook AI Similarity Search)是Meta开源的向量检索库,提供了多种高效的ANN算法实现。它采用纯内存计算,在单机环境下性能优异。
import faiss
import numpy as np
# 创建FAISS索引
dimension = 384 # 嵌入维度
index = faiss.IndexFlatIP(dimension) # 内积相似度(余弦相似度需归一化)
# 添加向量
vectors = np.random.random((10000, dimension)).astype('float32')
vectors = vectors / np.linalg.norm(vectors, axis=1, keepdims=True) # 归一化
index.add(vectors)
# 搜索
query = np.random.random((1, dimension)).astype('float32')
query = query / np.linalg.norm(query)
distances, indices = index.search(query, k=10)
print(f"最相似的10个向量的索引: {indices[0]}")
print(f"相似度分数: {distances[0]}")
Chroma是专为AI应用设计的轻量级向量数据库,与LangChain集成良好,适合快速原型开发。
import chromadb
# 创建Chroma客户端
client = chromadb.Client()
# 创建集合
collection = client.create_collection(name="documents")
# 添加文档
collection.add(
documents=["这是文档1", "这是文档2", "这是文档3"],
metadatas=[{"source": "doc1"}, {"source": "doc2"}, {"source": "doc3"}],
ids=["id1", "id2", "id3"]
)
# 查询
results = collection.query(
query_texts=["查询内容"],
n_results=2
)
Pinecone是全托管的向量数据库服务,无需关心基础设施运维,适合不想投入运维资源的企业。
from pinecone import Pinecone, ServerlessSpec
# 初始化Pinecone
pc = Pinecone(api_key="your-api-key")
# 创建索引
index_name = "rag-index"
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=384,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
# 连接索引
index = pc.Index(index_name)
# 添加向量
index.upsert(vectors=[
("id1", [0.1] * 384, {"source": "doc1"}),
("id2", [0.2] * 384, {"source": "doc2"}),
])
# 查询
results = index.query(
vector=[0.1] * 384,
top_k=2,
include_metadata=True
)
Milvus是功能最丰富的开源向量数据库,支持分布式部署、混合检索、多租户等企业级特性。
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection
# 连接Milvus
connections.connect("default", host="localhost", port="19530")
# 定义集合schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
]
schema = CollectionSchema(fields, "Document collection")
# 创建集合
collection = Collection("documents", schema)
# 创建索引
index_params = {
"metric_type": "COSINE",
"index_type": "HNSW",
"params": {"M": 16, "efConstruction": 500}
}
collection.create_index("embedding", index_params)
11.3.3 索引构建与优化:HNSW、IVF、乘积量化
近似最近邻(ANN)算法是向量数据库的核心,在检索速度和召回率之间取得平衡。常见的索引算法包括:
**暴力搜索(Flat/Exhaustive Search)**计算查询向量与所有文档向量的相似度,返回最相似的K个结果。优点是召回率100%,缺点是时间复杂度O(N),仅适用于小规模数据。
**HNSW(Hierarchical Navigable Small World)**是目前最流行的ANN算法之一。它构建多层图结构,通过贪心搜索快速定位最近邻。
HNSW的核心参数:
- M:每个节点的最大连接数,越大图越稠密,召回率越高,内存消耗越大
- efConstruction:构建时的搜索深度,越大构建质量越高
- efSearch:查询时的搜索深度,越大召回率越高,查询越慢
import faiss
# 创建HNSW索引
d = 384 # 维度
M = 16 # 连接数
efConstruction = 200
index = faiss.IndexHNSWFlat(d, M)
index.hnsw.efConstruction = efConstruction
index.hnsw.efSearch = 128
# 添加数据
xb = np.random.random((100000, d)).astype('float32')
index.add(xb)
# 搜索
xq = np.random.random((1, d)).astype('float32')
D, I = index.search(xq, k=10)
**IVF(Inverted File Index)**先将向量空间划分为多个聚类中心,查询时只需搜索最近的几个聚类。
# 创建IVF索引
nlist = 100 # 聚类中心数
quantizer = faiss.IndexFlatIP(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist)
# 训练(需要训练数据)
index.train(xb)
index.add(xb)
# 设置搜索时的聚类数
index.nprobe = 10 # 搜索10个最近的聚类
**乘积量化(Product Quantization, PQ)**将高维向量分割为多个子向量,对每个子向量单独量化,大幅减少存储空间。
# 创建PQ索引
m = 16 # 子向量数
nbits = 8 # 每个子向量的比特数
index = faiss.IndexPQ(d, m, nbits)
index.train(xb)
index.add(xb)
IVF+PQ组合结合了两者的优势,先通过IVF缩小搜索范围,再在候选集上使用PQ加速相似度计算,是处理亿级向量的常用方案。
# 创建IVFPQ索引
nlist = 100
m = 16
nbits = 8
quantizer = faiss.IndexFlatIP(d)
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, nbits)
index.train(xb)
index.add(xb)
上图展示了不同索引算法在搜索速度、召回率和内存效率方面的对比。HNSW在速度和召回率上表现优异,是大多数场景的首选;IVF+PQ则在超大规模数据集上具有内存优势。
11.3.4 混合检索策略:稀疏检索+密集检索
纯向量检索(密集检索)虽然能捕捉语义相似性,但在精确匹配关键词方面存在局限。混合检索结合稀疏检索(如BM25)和密集检索的优势,能显著提升检索效果。
BM25是经典的关键词检索算法,基于词频和逆文档频率计算相关性。它对精确匹配效果好,但无法理解语义相似性。
混合检索的实现方式:
- 并行检索:同时使用向量检索和关键词检索,合并结果
- 加权融合:对两种检索的分数进行加权求和
- 级联检索:先用一种方法粗筛,再用另一种方法精排
from rank_bm25 import BM25Okapi
import numpy as np
from sklearn.preprocessing import MinMaxScaler
class HybridRetriever:
"""混合检索器:结合BM25和向量检索"""
def __init__(self, documents, embeddings, k1=1.5, b=0.75):
self.documents = documents
self.embeddings = embeddings
# 初始化BM25
tokenized_docs = [doc.lower().split() for doc in documents]
self.bm25 = BM25Okapi(tokenized_docs, k1=k1, b=b)
# 向量索引
self.dimension = embeddings.shape[1]
self.vector_index = faiss.IndexFlatIP(self.dimension)
self.vector_index.add(embeddings)
def retrieve(self, query, query_embedding, top_k=10, alpha=0.5):
"""
混合检索
Args:
query: 查询文本
query_embedding: 查询向量
top_k: 返回结果数
alpha: 向量检索权重(0-1)
"""
# BM25检索
tokenized_query = query.lower().split()
bm25_scores = self.bm25.get_scores(tokenized_query)
# 向量检索
query_embedding = query_embedding.reshape(1, -1)
vector_scores, vector_indices = self.vector_index.search(
query_embedding, len(self.documents)
)
# 归一化分数
scaler = MinMaxScaler()
bm25_norm = scaler.fit_transform(bm25_scores.reshape(-1, 1)).flatten()
# 构建向量分数数组
vector_score_dict = {idx: score for idx, score in
zip(vector_indices[0], vector_scores[0])}
vector_scores_array = np.array([vector_score_dict.get(i, 0)
for i in range(len(self.documents))])
vector_norm = scaler.fit_transform(vector_scores_array.reshape(-1, 1)).flatten()
# 融合分数
hybrid_scores = alpha * vector_norm + (1 - alpha) * bm25_norm
# 获取top_k结果
top_indices = np.argsort(hybrid_scores)[::-1][:top_k]
results = []
for idx in top_indices:
results.append({
'document': self.documents[idx],
'score': hybrid_scores[idx],
'vector_score': vector_norm[idx],
'bm25_score': bm25_norm[idx]
})
return results
# 使用示例
documents = [
"Python是一种流行的编程语言",
"JavaScript用于网页开发",
"机器学习是人工智能的分支",
"Python在数据科学中广泛应用"
]
# 生成嵌入(实际使用时应使用真实嵌入模型)
embeddings = np.random.random((len(documents), 384)).astype('float32')
embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
retriever = HybridRetriever(documents, embeddings)
query = "Python编程"
query_embedding = np.random.random(384).astype('float32')
query_embedding = query_embedding / np.linalg.norm(query_embedding)
results = retriever.retrieve(query, query_embedding, top_k=3, alpha=0.7)
for r in results:
print(f"文档: {r['document']}")
print(f"混合分数: {r['score']:.3f} (向量: {r['vector_score']:.3f}, BM25: {r['bm25_score']:.3f})")
print()
11.4 检索增强生成
检索到相关文档后,如何有效利用这些信息生成高质量回答是RAG系统的另一个关键环节。本节将介绍检索结果融合、上下文管理、重排序等技术。
11.4.1 检索结果融合:重排序、分数融合
初步检索往往返回多个候选文档,需要进一步处理才能输入大语言模型。常见的融合策略包括:
简单拼接:将检索到的文档按顺序拼接,是最直接的方法。
def simple_context_assembly(documents, max_tokens=3000):
"""简单拼接文档作为上下文"""
context = ""
for i, doc in enumerate(documents):
context += f"\n[文档 {i+1}]\n{doc}\n"
# 简单token估算(实际应使用tokenizer)
if len(context) > max_tokens * 4: # 粗略估算:1 token ≈ 4字符
break
return context
分数加权:根据检索分数对文档进行加权,高分文档获得更多关注。
def weighted_context_assembly(documents_with_scores, max_tokens=3000):
"""根据分数加权拼接文档"""
# 按分数排序
sorted_docs = sorted(documents_with_scores,
key=lambda x: x['score'],
reverse=True)
context = ""
for doc_info in sorted_docs:
doc = doc_info['document']
score = doc_info['score']
context += f"\n[相关度: {score:.2f}]\n{doc}\n"
if len(context) > max_tokens * 4:
break
return context
**MMR(Maximal Marginal Relevance)**在相关性和多样性之间取得平衡,避免返回内容高度相似的文档。
def mmr_select(documents, embeddings, query_embedding, lambda_param=0.5, top_k=5):
"""
MMR算法选择多样化文档
Args:
documents: 文档列表
embeddings: 文档嵌入
query_embedding: 查询嵌入
lambda_param: 相关性vs多样性的权衡参数
top_k: 选择文档数
"""
selected = []
remaining = list(range(len(documents)))
# 计算与查询的相似度
query_sim = np.dot(embeddings, query_embedding)
while len(selected) < top_k and remaining:
if not selected:
# 第一个选择最相关的
best_idx = remaining[np.argmax(query_sim[remaining])]
else:
# MMR评分
mmr_scores = []
for idx in remaining:
# 相关性部分
relevance = query_sim[idx]
# 多样性部分(与已选文档的最大相似度)
diversity = max([np.dot(embeddings[idx], embeddings[s])
for s in selected])
# MMR分数
mmr_score = lambda_param * relevance - (1 - lambda_param) * diversity
mmr_scores.append(mmr_score)
best_idx = remaining[np.argmax(mmr_scores)]
selected.append(best_idx)
remaining.remove(best_idx)
return [documents[i] for i in selected]
11.4.2 上下文窗口管理:Token限制、上下文压缩
大语言模型有上下文长度限制,需要有效管理检索到的文档内容。
Token预算分配:根据任务复杂度合理分配token预算。
def allocate_token_budget(model_max_tokens=4096,
system_prompt_tokens=200,
user_query_tokens=100,
response_reserve=500):
"""计算可用于上下文的token数"""
available = model_max_tokens - system_prompt_tokens - user_query_tokens - response_reserve
return max(available, 500) # 至少保留500 tokens
上下文压缩技术:
- 摘要压缩:使用轻量级模型对长文档进行摘要
- 关键句提取:提取文档中最相关的句子
- 信息抽取:提取实体、关系等结构化信息
from transformers import pipeline
# 加载摘要模型(轻量级)
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
def compress_document(document, max_length=100):
"""对文档进行摘要压缩"""
if len(document) < 200:
return document
summary = summarizer(document, max_length=max_length,
min_length=30, do_sample=False)
return summary[0]['summary_text']
Map-Reduce策略:对于超长文档,可以采用Map-Reduce方式,先分别处理每个文档片段,再合并结果。
async def map_reduce_rag(documents, query, llm_client):
"""Map-Reduce方式处理长文档"""
# Map阶段:每个文档单独处理
partial_answers = []
for doc in documents:
prompt = f"""基于以下文档片段回答问题。如果文档不包含相关信息,回答"无相关信息"。
文档:{doc}
问题:{query}
回答:"""
response = await llm_client.complete(prompt)
if "无相关信息" not in response:
partial_answers.append(response)
# Reduce阶段:合并部分回答
if not partial_answers:
return "未找到相关信息"
combine_prompt = f"""基于以下部分回答,综合给出最终答案。
部分回答:
{chr(10).join(f"{i+1}. {ans}" for i, ans in enumerate(partial_answers))}
问题:{query}
综合回答:"""
final_answer = await llm_client.complete(combine_prompt)
return final_answer
11.4.3 重排序与过滤:交叉编码器、相关性过滤
初步检索使用双编码器(Bi-Encoder)计算查询和文档的相似度,速度快但精度有限。重排序阶段使用交叉编码器(Cross-Encoder)进行更精确的排序。
交叉编码器将查询和文档拼接后输入模型,通过注意力机制捕捉细粒度的交互信息,排序精度更高但速度较慢。
from sentence_transformers import CrossEncoder
# 加载交叉编码器模型
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def rerank_documents(query, documents, top_k=5):
"""使用交叉编码器重排序"""
# 构建查询-文档对
pairs = [[query, doc] for doc in documents]
# 计算相关性分数
scores = cross_encoder.predict(pairs)
# 按分数排序
scored_docs = list(zip(documents, scores))
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:top_k]
# 使用示例
docs = ["Python是一种编程语言", "Java是另一种语言", "Python用于数据科学"]
query = "Python编程"
reranked = rerank_documents(query, docs, top_k=2)
for doc, score in reranked:
print(f"分数: {score:.3f}, 文档: {doc}")
相关性过滤:设置阈值过滤低质量检索结果,避免无关信息干扰生成。
def filter_by_relevance(documents_with_scores, threshold=0.5):
"""根据相关性分数过滤"""
filtered = [(doc, score) for doc, score in documents_with_scores
if score >= threshold]
if not filtered:
# 如果全部过滤,至少保留最高分的一个
best = max(documents_with_scores, key=lambda x: x[1])
filtered = [best]
return filtered
11.4.4 生成后处理:引用生成、幻觉检测
生成回答后,还需要进行后处理以确保质量和可靠性。
引用生成:为回答中的事实添加来源引用,提高可信度。
def add_citations(answer, source_documents):
"""为回答添加引用标注"""
cited_answer = answer + "\n\n参考来源:\n"
for i, doc in enumerate(source_documents, 1):
source = doc.get('metadata', {}).get('source', f'文档{i}')
cited_answer += f"[{i}] {source}\n"
return cited_answer
幻觉检测:检测模型生成的内容与检索文档不符的部分。
def detect_hallucination(answer, source_documents, similarity_threshold=0.7):
"""
简单幻觉检测
检查回答中的句子是否与源文档有足够相似度
"""
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
# 分割回答为句子
sentences = answer.split('。')
# 编码源文档
source_text = ' '.join([doc['document'] for doc in source_documents])
source_embedding = model.encode(source_text, convert_to_tensor=True)
hallucinated = []
for sent in sentences:
if len(sent.strip()) < 10:
continue
sent_embedding = model.encode(sent, convert_to_tensor=True)
similarity = util.pytorch_cos_sim(sent_embedding, source_embedding).item()
if similarity < similarity_threshold:
hallucinated.append({
'sentence': sent,
'similarity': similarity
})
return hallucinated
11.5 RAG系统构建
本节将整合前面介绍的技术,使用LangChain和LlamaIndex构建完整的RAG系统,并介绍评估与优化方法。
11.5.1 LangChain核心组件:Document Loader、Retriever、Chain
LangChain是目前最流行的RAG开发框架,提供了丰富的组件和抽象。
核心组件介绍:
- Document Loader:加载各种格式的文档
- Text Splitter:文本分块
- Embedding Model:文本嵌入
- Vector Store:向量存储
- Retriever:检索器
- Chain:处理链
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. 加载文档
loader = DirectoryLoader(
'/data/documents',
glob='**/*.pdf',
loader_cls=PyPDFLoader
)
documents = loader.load()
print(f"加载了 {len(documents)} 个文档片段")
# 2. 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", " ", ""]
)
chunks = text_splitter.split_documents(documents)
print(f"分块后得到 {len(chunks)} 个文本块")
# 3. 创建嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name='sentence-transformers/all-MiniLM-L6-v2'
)
# 4. 构建向量数据库
vectorstore = FAISS.from_documents(chunks, embeddings)
print("向量数据库构建完成")
# 5. 创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
# 6. 构建RAG链
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
chain_type="stuff", # 简单拼接方式
retriever=retriever,
return_source_documents=True,
verbose=True
)
# 7. 执行查询
query = "什么是RAG技术?"
result = qa_chain({"query": query})
print(f"\n问题: {query}")
print(f"\n回答: {result['result']}")
print(f"\n参考来源:")
for i, doc in enumerate(result['source_documents'], 1):
print(f"[{i}] {doc.metadata.get('source', '未知')} - {doc.page_content[:100]}...")
高级Chain配置:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 自定义提示模板
custom_prompt = PromptTemplate(
template="""你是一个专业的AI助手。请基于以下参考信息回答问题。
如果参考信息不足以回答问题,请明确说明。
参考信息:
{context}
问题:{question}
请按照以下格式回答:
1. 直接回答
2. 详细解释(如有必要)
3. 相关引用
回答:""",
input_variables=["context", "question"]
)
# 使用自定义提示构建Chain
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={"prompt": custom_prompt},
return_source_documents=True
)
11.5.2 LlamaIndex架构设计:索引、查询引擎
LlamaIndex是另一个强大的RAG框架,提供了更灵活的索引和查询抽象。
核心概念:
- Document:文档对象
- Node:文档的细粒度单元
- Index:索引结构
- Query Engine:查询引擎
- Response Synthesizer:回答合成器
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext,
get_response_synthesizer
)
from llama_index.llms import OpenAI
from llama_index.embeddings import HuggingFaceEmbedding
# 1. 加载文档
documents = SimpleDirectoryReader('/data/documents').load_data()
# 2. 配置服务上下文
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo"),
embed_model=HuggingFaceEmbedding(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
)
# 3. 构建索引
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
# 4. 创建查询引擎
query_engine = index.as_query_engine(
response_mode="compact", # 响应模式
similarity_top_k=5
)
# 5. 查询
response = query_engine.query("什么是RAG技术?")
print(response)
# 查看参考节点
for node in response.source_nodes:
print(f"来源: {node.node.metadata}")
print(f"内容: {node.node.text[:100]}...")
print(f"分数: {node.score}")
高级索引类型:
from llama_index import ListIndex, TreeIndex, KeywordTableIndex
# 列表索引 - 简单顺序存储
list_index = ListIndex.from_documents(documents)
# 树形索引 - 层次化组织
tree_index = TreeIndex.from_documents(documents)
# 关键词表索引 - 基于关键词检索
keyword_index = KeywordTableIndex.from_documents(documents)
# 组合索引
from llama_index import ComposableGraph
graph = ComposableGraph.from_indices(
VectorStoreIndex,
[index1, index2, index3],
index_summaries=["摘要1", "摘要2", "摘要3"]
)
11.5.3 端到端系统实现:完整Pipeline
下面是一个生产级的RAG系统完整实现:
"""
生产级RAG系统实现
"""
import os
from typing import List, Dict, Optional
from dataclasses import dataclass
import numpy as np
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from sentence_transformers import CrossEncoder
@dataclass
class RAGConfig:
"""RAG系统配置"""
# 文档处理
chunk_size: int = 512
chunk_overlap: int = 50
# 嵌入模型
embedding_model: str = "sentence-transformers/all-MiniLM-L6-v2"
# 检索
top_k: int = 10
rerank_top_k: int = 5
# 生成
llm_model: str = "gpt-3.5-turbo"
temperature: float = 0.0
max_tokens: int = 1000
class RAGSystem:
"""完整的RAG系统"""
def __init__(self, config: RAGConfig):
self.config = config
self.embeddings = None
self.vectorstore = None
self.retriever = None
self.qa_chain = None
self.cross_encoder = None
def initialize(self, documents_path: str):
"""初始化RAG系统"""
print("正在初始化RAG系统...")
# 1. 加载嵌入模型
print("加载嵌入模型...")
self.embeddings = HuggingFaceEmbeddings(
model_name=self.config.embedding_model
)
# 2. 加载文档
print("加载文档...")
documents = self._load_documents(documents_path)
# 3. 分块
print("文本分块...")
chunks = self._split_documents(documents)
# 4. 构建向量数据库
print("构建向量数据库...")
self.vectorstore = FAISS.from_documents(chunks, self.embeddings)
# 5. 创建检索器
base_retriever = self.vectorstore.as_retriever(
search_kwargs={"k": self.config.top_k}
)
# 6. 添加上下文压缩
llm = ChatOpenAI(
model=self.config.llm_model,
temperature=self.config.temperature
)
compressor = LLMChainExtractor.from_llm(llm)
self.retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# 7. 加载重排序模型
print("加载重排序模型...")
self.cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# 8. 构建QA链
print("构建QA链...")
self.qa_chain = self._build_qa_chain()
print("RAG系统初始化完成!")
def _load_documents(self, path: str):
"""加载文档"""
loader = DirectoryLoader(
path,
glob='**/*.{pdf,txt,md,docx}',
show_progress=True
)
return loader.load()
def _split_documents(self, documents):
"""分块处理"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.config.chunk_size,
chunk_overlap=self.config.chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", " ", ""],
length_function=len
)
return text_splitter.split_documents(documents)
def _build_qa_chain(self):
"""构建QA链"""
prompt_template = """基于以下参考信息回答问题。如果参考信息不足,请明确说明。
参考信息:
{context}
问题:{question}
请给出准确、简洁的回答,并在回答后列出参考来源。
回答:"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
llm = ChatOpenAI(
model=self.config.llm_model,
temperature=self.config.temperature,
max_tokens=self.config.max_tokens
)
return RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt}
)
def rerank(self, query: str, documents: List) -> List:
"""重排序"""
if not documents or len(documents) <= self.config.rerank_top_k:
return documents
# 构建查询-文档对
pairs = [[query, doc.page_content] for doc in documents]
# 计算分数
scores = self.cross_encoder.predict(pairs)
# 排序
scored_docs = list(zip(documents, scores))
scored_docs.sort(key=lambda x: x[1], reverse=True)
return [doc for doc, _ in scored_docs[:self.config.rerank_top_k]]
def query(self, question: str) -> Dict:
"""执行查询"""
# 执行检索
docs = self.retriever.get_relevant_documents(question)
# 重排序
reranked_docs = self.rerank(question, docs)
# 临时替换retriever返回重排序结果
original_get_relevant = self.retriever.get_relevant_documents
self.retriever.get_relevant_documents = lambda _: reranked_docs
# 执行生成
result = self.qa_chain({"query": question})
# 恢复原始retriever
self.retriever.get_relevant_documents = original_get_relevant
return {
'question': question,
'answer': result['result'],
'sources': [
{
'content': doc.page_content[:200],
'metadata': doc.metadata
}
for doc in result['source_documents']
]
}
def save(self, path: str):
"""保存向量数据库"""
self.vectorstore.save_local(path)
print(f"向量数据库已保存到: {path}")
def load(self, path: str):
"""加载向量数据库"""
self.embeddings = HuggingFaceEmbeddings(
model_name=self.config.embedding_model
)
self.vectorstore = FAISS.load_local(path, self.embeddings)
self.retriever = self.vectorstore.as_retriever(
search_kwargs={"k": self.config.top_k}
)
self.qa_chain = self._build_qa_chain()
print(f"向量数据库已从 {path} 加载")
# 使用示例
if __name__ == "__main__":
# 配置
config = RAGConfig(
chunk_size=512,
top_k=10,
rerank_top_k=5
)
# 初始化系统
rag = RAGSystem(config)
rag.initialize("/data/knowledge_base")
# 保存索引
rag.save("/data/vector_index")
# 查询
while True:
question = input("\n请输入问题(输入'quit'退出):")
if question.lower() == 'quit':
break
result = rag.query(question)
print(f"\n回答:{result['answer']}")
print("\n参考来源:")
for i, source in enumerate(result['sources'], 1):
print(f"[{i}] {source['metadata'].get('source', '未知')}")
11.5.4 评估与优化方法:RAGAS、自定义指标
RAG系统的评估是持续优化的基础。RAGAS(Retrieval-Augmented Generation Assessment)是一个专门用于评估RAG系统的框架。
RAGAS评估指标:
- Faithfulness(忠实度):生成的回答是否忠实于检索到的文档
- Answer Relevance(回答相关性):回答是否与问题相关
- Context Precision(上下文精确度):检索到的文档中相关文档的比例
- Context Recall(上下文召回率):相关文档被检索到的比例
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall
)
from datasets import Dataset
# 准备评估数据
eval_data = {
'question': ['什么是RAG?', 'RAG有哪些优势?'],
'answer': ['RAG是检索增强生成技术...', 'RAG的优势包括...'],
'contexts': [['RAG技术介绍...'], ['RAG优势分析...']],
'ground_truth': ['检索增强生成技术', '知识更新、领域适应、可解释性']
}
dataset = Dataset.from_dict(eval_data)
# 执行评估
result = evaluate(
dataset=dataset,
metrics=[
faithfulness,
answer_relevancy,
context_precision,
context_recall
]
)
print(result)
自定义评估指标:
from typing import List
from sentence_transformers import SentenceTransformer, util
class RAGEvaluator:
"""RAG系统评估器"""
def __init__(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
def evaluate_retrieval(self,
query: str,
retrieved_docs: List[str],
relevant_docs: List[str]) -> Dict:
"""评估检索质量"""
# 计算Recall@K
retrieved_set = set(retrieved_docs)
relevant_set = set(relevant_docs)
recall = len(retrieved_set & relevant_set) / len(relevant_set)
# 计算Precision@K
precision = len(retrieved_set & relevant_set) / len(retrieved_set) if retrieved_set else 0
# 计算MRR
mrr = 0
for i, doc in enumerate(retrieved_docs):
if doc in relevant_docs:
mrr = 1 / (i + 1)
break
return {
'recall@k': recall,
'precision@k': precision,
'mrr': mrr,
'f1': 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0
}
def evaluate_answer(self,
question: str,
answer: str,
ground_truth: str) -> Dict:
"""评估回答质量"""
# 语义相似度
answer_emb = self.model.encode(answer, convert_to_tensor=True)
truth_emb = self.model.encode(ground_truth, convert_to_tensor=True)
similarity = util.pytorch_cos_sim(answer_emb, truth_emb).item()
return {
'semantic_similarity': similarity
}
def evaluate_end_to_end(self,
queries: List[str],
answers: List[str],
ground_truths: List[str],
retrieved_docs_list: List[List[str]],
relevant_docs_list: List[List[str]]) -> Dict:
"""端到端评估"""
retrieval_scores = []
answer_scores = []
for query, answer, truth, retrieved, relevant in zip(
queries, answers, ground_truths, retrieved_docs_list, relevant_docs_list
):
retrieval_scores.append(
self.evaluate_retrieval(query, retrieved, relevant)
)
answer_scores.append(
self.evaluate_answer(query, answer, truth)
)
# 汇总指标
avg_recall = sum(s['recall@k'] for s in retrieval_scores) / len(retrieval_scores)
avg_precision = sum(s['precision@k'] for s in retrieval_scores) / len(retrieval_scores)
avg_mrr = sum(s['mrr'] for s in retrieval_scores) / len(retrieval_scores)
avg_similarity = sum(s['semantic_similarity'] for s in answer_scores) / len(answer_scores)
return {
'retrieval': {
'avg_recall@k': avg_recall,
'avg_precision@k': avg_precision,
'avg_mrr': avg_mrr
},
'generation': {
'avg_semantic_similarity': avg_similarity
}
}
# 使用示例
evaluator = RAGEvaluator()
result = evaluator.evaluate_end_to_end(
queries=['什么是RAG?'],
answers=['RAG是检索增强生成技术'],
ground_truths=['检索增强生成是一种结合检索和生成的技术'],
retrieved_docs_list=[['RAG技术介绍', '其他文档']],
relevant_docs_list=[['RAG技术介绍']]
)
print(result)
系统优化策略:
- 文档处理优化:调整分块大小、尝试不同分块策略、优化元数据提取
- 检索优化:尝试不同嵌入模型、调整索引参数、使用混合检索
- 生成优化:优化提示模板、调整温度参数、使用更强大的模型
- Pipeline优化:添加重排序、使用上下文压缩、实现缓存机制
# 批量评估和优化示例
def optimize_chunk_size(documents, queries, ground_truths, chunk_sizes=[256, 512, 1024]):
"""优化分块大小"""
results = []
for chunk_size in chunk_sizes:
print(f"\n测试分块大小: {chunk_size}")
# 构建RAG系统
config = RAGConfig(chunk_size=chunk_size)
rag = RAGSystem(config)
# 使用内存中的文档
rag.embeddings = HuggingFaceEmbeddings(model_name=config.embedding_model)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
rag.vectorstore = FAISS.from_documents(chunks, rag.embeddings)
rag.retriever = rag.vectorstore.as_retriever(search_kwargs={"k": 5})
rag.qa_chain = rag._build_qa_chain()
# 评估
answers = []
retrieved_list = []
for query in queries:
result = rag.query(query)
answers.append(result['answer'])
retrieved_list.append([s['content'] for s in result['sources']])
# 计算指标
evaluator = RAGEvaluator()
metrics = evaluator.evaluate_end_to_end(
queries, answers, ground_truths, retrieved_list,
[[gt] for gt in ground_truths]
)
results.append({
'chunk_size': chunk_size,
'metrics': metrics
})
print(f"召回率: {metrics['retrieval']['avg_recall@k']:.3f}")
print(f"语义相似度: {metrics['generation']['avg_semantic_similarity']:.3f}")
# 选择最佳配置
best = max(results, key=lambda x: x['metrics']['retrieval']['avg_recall@k'])
print(f"\n最佳分块大小: {best['chunk_size']}")
return results
RAG技术正在快速发展,新的优化方法层出不穷。建议读者持续关注最新的研究进展,并根据实际业务需求选择合适的技术方案。通过系统化的评估和持续的迭代优化,可以构建出高质量的RAG应用,为企业创造实际价值。
时间分配建议
- 3h 文档处理:加载多种格式、分块策略对比
- 3h 向量检索:Embedding 模型选择、向量数据库操作、索引优化
- 2h 检索增强:混合检索、重排序、上下文压缩
- 2h 系统构建:LangChain/LlamaIndex 端到端 RAG Pipeline
- 1h 评估优化:RAGAS 评估、分块大小调优
里程碑(第 11-12 周联合)
构建个人知识库问答原型:选择一批个人文档(笔记、文章、技术文档), 搭建完整的 RAG 管道(文档加载 → 分块 → Embedding → 向量检索 → 重排序 → LLM 生成), 实现"基于个人文档的问答"功能,并使用 RAGAS 框架评估系统质量。
学完你应该能...
- 根据文档类型选择合适的切分策略(固定长度/递归/语义/结构切分)
- 选择合适的 Embedding 模型和向量数据库
- 实现混合检索(BM25 + 向量)+ Cross-Encoder 重排序
- 使用 LangChain 或 LlamaIndex 构建完整的 RAG Pipeline
- 使用 RAGAS 框架评估和优化 RAG 系统质量
- 处理多模态文档(表格提取、图像描述)