每周 6-10 小时
本周目标
将上周学到的 Transformer 理论落地。使用 Hugging Face 生态加载预训练的 BERT 模型, 在自己的数据集上进行微调。体验迁移学习的威力——用少量标注数据和极少的计算资源, 达到远超从零训练的效果。
10.1 预训练范式
10.1.1 预训练的起源与发展:从 Word2Vec 到 BERT
预训练(Pre-training)的概念并非源于 Transformer 时代,其思想可以追溯到词嵌入技术的发展。2013 年,Mikolov 等人提出的 Word2Vec 首次展示了通过大规模无监督语料学习词向量的可行性。Word2Vec 通过 Skip-gram 或 CBOW 架构,将词汇映射到低维连续向量空间,使得语义相似的词在向量空间中距离相近。
然而,Word2Vec 存在明显的局限性:每个词对应唯一的向量表示,无法处理一词多义现象。2018 年,ELMo(Embeddings from Language Models)通过双向 LSTM 架构,首次实现了基于上下文的动态词表示。同一词汇在不同语境下可获得不同的向量表示,这为多义词处理开辟了新路径。
同年,Google 发布的 BERT(Bidirectional Encoder Representations from Transformers)标志着预训练范式的重大突破。BERT 摒弃了传统的单向语言建模目标,引入掩码语言模型(Masked Language Modeling, MLM)任务,使模型能够同时利用左右两侧的上下文信息进行预测。这一设计使 BERT 在 GLUE 基准测试的 11 项任务中创下 9 项新纪录,开启了预训练模型的黄金时代。
GPT(Generative Pre-trained Transformer)系列则采用了不同的技术路线。OpenAI 从 2018 年开始发布 GPT 模型,坚持使用因果语言建模(Causal Language Modeling, CLM)的自回归生成方式。这种单向架构虽然在理解任务上略逊于 BERT,但在文本生成任务上展现出强大优势。GPT-3(2020 年)更是展示了惊人的少样本学习能力,证明了大规模预训练模型具备强大的泛化能力。
10.1.2 自监督学习目标:MLM、CLM、Span Corruption
自监督学习是预训练的核心机制,通过设计巧妙的预测任务,使模型能够从海量无标注文本中学习语言规律。当前主流的预训练目标包括三种范式:
掩码语言建模(MLM) 是 BERT 采用的核心策略。在输入序列中随机遮蔽 15% 的 token,模型需要根据上下文预测被遮蔽的原始词汇。具体实现中,被选中的 token 有 80% 的概率替换为 [MASK] 标记,10% 的概率替换为随机 token,10% 的概率保持不变。这种策略迫使模型深入理解双向上下文信息。MLM 的数学表达为:
其中 表示被遮蔽的位置集合, 表示除遮蔽位置外的所有 token。
因果语言建模(CLM) 是 GPT 系列采用的目标函数。模型按照从左到右的顺序依次预测下一个 token,每个位置的预测只能依赖于之前的 token。这种自回归特性使模型天然适合文本生成任务。CLM 的损失函数为:
跨度损坏(Span Corruption) 是 T5 模型提出的改进方案。不同于 MLM 遮蔽单个 token,Span Corruption 随机遮蔽连续的 token 片段(span),模型需要预测整个被遮蔽的 span 内容。这种方法更接近真实的序列到序列任务,使预训练与下游任务的差距更小。
| 预训练目标 | 代表模型 | 核心思想 | 优势 | 劣势 |
|---|---|---|---|---|
| MLM | BERT、RoBERTa | 双向预测遮蔽 token | 充分利用上下文 | 预训练-微调不一致 |
| CLM | GPT 系列、LLaMA | 自回归预测下一个 token | 生成能力强 | 仅利用单向上下文 |
| Span Corruption | T5、UL2 | 预测连续 token 片段 | 统一编码器-解码器 | 计算开销较大 |
上表对比了三种预训练目标的核心特点。实践中,Encoder-only 架构多采用 MLM,Decoder-only 架构采用 CLM,而 Encoder-Decoder 架构则可灵活采用 Span Corruption 或 Prefix LM 等变体。
10.1.3 预训练数据构建:语料收集、清洗、去重
预训练数据的质量直接决定了模型能力的上限。构建高质量预训练语料需要经过严格的收集、清洗和去重流程。
语料收集 阶段需要确保数据来源的多样性和规模。典型的预训练语料包括:网页文本(Common Crawl、C4)、书籍语料(BooksCorpus、Gutenberg)、百科知识(Wikipedia)、学术论文(arXiv、PubMed)以及代码数据(GitHub、StackOverflow)。LLaMA 2 的预训练数据包含 2 万亿 token,涵盖多种语言和领域。
数据清洗 是提升语料质量的关键环节。主要清洗策略包括:
- 质量过滤:使用启发式规则(如文档长度、标点符号比例、停用词比例)或训练质量分类器剔除低质量内容
- 去噪处理:移除 HTML 标签、URL、重复段落、乱码文本
- 敏感内容过滤:使用关键词列表或分类器识别并过滤不当内容
- 语言识别:使用 langdetect 等工具识别文档语言,按需求筛选特定语言
去重处理 对于防止模型记忆和过拟合至关重要。研究表明,训练数据中的重复内容会导致模型生成能力退化。常用去重方法包括:
- 精确去重:使用 MinHash、SimHash 等算法识别完全或近似的重复文档
- 子串去重:识别并移除跨文档的重复子串(如导航栏、版权声明)
- 训练时去重:在数据加载阶段动态去重,避免相同样本出现在同一 batch 中
10.1.4 预训练策略对比:Encoder-only、Decoder-only、Encoder-Decoder
基于 Transformer 的预训练模型可分为三种架构范式,各自适用于不同的应用场景。
Encoder-only 架构 以 BERT 为代表,采用双向注意力机制,每个 token 都能关注到序列中的所有其他 token。这种架构擅长理解任务,如文本分类、命名实体识别、问答等。RoBERTa、ALBERT、DeBERTa 等模型都在 BERT 基础上进行了改进。Encoder-only 模型的局限在于无法直接用于生成任务。
Decoder-only 架构 以 GPT 系列为代表,采用因果掩码确保每个 token 只能关注之前的 token。这种自回归特性使其天然适合文本生成任务。GPT-3、LLaMA、ChatGLM 等主流大模型都采用这一架构。Decoder-only 模型通过提示工程(Prompt Engineering)也能完成理解任务,展现了强大的通用性。
Encoder-Decoder 架构 以 T5、BART 为代表,结合了编码器和解码器的优势。编码器处理输入序列,解码器自回归生成输出。这种架构在序列到序列任务(如翻译、摘要)上表现优异。T5 将所有 NLP 任务统一为 text-to-text 格式,简化了模型设计和应用接口。
| 架构类型 | 代表模型 | 注意力机制 | 适用任务 | 典型应用场景 |
|---|---|---|---|---|
| Encoder-only | BERT、RoBERTa | 双向注意力 | 理解任务 | 分类、NER、抽取式 QA |
| Decoder-only | GPT、LLaMA | 因果注意力 | 生成任务 | 对话、写作、代码生成 |
| Encoder-Decoder | T5、BART | 编码器双向+解码器因果 | 序列转换 | 翻译、摘要、生成式 QA |
当前大语言模型的发展趋势显示,Decoder-only 架构因其简洁性和强大的涌现能力,已成为大规模预训练的主流选择。GPT-4、Claude、LLaMA 3 等顶级模型都采用这一架构。
10.2 大语言模型架构
10.2.1 GPT 系列模型演进:GPT-1/2/3/4 架构变化
GPT 系列的发展见证了大语言模型能力的跃迁。从 2018 年的 GPT-1 到 2024 年的 GPT-4o,每一代模型都在架构、规模和训练方法上实现了重要突破。
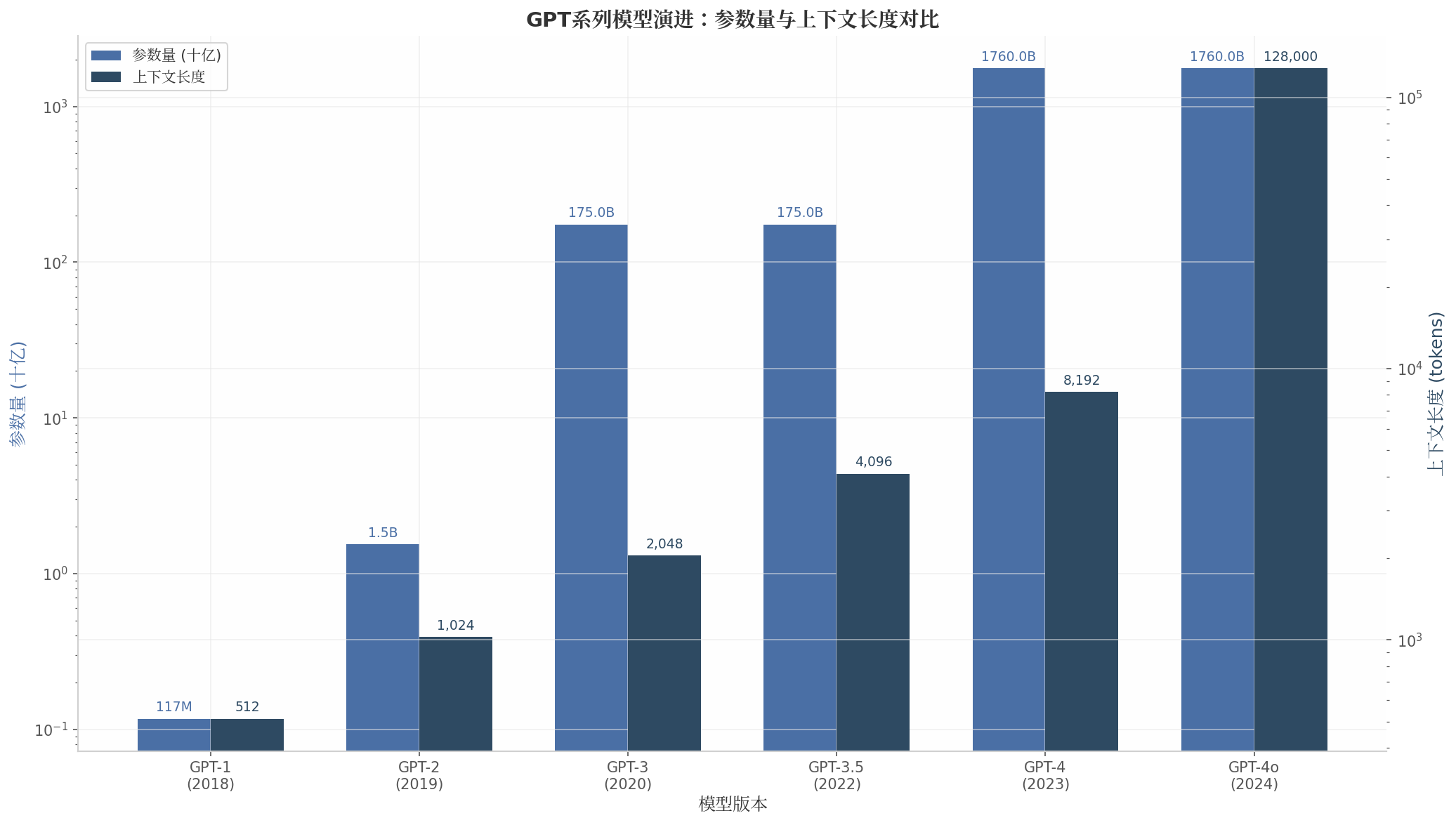
GPT-1(2018) 首次证明了生成式预训练的有效性。模型采用 12 层 Transformer 解码器,1.17 亿参数,在 BooksCorpus 数据集(约 8 亿词)上预训练。其核心创新是"预训练+微调"的两阶段范式:先在大规模无标注数据上预训练,再在下游任务上微调。
GPT-2(2019) 将规模扩大至 15 亿参数,在更大的 WebText 数据集(40GB 文本)上训练。研究发现,模型规模扩大带来了显著的零样本(zero-shot)学习能力,即无需微调即可执行部分下游任务。这一发现为后续研究指明了方向。
GPT-3(2020) 是规模革命的里程碑,参数激增至 1750 亿。通过扩大模型和数据规模,GPT-3 展现出强大的上下文学习(In-context Learning)能力:只需在输入中提供几个示例,模型就能理解任务要求并生成合适的输出。这种能力被称为"少样本学习"(Few-shot Learning)。
GPT-4(2023) 引入了多模态能力,能够处理图像和文本输入。虽然 OpenAI 未公开具体架构细节,但据估计其参数规模可能达到 1.76 万亿。GPT-4 在各类专业和学术基准上接近人类水平,标志着大模型能力的新高度。
| 模型 | 发布时间 | 参数量 | 上下文长度 | 核心创新 |
|---|---|---|---|---|
| GPT-1 | 2018.06 | 117M | 512 | 生成式预训练 |
| GPT-2 | 2019.02 | 1.5B | 1024 | 零样本学习能力 |
| GPT-3 | 2020.05 | 175B | 2048 | 上下文学习、少样本学习 |
| GPT-3.5 | 2022.11 | 175B | 4096 | 指令微调、RLHF |
| GPT-4 | 2023.03 | ~1.76T | 8192 | 多模态、更强推理 |
| GPT-4o | 2024.05 | ~1.76T | 128K | 原生多模态、更快响应 |
上表总结了 GPT 系列的关键演进。从 GPT-1 到 GPT-4o,参数量增长了约 15000 倍,上下文长度扩展了 250 倍。这种规模扩展带来了模型能力的质变,从需要微调的专用模型进化为通用任务求解器。
10.2.2 LLaMA 与开源模型:开源生态、模型权重
2023 年,Meta 发布的 LLaMA(Large Language Model Meta AI)系列开启了开源大模型的黄金时代。与 GPT 系列的闭源策略不同,LLaMA 向研究社区开放了模型权重,极大地推动了学术界和工业界的创新。
LLaMA 1 发布了 7B、13B、33B、65B 四个版本,在 1.4 万亿 token 上训练。其设计原则是:在有限的推理预算下实现最佳性能。通过使用更多的训练 token 而非更大的模型,LLaMA 在多项基准上超越了 GPT-3,尽管参数量更小。
LLaMA 2 于 2023 年 7 月发布,包含 7B、13B、34B、70B 四个版本。主要改进包括:
- 训练数据扩大至 2 万亿 token
- 上下文长度从 2048 扩展到 4096
- 引入分组查询注意力(Grouped-Query Attention, GQA)加速推理
- 发布专门的对话优化版本 LLaMA 2 Chat
LLaMA 3 在 2024 年发布,进一步提升了开源模型的能力上限。8B 和 70B 版本在多项基准上超越了同等规模的闭源模型。关键改进包括:扩展的 tokenizer 词汇表(从 32K 到 128K)、改进的 GQA 实现、以及更高质量的多语言训练数据。
开源生态的繁荣催生了众多衍生模型:
- Alpaca:斯坦福大学基于 LLaMA 7B,使用 GPT-3.5 生成的 52K 指令数据微调
- Vicuna:UC Berkeley 使用用户分享的对话数据微调 LLaMA
- WizardLM:使用 AI 生成的复杂指令数据训练
- Code LLaMA:专门针对代码任务优化的版本
这些开源模型使研究者和开发者能够在本地部署和定制大模型,降低了对商业 API 的依赖,促进了 AI 技术的民主化。
10.2.3 多语言与代码模型:多语言能力、代码生成
大语言模型的能力不仅限于英语,多语言模型和代码专用模型已成为重要的研究方向。
多语言模型 通过混合多语言语料训练,获得了跨语言理解和生成能力。代表性模型包括:
- XLM-R:基于 RoBERTa 的多语言版本,支持 100 种语言
- mT5:多语言 T5,在 101 种语言的网页文本上预训练
- BLOOM:BigScience 项目发布的 176B 多语言模型,支持 46 种语言和 13 种编程语言
- Qwen:阿里巴巴发布的双语模型,在中英文任务上表现优异
多语言模型的关键挑战是处理不同语言之间的资源不平衡。英语数据通常占主导地位,低资源语言的训练数据有限。研究者采用跨语言迁移学习(Cross-lingual Transfer)技术,利用高资源语言的知识提升低资源语言的性能。
代码模型 专门针对编程任务优化,在代码生成、代码补全、bug 修复等任务上展现出强大能力。代表性模型包括:
- Codex:OpenAI 基于 GPT 架构训练的代码模型,为 GitHub Copilot 提供支持
- Code LLaMA:Meta 发布的代码专用模型,支持多种编程语言
- StarCoder:HuggingFace 和 ServiceNow 合作开发的 15.5B 代码模型
- DeepSeek-Coder:深度求索发布的代码模型,在多项代码基准上表现优异
代码模型的训练数据主要来自 GitHub、StackOverflow 等平台的公开代码。研究表明,在代码数据上预训练不仅能提升代码能力,还能增强模型的推理能力——这可能是因为代码具有严格的逻辑结构和执行语义。
10.2.4 模型规模与能力:Scaling Law、涌现能力
大语言模型的发展揭示了一个重要规律:模型能力随规模增长呈现可预测的幂律关系,同时在特定规模阈值会出现"涌现能力"。
Scaling Law(缩放定律) 描述了模型性能与计算量、参数量、数据量之间的关系。Kaplan 等人(2020)的研究发现,测试损失(test loss)与模型规模呈幂律关系:
其中 是损失, 是参数量, 和 是拟合参数。这一规律表明,在固定计算预算下,存在一个最优的模型规模-数据量配比。Chinchilla 研究进一步发现,当前许多模型训练不足,应该在更多数据上训练更小的模型以获得更优性能。
涌现能力(Emergent Abilities) 是指模型在达到一定规模后突然展现出的新能力。这些能力在小规模模型中不存在,只有当模型超过特定参数阈值时才会出现。典型的涌现能力包括:
- 上下文学习:从提示中的示例学习新任务
- 指令遵循:理解并执行自然语言指令
- 思维链推理:通过中间推理步骤解决复杂问题
- 多步算术:执行多步数学计算
涌现能力的出现机制仍是开放的研究问题。一种解释是,这些能力实际上在小模型中也存在,只是表现较弱难以测量;另一种观点认为,大规模模型确实学会了新的推理策略。
理解 Scaling Law 和涌现能力对于模型开发具有重要意义:
- 资源规划:根据目标性能预测所需的计算资源
- 架构选择:在模型规模与训练数据之间寻求最优平衡
- 能力预测:预判模型可能具备的能力边界
- 安全考量:提前识别可能涌现的风险能力
10.3 微调技术
10.3.1 全参数微调:SFT 流程、超参数设置
监督微调(Supervised Fine-Tuning, SFT)是将预训练模型适配到特定下游任务的标准方法。SFT 在预训练权重的基础上,使用标注数据继续训练模型全部参数。
SFT 标准流程 包含以下步骤:
- 数据准备:收集并清洗任务相关的标注数据,格式化为指令-输出对
- 数据分割:将数据划分为训练集、验证集和测试集(典型比例为 8:1:1)
- 超参数配置:设置学习率、batch size、训练轮数等关键参数
- 模型训练:使用梯度下降优化模型参数
- 验证评估:在验证集上监控性能,实施早停防止过拟合
- 测试评估:在独立测试集上评估最终性能
关键超参数设置:
| 超参数 | 典型值 | 说明 |
|---|---|---|
| 学习率 | 1e-5 ~ 5e-5 | 通常比预训练小 10-100 倍 |
| Batch size | 16 ~ 128 | 受显存限制,可使用梯度累积 |
| 训练轮数 | 3 ~ 10 | 根据数据量和过拟合情况调整 |
| 序列长度 | 512 ~ 4096 | 根据任务需求设置 |
| Warmup 比例 | 0.1 ~ 0.2 | 学习率预热步数占比 |
| 权重衰减 | 0.01 ~ 0.1 | L2 正则化系数 |
全参数微调的主要挑战是计算资源需求。以 LLaMA-2-70B 为例,全参数微调需要约 140GB 显存(FP16 精度),远超单卡容量。解决方案包括:
- 数据并行:将 batch 分割到多个 GPU
- 模型并行:将模型层分割到多个 GPU
- ZeRO 优化:DeepSpeed 的内存优化技术
- 梯度检查点:以计算换内存,减少激活值存储
10.3.2 提示学习与上下文学习:In-context Learning
上下文学习(In-context Learning, ICL)是大语言模型最引人注目的能力之一。与传统微调不同,ICL 无需更新模型参数,仅通过在输入提示中提供示例即可让模型学习新任务。
ICL 的基本形式 是在提示中包含任务描述和若干示例(demonstrations):
任务:将英文翻译成中文
英文:Hello, how are you?
中文:你好,你好吗?
英文:What is your name?
中文:你叫什么名字?
英文:Nice to meet you.
中文:
模型从示例中学习任务模式,生成符合要求的输出。研究表明,示例的数量、顺序、质量都会影响 ICL 的性能。
提示工程(Prompt Engineering) 是优化 ICL 效果的关键技术。常用策略包括:
- 零样本提示:直接描述任务,不提供示例
- 少样本提示:提供 2-10 个代表性示例
- 思维链提示:在示例中加入推理过程,引导模型逐步思考
- 角色扮演:设定模型的角色身份,引导输出风格
提示微调(Prompt Tuning) 是介于 ICL 和全参数微调之间的轻量级方法。它在输入嵌入层添加可学习的"软提示"(soft prompts),冻结预训练模型的其他参数。相比硬编码的文本提示,软提示可以通过梯度优化自动学习最优表示。
提示微调的优势在于:
- 每个任务仅需学习少量参数(通常几千个)
- 多任务切换只需更换提示向量
- 避免了全参数微调的灾难性遗忘问题
10.3.3 LoRA 与参数高效微调:低秩适应原理
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)旨在减少微调时的可训练参数量,同时保持接近全参数微调的性能。低秩适应(Low-Rank Adaptation, LoRA)是其中最成功的方法之一。
LoRA 核心思想 由 Hu 等人(2021)提出,其核心洞见是:模型适应过程中的权重更新具有低秩特性。具体而言,对于预训练权重矩阵 ,微调时的更新可以表示为低秩分解:
其中 ,, 是秩参数。训练时冻结 ,仅优化 和 。
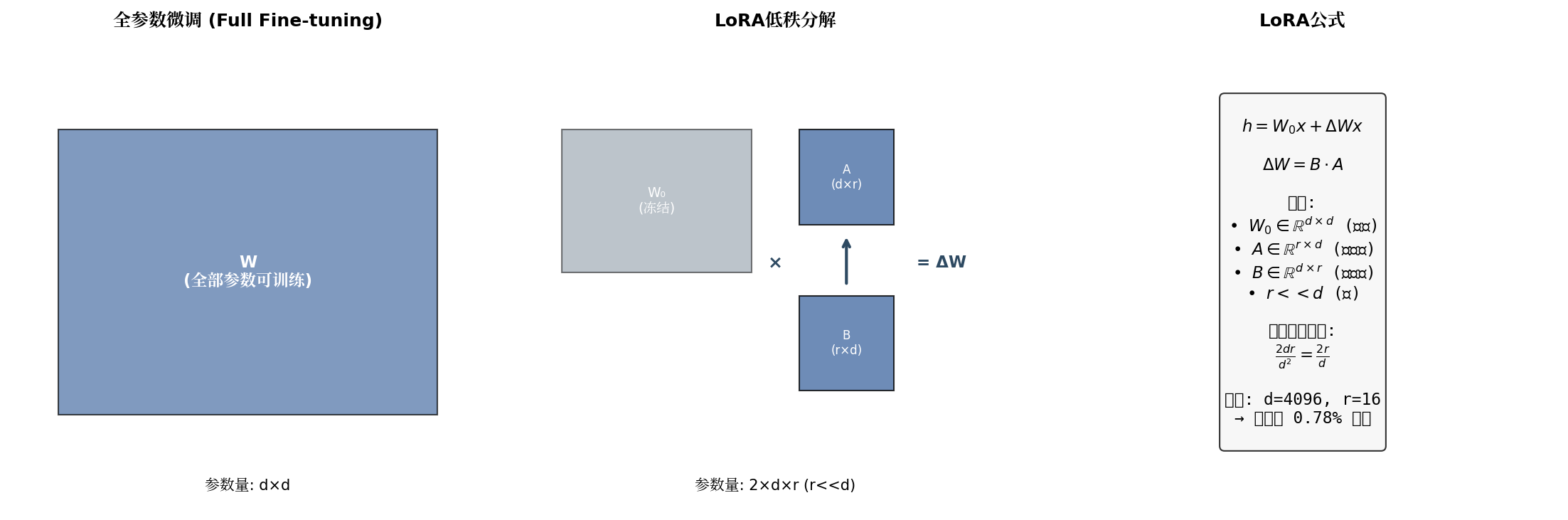
上图展示了 LoRA 与全参数微调的对比。全参数微调需要更新 个参数,而 LoRA 仅需训练 个参数。当 , 时,LoRA 仅需训练约 0.78% 的参数。
LoRA 的关键优势:
- 参数效率:大幅减少可训练参数量,降低显存和存储需求
- 推理效率:训练后的低秩矩阵可与原权重合并,不增加推理延迟
- 模块化:不同任务的 LoRA 权重可以独立存储和切换
- 不损失预训练知识:冻结原权重保留了预训练获得的通用能力
LoRA 的变体与扩展:
- AdaLoRA:动态分配不同层的秩预算,根据重要性自适应调整
- QLoRA:结合 4-bit 量化和 LoRA,实现单卡微调 65B 模型
- DoRA:权重分解低秩适应,将权重分解为幅度和方向分别适应
- LoRA-FA:冻结 A 矩阵随机初始化,仅训练 B 矩阵
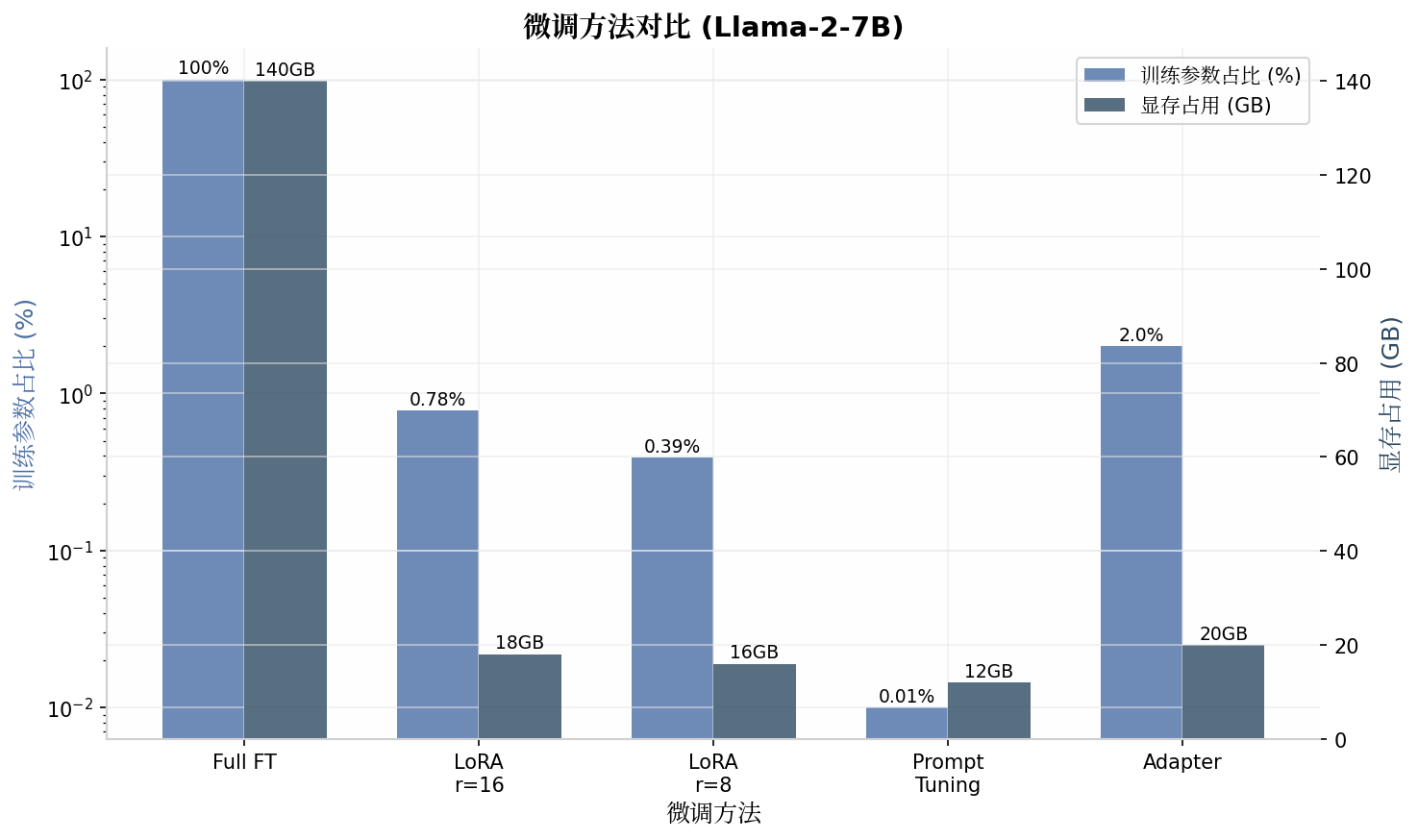
上图对比了不同微调方法的训练参数占比和显存占用。LoRA 在保持较高性能的同时,将显存需求从 140GB 降低到 16-18GB,使消费级 GPU 也能微调大模型。
10.3.4 指令微调与对齐:Instruction Tuning、RLHF
预训练模型虽然具备强大的语言能力,但并不能直接遵循人类指令或符合人类偏好。指令微调(Instruction Tuning)和基于人类反馈的强化学习(RLHF)是使模型与人类意图对齐的关键技术。
指令微调 使用格式化的指令-响应对训练模型,使其学会理解和执行各类指令。指令数据通常包含以下组件:
- 任务描述:说明需要完成的任务
- 输入内容:任务的具体输入
- 期望输出:符合要求的响应
高质量的指令数据是指令微调成功的关键。开源指令数据集包括:
- Alpaca:52K 条由 GPT-3.5 生成的指令数据
- Dolly:15K 条人工编写的指令数据
- ShareGPT:用户分享的 ChatGPT 对话数据
- FLAN:Google 整理的指令微调集合
RLHF(Reinforcement Learning from Human Feedback) 进一步提升了模型与人类偏好的对齐程度。RLHF 包含三个阶段:
- 监督微调(SFT):使用高质量指令数据微调预训练模型
- 奖励模型训练:收集人类对模型输出的偏好比较,训练奖励模型 预测人类偏好
- 强化学习优化:使用 PPO 等算法优化策略模型,最大化奖励模型的评分
RLHF 的目标函数为:
其中第二项是 KL 散度约束,防止优化后的策略偏离参考策略太远。
RLHF 的替代方案:
- DPO(Direct Preference Optimization):直接从偏好数据优化,无需显式训练奖励模型
- KTO(Kahneman-Tversky Optimization):基于人类偏好的二元反馈进行优化
- RLAIF:使用 AI 反馈替代人类反馈,降低标注成本
10.5 微调实践
10.5.1 Hugging Face 生态:Transformers、Datasets、PEFT
Hugging Face 提供了最完善的大语言模型开发生态,包括 Transformers、Datasets、PEFT 等核心库。
Transformers 是 HuggingFace 的旗舰库,提供了:
- 预训练模型的统一接口(AutoModel、AutoTokenizer)
- 主流架构的实现(BERT、GPT、T5、LLaMA 等)
- 训练和推理的高层 API(Trainer、Pipeline)
- 模型 Hub:托管超过 50 万个模型
Datasets 库简化了数据加载和处理:
- 支持数百个公开数据集的一行加载
- 高效的数据预处理(map、filter、shuffle)
- 与 Transformers 无缝集成
- 支持大规模数据集的流式加载
PEFT(Parameter-Efficient Fine-Tuning) 库实现了多种参数高效微调方法:
- LoRA/AdaLoRA/QLoRA
- Prefix Tuning/P-Tuning
- Prompt Tuning
- IA3
安装这些库非常简单:
pip install transformers datasets peft accelerate bitsandbytes
10.5.2 数据集准备与处理:格式转换、tokenization
高质量的数据准备是微调成功的关键。以下是标准的数据处理流程。
数据格式:指令微调数据通常采用以下 JSON 格式:
{
"instruction": "将以下英文翻译成中文",
"input": "Hello, world!",
"output": "你好,世界!"
}
或使用对话格式:
{
"messages": [
{"role": "system", "content": "你是一个 helpful 的助手"},
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!有什么我可以帮助你的吗?"}
]
}
数据加载与处理:
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("json", data_files="data.jsonl")
# 数据预处理
def format_example(example):
if example["input"]:
prompt = f"### Instruction:\n{example['instruction']}\n\n### Input:\n{example['input']}\n\n### Response:\n"
else:
prompt = f"### Instruction:\n{example['instruction']}\n\n### Response:\n"
return {
"prompt": prompt,
"completion": example["output"]
}
dataset = dataset.map(format_example)
Tokenization 处理:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer.pad_token = tokenizer.eos_token # 设置 padding token
def tokenize_function(examples):
# 合并 prompt 和 completion
texts = [p + c for p, c in zip(examples["prompt"], examples["completion"])]
# Tokenize
result = tokenizer(
texts,
truncation=True,
max_length=512,
padding="max_length",
)
# 创建 labels(prompt 部分 mask 为 -100)
prompt_lengths = [len(tokenizer(p)["input_ids"]) for p in examples["prompt"]]
result["labels"] = [
[-100] * pl + result["input_ids"][i][pl:]
for i, pl in enumerate(prompt_lengths)
]
return result
tokenized_dataset = dataset.map(tokenize_function, batched=True)
10.5.3 完整微调流程:从数据到模型
下面展示使用 HuggingFace PEFT 进行 LoRA 微调的完整流程。
1. 导入依赖并加载模型:
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from datasets import load_dataset
# 加载模型和 tokenizer
model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# 4-bit 量化加载(节省显存)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
# 准备模型用于训练
model = prepare_model_for_kbit_training(model)
2. 配置 LoRA:
# LoRA 配置
lora_config = LoraConfig(
r=16, # 秩
lora_alpha=32, # 缩放参数
target_modules=[ # 应用 LoRA 的模块
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_dropout=0.05, # Dropout 率
bias="none",
task_type="CAUSAL_LM",
)
# 应用 LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出: trainable params: 33,554,432 || all params: 6,771,970,048 || trainable%: 0.4955
3. 准备数据集:
# 加载数据集
dataset = load_dataset("tatsu-lab/alpaca", split="train")
# 格式化函数
def format_prompt(example):
if example["input"]:
text = f"### Instruction:\n{example['instruction']}\n\n### Input:\n{example['input']}\n\n### Response:\n{example['output']}"
else:
text = f"### Instruction:\n{example['instruction']}\n\n### Response:\n{example['output']}"
return {"text": text}
dataset = dataset.map(format_prompt)
# Tokenize
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding="max_length",
)
tokenized_dataset = dataset.map(tokenize_function, batched=True, remove_columns=dataset.column_names)
4. 配置训练参数并训练:
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
weight_decay=0.001,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
logging_steps=10,
save_strategy="epoch",
fp16=True,
optim="paged_adamw_8bit",
)
# 数据整理器
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
# 创建 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator,
)
# 开始训练
trainer.train()
5. 保存和加载 LoRA 权重:
# 保存 LoRA 权重
model.save_pretrained("./lora_weights")
# 加载 LoRA 权重进行推理
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(model_name)
model = PeftModel.from_pretrained(base_model, "./lora_weights")
model = model.merge_and_unload() # 合并权重(可选)
# 推理
inputs = tokenizer("### Instruction:\n解释什么是机器学习\n\n### Response:\n", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=256, temperature=0.7)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
6. 使用 TRL 库进行更简洁的训练:
HuggingFace 的 TRL(Transformer Reinforcement Learning)库提供了更高级的微调接口:
from trl import SFTTrainer
# SFTTrainer 自动处理数据格式
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
args=TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=2e-4,
),
)
trainer.train()
以上代码展示了从数据准备到模型训练的完整流程。通过 PEFT 和量化技术,即使是消费级 GPU(如 RTX 4090 24GB)也能微调 7B-13B 规模的大语言模型。对于更大规模的模型,可以使用 DeepSpeed ZeRO-3 或 FSDP 等技术实现多卡并行训练。